#はじめに
IchigoJam で BASIC と C とアセンブラで作成したプログラムの速度の比較を行い、戯れに最適化を試みてみました。
プログラムは、IchigoJamでマンデルブロ集合を表示する BASIC プログラムをクリエイティブ・コモンズ・ライセンスで公開されている方がおり、今回の比較に都合が良かったのでこれを利用させてもらっています。
使用した各言語の処理系は、
| 言語 | 処理系 | 版 | 公開アドレス |
|---|---|---|---|
| BASIC | IchigoJam BASIC | ver 1.2.1 USキーボード用 | http://ichigojam.net/download.html |
| C | gcc | 5.4.1 | https://launchpad.net/gcc-arm-embedded |
| C | clang | 3.9.1 | http://releases.llvm.org/download.html |
| アセンブラ | GNU Binutils(gccに付属のもの) | 2.26.2 | https://launchpad.net/gcc-arm-embedded |
以上を使用しています。
#BASIC
オリジナルのソースを IchigoJam に入力し、20行目を削除、以下の行を追加し実行することで
5 CLS:CLT
50 LC0,23:?TICK()
画面消去から以降、マンデルブロート集合が表示し終わるまでの時間を計測します。時間は IchigoJam BASIC の関数 TICK() によって計測しており、約 1/60秒が単位となります。
実行結果は以下の通りです。

31008 という結果ですが、約1/60秒を単位としているのでこれを時間に直すと 31008 * 1/60 = 516.8 ということで、およそ 8分37秒ほど掛かったこととなります。このプログラムの作者は記事で「全部描画するのに15分ぐらい」と書かれていますが、この記事を書かれた当時より IchigoJam BASIC の実行速度がバージョンアップにより大きく向上しているようです。
#C
##gcc を試す
先の BASIC プログラムを変数のサイズ以外割と忠実に C に移植したものを以下に示します。
#include <stdint.h>
int mandelbrot(int16_t arg, uint8_t* ram, const uint8_t* font)
{
(void)arg; (void)font;
int n = 32;
int w = 64, h = 48;
int a = 2 << 6, b = a * a, c = (3 << 12) / w;
for (int y = 0; y < h; y++) {
int v = (y - h / 2) * c;
for (int x = 0; x < w; x++) {
int u = (x - (w * 3) / 4) * c;
uint8_t* z = &ram[0x900 + (x / 2) + (y / 2) * 32];
int j = 1 << ((y % 2) * 2 + (x % 2));
int k = j | 0x80 | *z;
*z = k;
int p = u, q = v, i = 0;
do {
int r = p / 64; p = r * r; if (p < 0) goto l40;
int s = q / 64; q = s * s; if (q < 0) goto l40;
if (p + q < 0 || p + q > b) goto l40;
p = p - q + u;
q = 2 * r * s + v;
} while (++i < n);
*z = k ^ j;
l40:;
}
}
return 0;
}
これを以下の Makefile と Perl スクリプトで機械語にコンパイル、BASIC のコメントの形に変換し、 mandelbrot.apo を作成します。コンパイラの最適化オプションは速度重視ということで `-Ofast' を指定しています。
target: mandelbrot.apo
mandelbrot.s: mandelbrot.c
arm-none-eabi-gcc -Wall -W -mcpu=cortex-m0 -mthumb -fpic -Ofast -S $<
mandelbrot.o: mandelbrot.s
arm-none-eabi-as $< -o$@ -a=$(<:.s=.prn)
mandelbrot.x: mandelbrot.o
arm-none-eabi-ld --entry 0x700 -Ttext 0x700 $< -o $@ -Map $(@:.x=.map)
mandelbrot.mot: mandelbrot.x
arm-none-eabi-objcopy -O srec $< $@
