もっとGroongaを知ってもらおう!ということで週刊Groongaをはじめました。毎週木曜にGroongaやMroonga、Rroongaのトピックを投稿予定です。
今年も11/29に全文検索エンジンGroongaを囲む夕べ4を開催しました。発表資料へのリンクもまとめています。隔週連載Groongaも参考になりますよ。
はじめに
オープンソースのカラムストア機能付き全文検索エンジンGroongaを公開しています。最新のバージョンは2013年11月29日にリリースした3.1.0です。
今回は、3.1.0に追加された、データベースの肥大化を防ぐ方法を紹介します。
どうしてデータベースの肥大化が発生するのか
全文検索エンジンであるGroongaでは、これまで可変長カラムの値を更新しつづけると(全く同じ値で更新した場合でも都度領域を消費していくので)データベースが徐々に肥大していく問題がありました。
これは(詳細を割愛して説明すると)参照ロックフリーで高速に検索しつつ、アトミックに更新するために都度値をコピーしてから参照先のポインタを差し替えるような振舞いで実現していることに由来します。
データベースの肥大化を防ぐための設定
3.1.0では実験的にその問題の解決するためのオプションとして、設定変更でデータベースを肥大化させにくくするためのオプションが追加されました。
それが、GRN_GRN_JA_SKIP_SAME_VALUE_PUTという環境変数です。
内容が同じならこれまでやっていた都度コピーされないようにすれば良いという発想です。
GRN_GRN_JA_SKIP_SAME_VALUE_PUT を試してみる
では、実際に試してみましょう。
まずは、小さなサンプルを用意してその効果を確認してみましょう。
そのためのスキーマ定義は次の通りです。
table_create Users TABLE_HASH_KEY UInt32
table_create FirstNames TABLE_HASH_KEY ShortText
table_create LastNames TABLE_HASH_KEY ShortText
table_create Curry TABLE_HASH_KEY ShortText
column_create Users full_name COLUMN_SCALAR ShortText
column_create Users first_name COLUMN_SCALAR FirstNames
column_create Users last_name COLUMN_SCALAR LastNames
column_create Users email COLUMN_VECTOR ShortText
column_create Users note COLUMN_SCALAR Curry
column_create FirstNames first_index COLUMN_INDEX Users first_name
column_create LastNames last_index COLUMN_INDEX Users last_name
column_create Curry curry_index COLUMN_INDEX Users note
そして、次のようなテストデータを5000件ほど用意しました。
load --table Users
[
{"_key":1, "full_name":"荒井 知世", "first_name":"知世", "last_name":"荒井", "email":["arai_chise@example.com"], "note":"左ルー・ナン派"},
{"_key":2, "full_name":"吹越 知世", "first_name":"知世", "last_name":"吹越", "email":["fukikoshi_chise@example.com"], "note":"右ルー・混ぜ混ぜ派"},
{"_key":3, "full_name":"竹中 裕司", "first_name":"裕司", "last_name":"竹中", "email":["takenaka_yuuji@example.com"], "note":"左ルー・混ぜ混ぜ派"},
{"_key":4, "full_name":"川上 一徳", "first_name":"一徳", "last_name":"川上", "email":["kawakami_ittoku@example.com"], "note":"左ルー・ルー攻め派"},
{"_key":5, "full_name":"菅原 美里", "first_name":"美里", "last_name":"菅原", "email":["sugawara_miri@example.com"], "note":"別盛り・せき止め派"},
{"_key":6, "full_name":"丸田 光", "first_name":"光", "last_name":"丸田", "email":["maruta_hikaru@example.com"], "note":"右ルー・ルー攻め派"},
{"_key":7, "full_name":"長島 美幸", "first_name":"美幸", "last_name":"長島", "email":["nagashima_miyuki@example.com"], "note":"左ルー・別口派"},
{"_key":8, "full_name":"石田 まなみ", "first_name":"まなみ", "last_name":"石田", "email":["ishida_manami@example.com"], "note":"ぶっかけ・ナン派"},
{"_key":9, "full_name":"北川 聖陽", "first_name":"聖陽", "last_name":"北川", "email":["kitakawa_masaaki@example.com"], "note":"ぶっかけ・ルー攻め派"},
{"_key":10, "full_name":"真矢 竜次", "first_name":"竜次", "last_name":"真矢", "email":["maya_ryuuji@example.com"], "note":"右ルー・別口派"},
...
そして、シェルスクリプトでひたすら上記のデータを200回ほどロードしてみました。
その際は初期状態のデータベースから、順次データをロードしていってサイズの変化傾向を確認してみました。
同じデータを何度でもロードしているという、とても極端な前提であることに注意してください。
| 更新回数 | スキップなし(MB) | スキップあり(MB) |
|---|---|---|
| 1 | 1.7 | 1.7 |
| 20 | 8.9 | 8.2 |
| 40 | 11 | 9 |
| 60 | 12 | 9.8 |
| 80 | 14 | 11 |
| 100 | 15 | 12 |
| 120 | 16 | 12 |
| 140 | 17 | 12 |
| 160 | 17 | 12 |
| 180 | 17 | 13 |
| 200 | 17 | 13 |
これをグラフにしてみるとこんな感じになります。
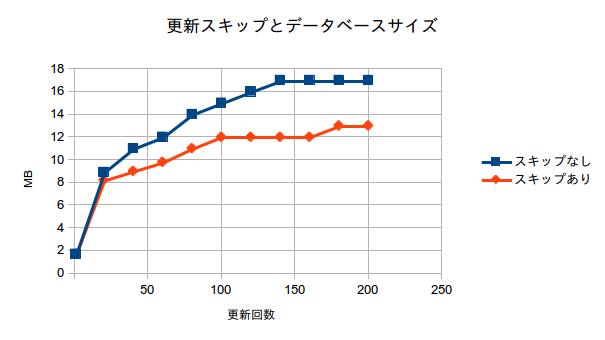
スキップしない従来の挙動では、初期状態で1.7Mほどだったのが、最終的には17MBほどまで肥大化しました。GRN_GRN_JA_SKIP_SAME_VALUE_PUTを設定した状態で同様にすると、最終的に13MBほどで落ちつきました。上記は極端なケースではあるものの有意な効果があることがわかります。
まとめ
今回は、データベースの肥大化を防ぐ方法を紹介しました。
この機能はまだ実験的な扱いとなっています。必ずしもすべてのケースに有効とは限らないためです。
とはいえ、データベースの肥大化が顕著でどうにかしたい場合には選択肢のひとつにはなるのではないでしょうか。
Groongaに興味を持ったなら、まずはインストールして試してみてください。
Groongaの基本的な動作を知るためのチュートリアルもあります。インストールしたら試してみてください。