この記事はR Advent Calender 2016の16日目の記事です。
はじめに
- データ分析にRとPythonを普段使っています。
- ここ数年でRを使って、データ分析を教えてる際に、同じようなことを前に誰かに聞かれてっていうのがあるのでちゃんとまとめておこうと思います。
- とくにRの技術的なことは解説しないので、あるあるだなーと思って頂ければ幸いです。
質問集
なんでRを使うのですか?
ちょっと古い記事ですが、Choosing R or Python for data analysis? An infographicなど、色々な意見がある中で個人的に説明するときは、
- 再現性の確保
- RStudioの機能性
- Pythonより、Rのほうがプログラミングという感覚が少なく、プログラミングが苦手な方にも入りやすそうだったから
- 関数が豊富で、データ入力〜可視化までのコードを書くと結果的に見やすくなる(これは私だけかもですが…)
ただ、機械学習をがっつり実装するとなると、コーディングがメインになるのでPythonをお勧めするというイメージです。
あるCSVデータを入力したい
CSVデータを読む出すときに、read.csv はもちろんですが、実問題だと大きなCSVファイルが多いので、速度の点で、fread を勧めています。
ただ、1点問題なのが、デフォルトだと data.table で読んでしまい、一般的な data.frame と混ざって初学者をややこしくしてしまうので、fread(data.table=F) にして利用してます。readr::read_csv() も選択肢ですが、速度優先で使っています。
CSVファイルが複数あるので、一度に読みたい
ここらへんから、R初学者にはちょっと面倒になってきますね。forループを使わずに書くのに慣れてもらうのに apply 系は必須です(といっても、ここで挫折してもらわないためにも、はじめはforで書くのでも良いのですが)
Importing multiple .csv files into Rのとおりで、 list.files でファイルリストを作って、 lapply関数で引数に与えたファイルリストで繰り返し処理し、fread でデータを読み込んだdata.frame形式をlist形式でまとめて保存する。その後、 do.call でまとめて rbind でくっつける処理を行う。
files = list.files(pattern="*.csv")
df = do.call(rbind, lapply(files, function(x) fread(x,data.table=F)))
データ操作は?
後にも先にも、 dplyr です。そして、%>% の便利さです。
さらに最近は、tidyverse でまとめてインストールできるのが良いですね。
この辺は解説記事が山ほどあるので、私の方ではほとんど解説なしです、すいません。。
変数名の命名規則は?(コーディングスタイル)
RStudioを使う前提ですが、右上のEnviroment謎の変数がいろいろでき上がってきます。
一定の命名規則をもたせればいいと思うのですが、データフレームなら、dfやdataを頭につけて、.でつなげるとかを決めればいいと思います(例 : df.12gatu.value)
おすすめは、以下の通りがあるので、それをもとに作っています。
縦持ちデータと横持ちデータのやりとり
といっても、やはりエクセルに慣れた方は、これにまずハマります。ある列で集計するようなことをするなら、データの持ち方を変更する必要があるからです。
reshape2 と tidyrがありますが、今ならどっちが人気なんですかね。。周りは今でもreshape2を使う方が多いイメージです。
grouped_df の挙動
dplyr::group_by の後に dplyr::summarize() で集計した結果をdata.frameに入れて、再度操作することがあります。
そうすると、grouped_dfのせいでうまく操作ができないことがあります。
> head(aaa)
Source: local data frame [6 x 3]
Groups: k, filename [1]
k filename mean_num
<chr> <chr> <dbl>
1 k=02 default_cleansing 2998.71
2 k=02 default_cleansing 3503.85
<snip>
> class(aaa)
[1] "grouped_df" "tbl_df" "tbl" "data.frame"
こんな aaa に対して、不要な列を消そうとすると、grouped_dfのせいで消せない。。
aaa %>% dplyr::select(-k) -> bbb
Adding missing grouping variables: `k`
> head(bbb)
Source: local data frame [6 x 3]
Groups: k, filename [1]
k filename mean_num
<chr> <chr> <dbl>
1 k=02 default_cleansing 2998.71
2 k=02 default_cleansing 3503.85
<snip>
こういうときに、ungroup() を使うとgroup化されてる変数情報を削除できるので普通に扱えるようになります。
> aaa %>%
+ dplyr::ungroup() %>%
+ dplyr::select(-k) -> bbb
> head(bbb)
# A tibble: 6 × 2
filename mean_num
<chr> <dbl>
1 default_cleansing 2998.71
2 default_cleansing 3503.85
<snip>
> class(bbb)
[1] "tbl_df" "tbl" "data.frame"
ただ、これよく使っている割には、どういったときに起こるのか、これが本当に正しい使い方なのかは正直わかりません。。
データの可視化は?