mandelbrot.apo: mandelbrot.mot
perl hex2apo.pl $< > $@
#!/usr/bin/perl
$start = 0xffffffff;
$end = 0x00000000;
while(<>) {
$S = substr($_, 0, 1);
$type = substr($_, 1, 1);
die if ($S != "S" || !($type >= 0 && $type <= 9));
$size = hex(substr($_, 1 + 1, 2));
for ($sum = 0, $i = 0; $i <= $size; $i++) {
$sum += hex(substr($_, 1 + 1 + 2 * $i, 2));
}
die if (($sum & 0xff) != 0xff);
if ($type >= 1 && $type <= 3) {
$size = $size - 1 - ($type + 1);
$address = hex(substr($_, 1 + 1 + 2, 2 * ($type + 1)));
if ($start > $address) {
$start = $address;
}
if ($end < $address + $size - 1) {
$end = $address + $size - 1;
}
for ($i = 0; $i < $size; $i++) {
$mem[$address + $i] = hex(substr($_, 1 + 1 + 2 + 2 * ($type + 1) + 2 * $i, 2));
}
}
}
$line = 10;
for ($i = $start; $i <= $end;) {
printf("%d '", $line);
for ($j = 0; $j < 15; $j++) {
$n = 0;
for ($k = 0; $k < 8; $k++) {
$n = ($n << 8) & 0xff00;
if ($k < 7) {
$n += $mem[$i++];
}
&putc((($n >> ($k + 1)) & 0x7f));
if ($i > $end) {
if ($k < 7) {
&putc((($n << (6 - $k)) & 0x7f));
}
last;
}
}
if ($i > $end) {
last;
}
}
printf("\n");
$line += 1;
}
sub putc {
my ($c) = @_;
$c += 0x21;
if ($c >= 0x7f) {
$c += (0xa1 - 0x7f);
}
printf("%c", $c);
}
10 'サNLキSz-eD4IヲkP、Um2a#=?」&j」%^y%チHn2aj)%c&n-ャィ9bW")q!J;M!$ja%Z{;ACNrcA-r-#n7・';3Ig#GmUEr-{DH)a*-Ga"ゥg1%f-"23ォjs#Cga)jUQャ'ヲ
11 'D'イ#"1UdBra:1#G*ウCDA%ャ!!i2iU9%サエ-1ォa"Qxqァ&セBZ、![A1D.9・12neA1!ォ!bBwiYォ、KfカXA*|J.9D9ォ、4ァUウ!iカeX.)|DQ'ァ"Oエr」)seQ7X」C!GQMm」L
12 'sキA#!?」]。E)ャk;egvr。,ュJ-"nuォ'39GウエZ」/コツチ!ア`ツウ
これを読み込んでメモリに書き込み機械語プログラムとして実行し、TICK() を使用して実行時間を計測し表示する BASIC プログラムとマージしたものが以下となります。
1 ' Mandelbrot set(gcc)
2 Z=#C03:Y=#700
3 X=0
4 IFPEEK(Z)=39X=X-1:W=33-PEEK(Z-X):IFW<1V=V<<7-W+W/96*34:POKEY,V>>(X&7):Y=Y+(X&7<7):GOTO4
5 Z=Z+PEEK(Z-1)+4:IFPEEK(Z-3)+PEEK(Z-2)GOTO3
6 CLS:CLT:Z=USR(#700,0):LC0,23:?TICK()
10 'サNLキSz-eD4IヲkP、Um2a#=?」&j」%^y%チHn2aj)%c&n-ャィ9bW")q!J;M!$ja%Z{;ACNrcA-r-#n7・';3Ig#GmUEr-{DH)a*-Ga"ゥg1%f-"23ォjs#Cga)jUQャ'ヲ
11 'D'イ#"1UdBra:1#G*ウCDA%ャ!!i2iU9%サエ-1ォa"Qxqァ&セBZ、![A1D.9・12neA1!ォ!bBwiYォ、KfカXA*|J.9D9ォ、4ァUウ!iカeX.)|DQ'ァ"Oエr」)seQ7X」C!GQMm」L
12 'sキA#!?」]。E)ャk;egvr。,ュJ-"nuォ'39GウエZ」/コツチ!ア`ツウ
これを IchigoJam に入力し、実行した結果が以下の通りです。

