Chainer Advent Calendar 2016の21日目の記事です.
概要
去年の秋から今年の春にかけて精力的にやっていた加速度信号からの人間行動認識のなかで、Chainerを用いてRNN(LSTM)を構築したのでここで晒します.
といっても基本的にexamplesに収録されてる"ptb"をベースにちょこっと改造を施しただけでプログラミング的には大したことやってないです
これやり始めた頃はPythonでプログラミングするのも初心者丸出し的存在で、書いたソースコードもかなり汚く読みづらかったのでリファインしていくらか見れる状態に直しました.(それでも汚い…)
また、ある程度出来上がってまわしてたときのChainerバージョンはまだ1.6とかでしたので、コードの中には古い記法がかなり混じっているしれません!!ご注意ください
(記事にするにあたって一応バージョン1.18.0で動くか確認は行っています)
コードの全文はここに置きました.
動作確認環境
Ubuntu14.04LTS
Python2.7.12 (anaconda2-4.1.1)
Chainer1.18.0
CUDA7.5
cudnn v4
問題設定
スマホの3軸加速度センサの信号から人間行動を推定する多クラス分類を行います.
人間行動認識(Human Activity Recognition:HAR)のコミュニティーでも深層学習の流行りの波は顕著で、現在かなり盛んに研究されているようですが、私がやりだしたとき大半はCNNを利用したもので、RNNはまだガンガン持ち上げられてはいませんでした.(今はけっこう使われています{これとか})
SVMや決定木を用いるような伝統的機械学習手法やCNNでは、時系列情報を処理するのに普通はタイムウインドウを設け信号を一定の時間でまとめて入力するといったやり方を用います.しかし、これではダイナミクスを完全に考慮できません.そこで、RNNを使えばもっといいかんじにできるんじゃね?ってなったのが事のおこりです.
データセット
HASC
データセットにはHuman Activity Sensing Consortium(HASC)という組織が収集・公開しているコーパスを利用しました{公式サイト}.このコーパスは名古屋大学の先生らが中心となって整備しているもので,最新のものはかなり膨大なデータ量を誇ります.ここでは、そのミニセットであるSample Data Project収録の加速度信号データを用います.このページの最下部から入手することができます.
ダウンロードして解凍すると"HascToolDataPrj"というディレクトリがでてきます.さらに,その中に"SampleData"というディレクトリがあり,ここに利用するcsv形式の加速度信号データが全て収められています.
データは大きく"セグメンテッドデータ"と"シーケンスデータ"に分けられます.セグメンテッドデータは1種類の行動だけを記録しています.一方,シーケンスデータは全種類の行動を続けざまに行って計測を行なっています.ここで,私は学習に用いるべきはセグメンテッドデータであると考えました.セグメンテッドデータは計測毎にファイルを成しているので,圧倒的に教師ラベルを付与しやすいからです.ということで,セグメンテッドデータの4/5を訓練データ,1/5をテストデータにすることとします.
※ところで、使ってみてわかったのですがシーケンスデータのうち"person101"のものは一部軸が入れ替わってる(スマホの方向間違ってる?)可能性があります
整形
HASCのデータを以下の3つに分けました.
-
訓練データ(セグメンテッドデータの一部)
重みの更新に用いる -
テストデータ(訓練データに使われなかったセグメンテッドデータ)
学習中の汎化性能を確認するのに用いる -
シーケンスデータ
学習後により実践的なテストを行うのに用いる
データを整形しChainerのモデルに渡すためにこんなソースコードを書きました.このスクリプトが一番晒すのが恥ずかしいですね….すごいアホっぽいコーディングになっていて分かりづらいと思いますが要するにこんなことをしています.
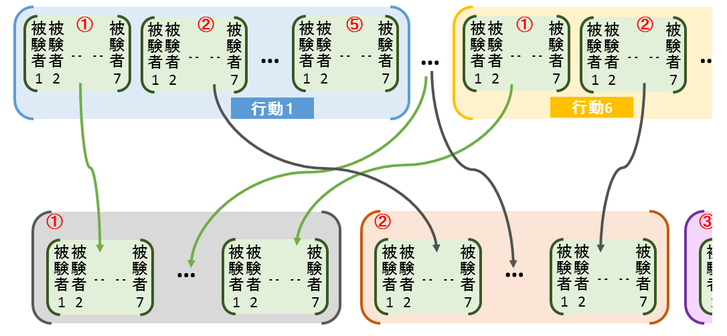
テストデータと訓練データを成すサンプルに被験者や行動ラベルに偏りが無いように5分割してるんですね.これは,実はちょっとずるいやり方です.本来なら無作為に分けるべきかもしれません.しかし、今回使うデータセットはサンプル数があまり多くないため少しのデータの偏りが結果にかなり影響するのではと思ってこんな風にしました.
