Kaggle の Microsoft Malware Classification Challenge に参加してました。最終結果は 383 チーム中 26 位。初の Achievement (top 10%) が貰えました。
以下、構築したモデルについてのラフな説明です。
タスク
- マルウェアのクラス分類
- 入力:hexdump ファイル (.bytes) と assembly ファイル (.asm)
- 出力:マルウェアのクラス確率 (9種類)
- データ数
- 訓練データ:10,868
- 評価データ:10,873
- 詳細
生の hexdump と assembly が与えられるため、特徴設計で差が出るタスクでした。
データ総量が約 500GB で前処理大変。
モデル概要
Bag-of-words 特徴量を hexdump と assembly の両方から抽出。それぞれの Bag-of-words に対し Random Forest でフィッティングして重要度による特徴選択。最後に Gradient Boosting でクラス分類。(特徴抽出以外には scikit-learn を利用。)
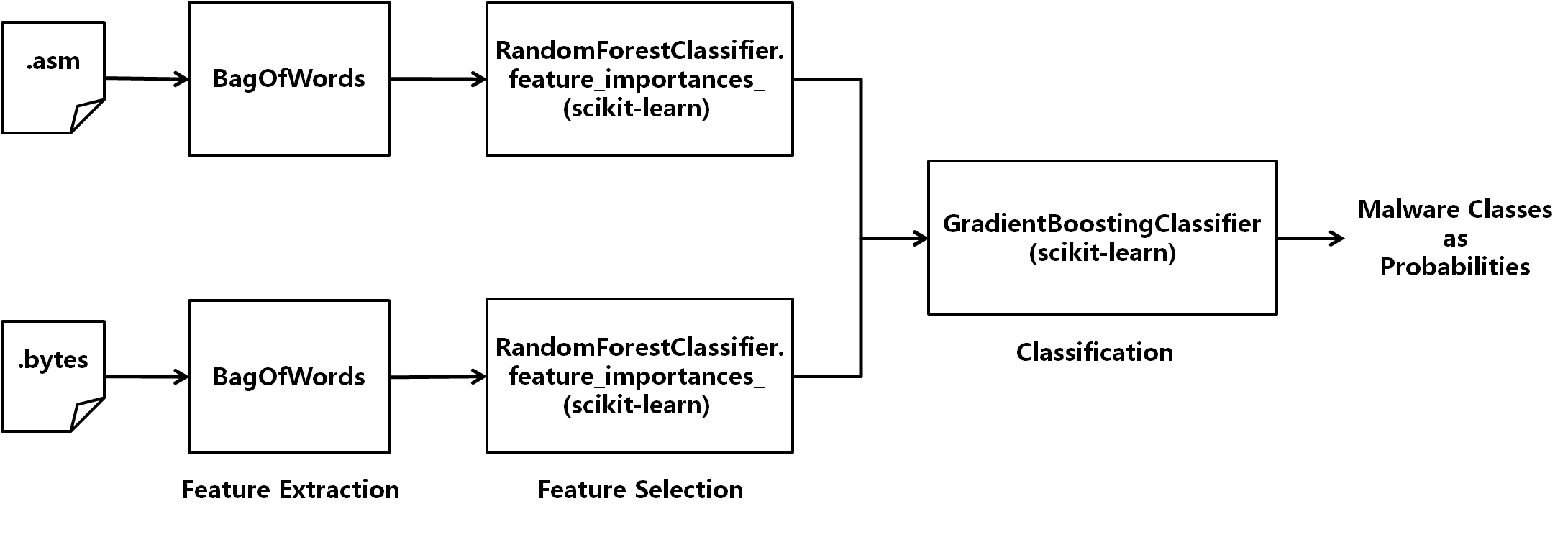
特徴抽出
試行錯誤しましたが、単純な Bag-of-words に落ち着きました。
- Hexdump から Bag-of-words (2 ** 16 = 65,536 次元)
- 16bit を 1 単語と捉えて 8bit シフトで抽出
- 行頭のアドレスは無視
- 下図参照
- Assembly から Bag-of-words (53,319 次元)
- スペース区切りで単語抽出
- 記号や数字も区切り文字扱い
- 行頭のセクション名、アドレス、オペコードは無視
- 全文書での出現回数が 100 未満の単語は無視

特徴選択
Random Forest でフィッティングして特徴の重要度で絞り込み。
-
RandomForestClassifier.feature_importances_
- Hexdump 特徴 65,536 次元 => 10,000 次元
- Assembly 特徴 53,319 次元 => 5,000 次元
- 合計 15,000 次元
データサイズ約 11,000 に対して次元数 15,000。時間の都合により、選択次元数に対するグリッドサーチ等は試していません。雑な観測では、次元を落とすとパフォーマンスも落ちる傾向にありました。バイアス低めなモデルの方が上手くいくようです。
分類器
scikit-learn に入っている Ensemble 学習を一通り試して Gradient Boosting を使うことに。
-
GradientBoostingClassifier
- 500 イテレーション
イテレーション以外は scikit-learn のデフォルトパラメタ。ここを参考に、他いろいろチューニングしてみたものの上手く行かず。汎化しようとすると逆にパフォーマンスが落ちてました。
インフラ
ハードウェアはAWSで調達。
- インスタンス:AWS EC2 r3.xlarge
- 追加ボリューム:AWS EBS General Purpose 50GB
- OS:Ubuntu 14.04
Bag-of-words の一括ロードに必要なメモリを踏まえて r3.xlarge を選んでいます。部分的にロード/学習すればもっと節約できたはず。
デフォルトのディスクサイズだと解凍前のデータすら置けなかったので、50GB のボリュームを追加しました。解凍後のデータも 50GB では足りないので、フォーラムを参考に libarchive を利用。
パフォーマンス
スコア計算は log loss。最終スコアは Public LB (常時スコアされる三割だけのテストデータ) で 0.009941155 (暫定27位)、Private LB (コンペ終了後にのみスコアされる全テストデータ) で 0.009240644 (26 位) でした。
上位勢との差分
- Hexdump からより高次元の Bag-of-words 抽出
- Assembly からセクション毎 (.data / .rsrc / .text / ...) に特徴抽出
- DAF 特徴量
- Texture 画像を使った分類
- XGBoost
- etc.
特徴抽出に Bag-of-words、特徴選択に Random Forest を使うあたりは上位勢にも共通してました。自分のモデルにオリジナリティが出てなくて残念。
DAF 特徴量や texture 画像といった domain specific な手法(?)はまるで手が回らず…
分類器は Gradient Boosting ではなく XGBoost を使っている人が多かったようです。今回初めて知ったの手法なので要フォローアップ。