結果の数値が小さすぎ、計測の際に切り捨てられた小数点以下の値の大小が結果を評価するには誤差として大きすぎるので、プログラムを変更し、
6 CLS:CLT:FORI=1TO100:Z=USR(#700,0):NEXT:LC0,23:?TICK()
100回実行した上で結果を評価します。
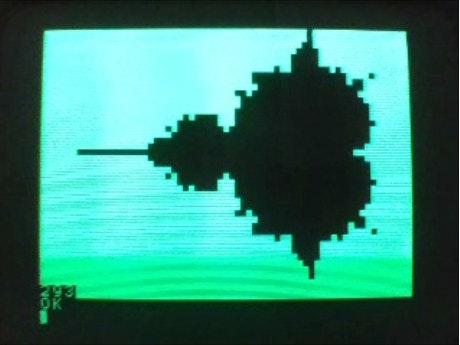
293 ということですが、先の行から Z=USR(#700,0) を削除し
6 CLS:CLT:FORI=1TO100:NEXT:LC0,23:?TICK()
マシン語部分を実行せず 100回ループだけを実行した場合の結果が

9 ということなので、(293-9)/100 = 2.84 が 1回当たりのおよその実行時間ということとなります。
##clang を試す
先の Makefile で arm-none-eabi-gcc を呼んでいる行を
clang -Wall -W -target arm-eabi -mcpu=cortex-m0 -fpic -Ofast -S $<
に変更することで使用する Cコンパイラを clang に変更できます。最適化オプションは gcc の場合と同じく `-Ofast' を指定しています。clang で生成したコードを組み込んだ BASIC のプログラムが以下になります。
1 ' Mandelbrot set(clang)
2 Z=#C03:Y=#700
3 X=0
4 IFPEEK(Z)=39X=X-1:W=33-PEEK(Z-X):IFW<1V=V<<7-W+W/96*34:POKEY,V>>(X&7):Y=Y+(X&7<7):GOTO4
5 Z=Z+PEEK(Z-1)+4:IFPEEK(Z-3)+PEEK(Z-2)GOTO3
6 CLS:CLT:FORI=1TO100:Z=USR(#700,0):NEXT:LC0,23:?TICK()
10 'サNRl!'C!1"S!C<!A#E-%:V3a-#s/)^c9&!Dオ=ャ'*2g」N!」(153bE!#JB.3!!5a,>キdー2cIA$mB$!-」'~!jw5<EU#nCD!}{=a%FgU=!c:Bbオ1+u*:%ィN59ャ8j
11 '-!$1Ua=g&H!zイmP<(]ヲ*ye]g\1ソエ^ソ>ァ-ャ・4・:idq'BZui(1B$\(!」-<Pqイ!!KV%-<Dc"Xl|%G!シk&!'m!O!mク{=A,Xー)#Yァ/-&kGe!A'M?,ォ$~ツツツ「ツセソ"}
12 'ツツィpツタチ"!!!!
これを実行すると結果が
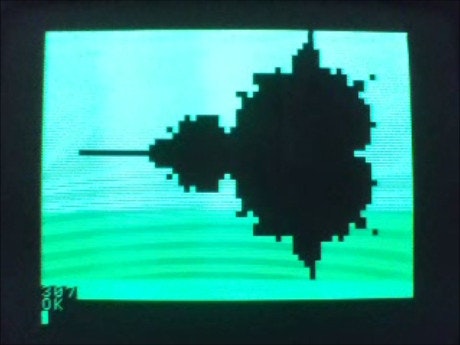
307 となりました。、(307-9)/100 = 2.98 が 1回当たりのおよその実行時間ということとなります。clang 派には残念な結果ですが、今回のテストでは gcc に僅かに(約5%)劣ることとなりました。
##手動での最適化を試す
今回の Makefile ではビルドの際にアセンブラソースを一旦出力し、アセンブル、リンクしています。先の gcc での場合に生成されたアセンブラソースの内容は以下となります。
.syntax unified
.cpu cortex-m0
.fpu softvfp
.eabi_attribute 23, 1
.eabi_attribute 24, 1
.eabi_attribute 25, 1
.eabi_attribute 26, 1
.eabi_attribute 30, 2
.eabi_attribute 34, 0
.eabi_attribute 18, 4
.thumb
.syntax unified
.file "mandelbrot.c"
.text
.align 2
.global mandelbrot
.code 16
.thumb_func
.type mandelbrot, %function
mandelbrot:
@ args = 0, pretend = 0, frame = 24
@ frame_needed = 0, uses_anonymous_args = 0
push {r4, r5, r6, r7, lr}
mov r7, fp
mov r6, r10
mov r4, r8
mov r5, r9
ldr r3, .L12
push {r4, r5, r6, r7}
mov r8, r3
movs r3, #0
sub sp, sp, #28
str r3, [sp, #20]
movs r3, #128
lsls r3, r3, #7
movs r7, #63
mov r10, r3
str r1, [sp, #16]
.L6:
movs r1, #1
ldr r2, [sp, #20]
ldr r6, .L12+4
asrs r3, r2, #1
lsls r3, r3, #5
ands r1, r2
str r3, [sp, #8]
lsls r3, r1, #1