※ちなみにシーケンスとセグメンテッドデータはあらかじめ"SampleData_sequence"と"SampleData_non_sequence"のふたつのディレクトリに分けなおして配置してます.その作業とかデータのダウンロードとかやる用のスクリプトも書いてるので取り敢えず試してみたい人はそれを使ってください.
ネットワークモデル
三軸加速度に対応する三次元の入力層と六行動に対応する六次元の出力層の間に多次元の中間層(LSTM)が三層結合したかなりシンプルなネットワークを用います.
中間層の数はいくつか試したりしましたが結果的に三層に落ち着きました.
import chainer
import chainer.functions as F
import chainer.links as L
class DRNN(chainer.Chain):
def __init__(self, in_s, n_units,out_s, train=True):
super(DRNN, self).__init__(
l1=L.LSTM(in_s, n_units),
l2=L.LSTM(n_units, n_units),
l3=L.LSTM(n_units, n_units),
l4=L.Linear(n_units, out_s),
)
self.train = train
def reset_state(self):
self.l1.reset_state()
self.l2.reset_state()
self.l3.reset_state()
def __call__(self, x):
h1 = self.l1(x)
h2 = self.l2(F.dropout(h1, train=self.train))
h3 = self.l3(F.dropout(h2, train=self.train))
y = self.l4(F.dropout(h3, train=self.train))
return y
LSTMにおいてはドロップアウトしないほうがいい結果が出るとの報告もありますが、私の場合ドロップアウトさせたほうが正解率少し高くなった印象でした.
学習
最適化の設定とか
# Prepare dataset
x_train, x_test, t_train, t_test= mkd.mkf(args.cross_n)
jamp = len(x_train)/batchsize
if not len(x_train)%batchsize == 0:
jamp = len(x_train)//batchsize + 1#1エポックあたりこの回数回るよ(訓練データを全部舐めまわすイメージ)
net = network.DRNN(3, n_units, 6)
model = L.Classifier(net)
model.compute_accuracy = True
for param in model.params():
data = param.data
data[:] = np.random.uniform(-0.1, 0.1, data.shape)
if args.gpu >= 0:
cuda.get_device(args.gpu).use()
model.to_gpu()
## Setup optimizer
optimizer = optimizers.Adam()
optimizer.setup(model)
optimizer.add_hook(chainer.optimizer.GradientClipping(grad_clip))# 勾配爆発を抑制
メインループ
Trainerは使っていません.(現在勉強中なのでいつか書きなおしたい)
また,訓練データの時系列長は一つひとつ微妙に違うのでミニバッチでぶっこむには少し工夫が必要です.ここでは,ある一定ステップ数を決めてその長さに統一し,入力を開始する時刻をミニバッチ毎に毎回ランダムに決めるという方法をとっています.この辺もあんまりスマートじゃないですね.最近Chainerに追加されたNstepLSTMの機能を使えばキレイに書けるのかな?
for n in range(n_epoch):
t_loss = 0
t_loss_e = 0
acu = 0
acu_e = 0
print("epoch {}".format(n))
e_state_t = time.time()
ran_tr = range(len(x_train))#訓練データシャッフル
r_train_list = []
r_train_label = []
for t in ran_tr:
r_train_list.append(x_train[t])
r_train_label.append(t_train[t])
x_train = r_train_list
t_train = r_train_label
for b,p in enumerate(range(jamp)):
print("e{}_b{}".format(n,b))
lool = []
for jj in range(batchsize):
lool.append((p*batchsize+jj)%len(x_train))
accum_loss = 0
z =[]
for l in lool:#信号ぶっこむ最初の時刻をランダムで決めるその際はみ出さんようにする処理
z.append(x_train[l].shape[0])
len_t = min(z)
l_max = len_t - (len_sign+1)
r_l = random.randint(0,l_max)
aaa = range(r_l,r_l+len_sign)
sum_accuracy = 0
for e ,v in enumerate(aaa):
tra_x = []
tes_t = []
for q in lool:
tra_x.append(x_train[q][v])
tes_t.append(t_train[q])
x = chainer.Variable(xp.asarray(tra_x, dtype=np.float32))
t = chainer.Variable(xp.asarray(tes_t,dtype=np.int32))
loss_i = model(x, t)
accum_loss += loss_i
cur_log_perp += loss_i.data
sum_accuracy += float(model.accuracy.data)
if (e + 1) % bprop_len == 0: # Run truncated BPTT
model.zerograds()
accum_loss.backward()
accum_loss.unchain_backward() # truncate
accum_loss = 0
optimizer.update()
特徴量でなく,生の加速度を使って学習できるのも深層学習の為せる技です.