やはり ggplot2 も今年一番使ったパッケージでした。バージョンが2になったのがちょうど2015年12月のこの時期くらいだったので、今年1年さらに便利に使わせてもらいました。
さらに、今年は plotly もオンプレ環境でも使えるようになり、インタラクティブな可視化ができるので使っていたのですが、まだできることがggplotに比べて少ないので、これからに期待しています。
ggplotの使い方も山ほど解説記事があるので省略します(省略ばかりすいません)
RStudioのショートカット(Mac)
Keyboard Shortcutsを参考にします(かなりの量がありますが、どこまでみんな使っているんですかね…)が、個人的によく使うものは大体ファイル編集しているときで以下くらいかなと思います。
- カーソルがある行のコメントアウト :
cmd + shift + c- 選択範囲で実行すると、一斉コメントアウトできる
- ファイル編集で左タブ移動 :
ctl + option + LEFT - ファイル編集で右タブ移動 :
ctl + option + RIGHT - カーソルがある行を実行 :
ctl + option + RIGHT- 選択範囲でもできる
- Rmdのチャンク内を実行 :
cmd + option + c
Rmdでレポート化
Rの強みかなと思うのは、Rmdで書いておけば、そのままHTMLレポートを出力できて、メールに貼り付けて送るってこともできるので重宝します。
Rスクリプトとの区別は、Rmdはあくまで分析レポート。探索的な処理や関数とかはRスクリプトで書くようにしていますが、混ざることもあるので、明確に使い分けるの難しいです。
さらに最近は、結果を見ながら分析を進めれるという点で、R notebooksも布教していきたいと思います。
Viewは危険
RStudioは直感的に、変数の中身見れるのですが、大きなデータフレームをクリックして開こうとすると固まりますよね。初学者はこれをやってしまって、取り消そうと思ったら、RStudioがクラッシュして、saveしてなかったファイルが消えるという事故が多発します。。
大きなファイルを開くときは、View(head(df)) をするように言っているのですが、これってデフォルトで何か制御できる?んですかね。知っていたら教えてほしいです。
表を作って、htmlレポートに入れたい
DT::datatable で簡単に data.frame形式の変数を表に出せるので、使っています。
DT::datatable(iris)
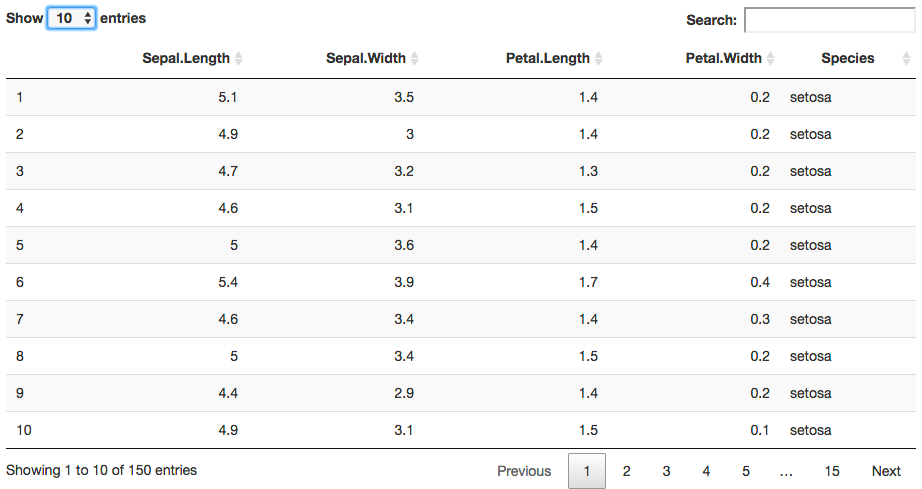
以前は、xtable も使っていましたが、今は気軽さと検索ができるので、datatableを使っています。
寝ている間に処理を進めたい
最終的にRStudioで書いたRmdのコードをより大きなファイルで動かしたい場合、寝ている間に実行しておきたいなとなり、Rが入ってる環境で、以下のコマンドでバックグラウンド実行します。
$ Rscript -e 'rmarkdown::render("test.Rmd", output_file="test.html”)'
これで寝ている間にtest.htmlファイルが出来上がってレポートができているはずです。
おわりに
- 担当日に思い出しながら書いたもので、完成度や網羅性がいまいちなので、また順次追加していきたいと思います。
- 今年もRの発展で、データ分析のしやすさはもちろんですが、特にアウトプットを意識したレポート化(flexdashboard)やより柔軟な可視化がしやすくなった1年だったなと思います。来年もR Enjoyしていきます。