str r3, [sp, #12]
movs r3, #0
mov fp, r3
.L5:
movs r2, #144
mov r3, fp
lsls r2, r2, #4
mov ip, r2
ldr r2, [sp, #8]
asrs r3, r3, #1
add r3, r3, ip
mov ip, r2
ldr r2, [sp, #16]
add r3, r3, ip
mov ip, r2
mov r2, fp
add ip, ip, r3
movs r3, #1
ands r3, r2
ldr r2, [sp, #12]
movs r1, r6
mov r9, r2
movs r2, #1
add r3, r3, r9
lsls r2, r2, r3
mov r9, r2
movs r2, #128
mov r3, r9
orrs r2, r3
mov r3, ip
ldrb r3, [r3]
movs r4, #32
orrs r2, r3
mov r3, r8
str r2, [sp, #4]
str r3, [sp]
b .L4
.L2:
subs r1, r1, r2
ldr r2, [sp]
lsls r0, r0, #1
mov r8, r2
muls r3, r0
subs r4, r4, #1
adds r1, r6, r1
add r3, r3, r8
cmp r4, #0
beq .L11
.L4:
asrs r0, r1, #31
asrs r2, r3, #31
ands r0, r7
ands r2, r7
adds r1, r0, r1
adds r3, r2, r3
asrs r0, r1, #6
asrs r3, r3, #6
movs r1, r0
movs r2, r3
muls r1, r0
muls r2, r3
adds r5, r1, r2
cmp r5, r10
ble .L2
ldr r3, [sp]
mov r2, sp
mov r8, r3
mov r3, ip
ldrb r2, [r2, #4]
strb r2, [r3]
.L3:
movs r3, #1
mov ip, r3
add fp, fp, ip
mov r3, fp
adds r6, r6, #192
cmp r3, #64
bne .L5
movs r2, #192
mov ip, r2
ldr r3, [sp, #20]
add r8, r8, ip
adds r3, r3, #1
str r3, [sp, #20]
cmp r3, #48
bne .L6
movs r0, #0
add sp, sp, #28
@ sp needed
pop {r2, r3, r4, r5}
mov r8, r2
mov r9, r3
mov r10, r4
mov fp, r5
pop {r4, r5, r6, r7, pc}
.L11:
mov r2, r9
ldr r3, [sp, #4]
eors r3, r2
mov r2, ip
strb r3, [r2]
b .L3
.L13:
.align 2
.L12:
.word -4608
.word -9216
.size mandelbrot, .-mandelbrot
.ident "GCC: (GNU Tools for ARM Embedded Processors) 5.4.1 20160919 (release) [ARM/embedded-5-branch revision 240496]"
最適化オプションで `-Ofast' を指定しているため実行速度を重視したコードが吐かれている前提ですが、所詮は現代のコンパイラによるものなので無駄な部分は存在しています。
高速化のセオリーとして「ループの内側を重視する」というものがあります。今回の C プログラムは 3重ループの構造となっていますが、一番内側のループの部分
int p = u, q = v, i = 0;
do {
int r = p / 64; p = r * r; if (p < 0) goto l40;
int s = q / 64; q = s * s; if (q < 0) goto l40;
if (p + q < 0 || p + q > b) goto l40;
p = p - q + u;
q = 2 * r * s + v;
} while (++i < n);
についてのみ高速化を検討してみることとします。
先の一番内側のループ部分は上のアセンブラソースで
movs r4, #32
orrs r2, r3
mov r3, r8
str r2, [sp, #4]
str r3, [sp]
b .L4
.L2:
subs r1, r1, r2
ldr r2, [sp]
lsls r0, r0, #1
mov r8, r2
muls r3, r0
subs r4, r4, #1
adds r1, r6, r1
add r3, r3, r8
cmp r4, #0