1エポックの学習の後に毎回テストをしてますがここでは割愛します.
結果
色々試したところ、ユニット数は60、ドロップアウトレートは0.5、truncated BPTTの間隔は30ぐらいにしとくのがベストでした.
この時の学習の様子はこんなかんじです.ちなみに100エポック回すのに3時間ぐらいかかってます.

エポックが進む毎に正解率が上がっていきます.テストデータで最大95%、シーケンスデータで最大83%程の正解率となりました.
この学習モデルでためしにシーケンスデータに対する推定を可視化するとこんなふうになります.波形の下に2つのバーで正解ラベルと推定ラベルを表示してます.また、横軸のタイムステップはセンサのサンプリング周期が100Hzなので、1ステップ10[ms]になります.
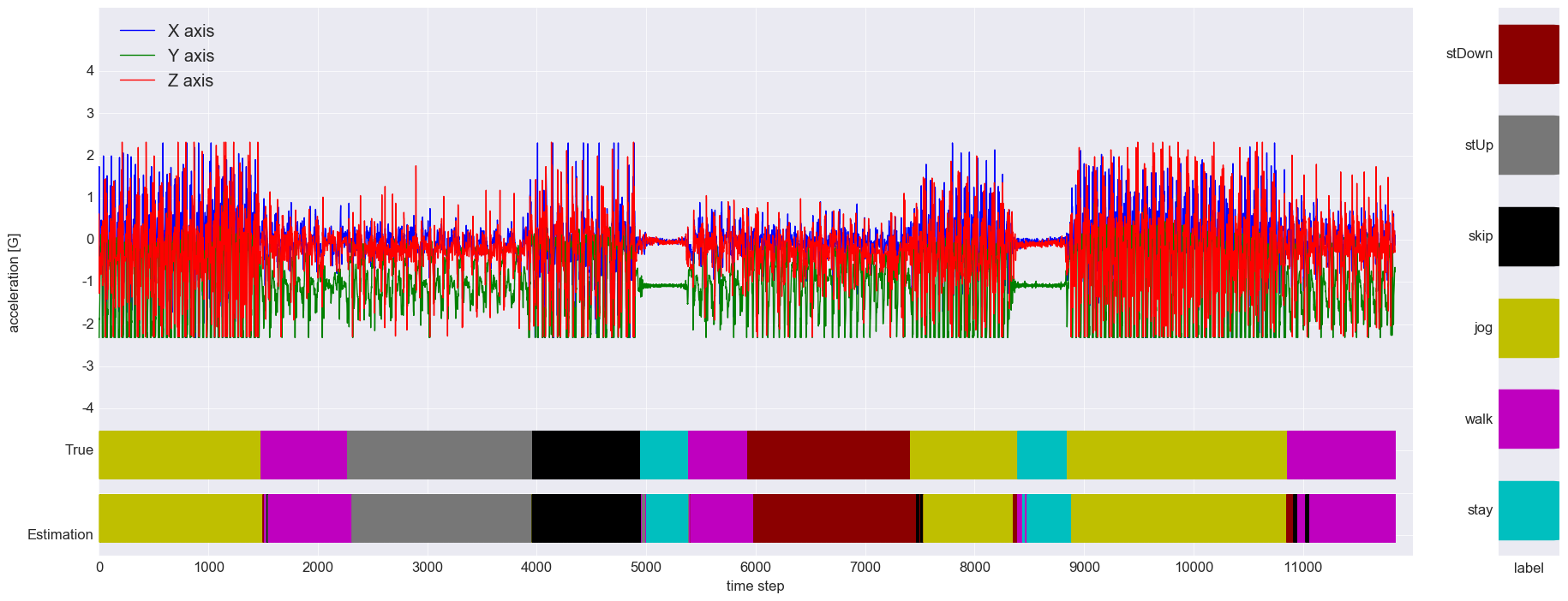
わりといい感じです.
まとめ
加速度信号からの人間行動認識をRNNで行いました.
セグメンテッドデータのみで学習したせいか、シーケンスデータに対しての認識率は思ったほど上がりませんでした.(行動遷移時に誤認識やディレイが見られます)
しかし、この手法だと特徴量抽出器がいらない上に逐次的に推定が行えるためリアルタイム認識にもってこいなのではと思ってます.ネットワークの構造がシンプルなぶんシミュレーション上の推定時応答速度も速いです.ただ、実際に携帯端末にのっけた場合どうなるかはわかりません.Androidなんかで実装して試せれば良いのでしょうが、そんなスキルはありません…