beq .L11
.L4:
asrs r0, r1, #31
asrs r2, r3, #31
ands r0, r7
ands r2, r7
adds r1, r0, r1
adds r3, r2, r3
asrs r0, r1, #6
asrs r3, r3, #6
movs r1, r0
movs r2, r3
muls r1, r0
muls r2, r3
adds r5, r1, r2
cmp r5, r10
ble .L2
というコードに変換されています。
C のソース中、変数 p や q が負になった場合に goto でループから抜け出す処理は元の BASIC プログラムで変数のサイズが 16bit であることから発生しうる乗算のオーバーフローへの対策としてあったものです。C に移植した際に変数のサイズを 32bit としており、オーバフローの判定は論理的には不要な筈ですが、BASIC プログラムから忠実に移植する目的で組み込んでいます。これが、上記のコンパイラの出力コードではその部分が最適化でキレイに削除されており驚かされました。
【2017.9.3 追加】
C言語では符号付整数のオーバーフローは考慮されないので、下記のコード
int r = p / 64; p = r * r; if (p < 0) goto l40;
int s = q / 64; q = s * s; if (q < 0) goto l40;
r や s を 2乗した結果が負になることは考慮されず、最適化で「無駄な処理」として削除されたと思われます。
他、ざっと見た印象として
- フローが効率的でない
- mov 命令が多く、無駄な代入がありそう
- ループ中でスタックフレーム上のメモリを read しており遅い
- 符号付の値を 1/64 する際に符号ビットをマスクするのに r7 を使用しているが、命令の組み合わせで不要
- ループカウンタをデクリメントした後 #0 と比較しているが、デクリメントでフラグは変化するので比較自体が無駄
以上の点が気になりました。先の部分を
movs r4, #32
orrs r2, r3
mov r3, r8
str r2, [sp, #4]
str r3, [sp]
movs r7, r3
.L4:
asrs r0, r1, #6
asrs r2, r3, #6
lsrs r0, r0, #26
lsrs r2, r2, #26
adds r1, r0, r1
adds r3, r2, r3
asrs r1, r1, #6
asrs r3, r3, #6
movs r0, r1
muls r0, r3
muls r1, r1
muls r3, r3
adds r5, r1, r3
cmp r5, r10
bgt 1f
subs r1, r1, r3
lsls r3, r0, #1
adds r1, r6, r1
adds r3, r7
subs r4, r4, #1
bne .L4
b .L11
1:
と変更することでこれらの点を解消します。
mandelbrot.s にこの変更加えビルドし、BASIC のプログラムに変換したものが以下となります。
1 ' Mandelbrot set(hand optimized)
2 Z=#C03:Y=#700
3 X=0
4 IFPEEK(Z)=39X=X-1:W=33-PEEK(Z-X):IFW<1V=V<<7-W+W/96*34:POKEY,V>>(X&7):Y=Y+(X&7<7):GOTO4
5 Z=Z+PEEK(Z-1)+4:IFPEEK(Z-3)+PEEK(Z-2)GOTO3
6 CLS:CLT:FORI=1TO100:Z=USR(#700,0):NEXT:LC0,23:?TICK()
10 'サNLキSz-eD4IヲcP、Um2a#=?」&j」%^y%チHn2aj)%c&n-jィ9bW")q!J;M!$ja%Z{;ACNrcA-r-#n7・';3Ig#GmUEr-{DH)a*-Ga"ゥg1%f-"23ォjs#Cga)jUQャ'ヲ
11 'D'イ#"1UdBra:1#G@!C#:qg!/j$i2gmR*)ゥ・1a"QdEqョU?UQvCb|miャ'!Yg<Ri%シュォh=!%ーugm2mUQjオ;Y!EZ・<geNry$S!x\ォウ%JC9,<ウ2!497GQ6ュ;1"!0Q
12 '?P3%Uィ.CDKォイ&ク5g!ゥュU$*-4YY}ソ#9"アツツ」.ェツチ
これを実行した結果が

253 となりました。(253-9)/100 = 2.44 が 1回当たりのおよその時間となります。手動による最適化前は 2.84 だったものが 2.44 になり、約16.4% の高速化ができたこととなります。限定的な範囲で最適化を行った割には効果としては大きかったのではないでしょうか。
##ロジックを小変更してみる
先の C プログラムではドットをひとつ描画するごとに VRAM のアドレスを計算しています。VRAM のひとつのアドレスに 4つのドットが存在しますが、同一のアドレスを 4回も計算するのは無駄なので、改善を考えてみます。
同一の VRAM アドレスに存在する 4つのドットの計算を連続して行えばこの点は軽減できる筈です。VRAM のアドレスが連続していることを利用すれば VRAM アドレスの計算そのものが省略できます。これを C プログラムに施したものが下記となります。
#include <stdint.h>
int mandelbrot(int16_t arg, uint8_t* ram, const uint8_t* font)
{
(void)arg; (void)font;
int n = 32;
int w = 64, h = 48;
int a = 2 << 6, b = a * a, c = (3 << 12) / w;
uint8_t* z = ram + 0x900;
int v = (-h / 2) * c;
for (int y = 0; y < h; y += 2) {
int u = -((w * 3) / 4) * c;
for (int x = 0; x < w; x += 2) {
#define mandelbrot2(u, v) ({ \
int p = u; \
int q = v; \
int a = 0; \
int i = 0; \
do { \
int r = p / 64; p = r * r; \
int s = q / 64; q = s * s; \
if (p + q < 0 || p + q > b) { \
a = 1; \
break; \
} \
p = p - q + u; \
q = 2 * r * s + v; \
} while (++i < n); \
(a); \
})
int k = 0x80;
if (mandelbrot2(u, v)) {
k += 1;
}
v += c;
if (mandelbrot2(u, v)) {
k += 4;
}
u += c;
if (mandelbrot2(u, v)) {
k += 8;
}
v -= c;
if (mandelbrot2(u, v)) {
k += 2;
}
*z++ = k;
u += c;
}
v += 2 * c;
}
return 0;
}
VRAM アドレスは最初に設定し、4ドット書き込むごとにインクリメントだけを行っています。
これを gcc にてコンパイル、BASIC のプログラム化したものが下記となります。
1 ' Mandelbrot set(gcc)
2 Z=#C03:Y=#700
3 X=0
4 IFPEEK(Z)=39X=X-1:W=33-PEEK(Z-X):IFW<1V=V<<7-W+W/96*34:POKEY,V>>(X&7):Y=Y+(X&7<7):GOTO4
5 Z=Z+PEEK(Z-1)+4:IFPEEK(Z-3)+PEEK(Z-2)GOTO3
6 CLS:CLT:FORI=1TO100:Z=USR(#700,0):NEXT:LC0,23:?TICK()
10 'i)。,KV-eD8ォィS9E"&a3eXcォヲCAケ!-ngl@j45W!glCH)」-ーao!EャUR!apDM)」p"3!FqケBs*)"=&a.yァ!I!UUア(iOCAED>q}eaャg22-ッC/!'a%オ.Ud{g65U!lー
11 '!ュI。?ケ#DD2x5U、-ヲD-A#"!0」`a0U=EU"=CD7;1!I+U:エ_ォOCA*ォ(サヲG9「eTR*ァ!;!?IVs/;9v2q#PU$KCシ\qB/Ugォ2'ウ"!fa<ッiゥ;9オ!,!!チ#!!dB・DA*セ3:
12 'Rr!#カ4Bi,ケcオ#!eaAg;ReAD<)aA"q"#dN1エrfN.!3セA;{8l~%)ュァUャ.qC)%E{9オ!z2jァVィ-8!"ソ%!"'dega4スF*<-a&カWd18ー&ァ%"*!b-Uヲ)agW2!a$A#&'{
13 'BヲD+{;!FケaVUP8[#2ッIィS;Ugォ2)EQ#X"<'o!*m"4」)ツカQッ$?B!;'(=$<1-」:?!g|!H)ャ"0ceNaT5I$Aoカa%!>aシ]i2t5V*.LD]8|+:MgアZウ#;:.ZDG)ゥp>Mg
14 'xZサ%Q$~ツツa<pツソ
実行した結果が

(269-9)/100 = 2.60 ということで、ロジックを変更する前の 2.84 と比べ、約9%の改善となりました。先の手動での最適化ほどではありませんが、お手軽な方法としては効果は小さなものではないのではないかと思います。
ちなみに、clang でビルドした場合にはプログラムは
1 ' Mandelbrot set(clang)
2 Z=#C03:Y=#700
3 X=0
4 IFPEEK(Z)=39X=X-1:W=33-PEEK(Z-X):IFW<1V=V<<7-W+W/96*34:POKEY,V>>(X&7):Y=Y+(X&7<7):GOTO4
5 Z=Z+PEEK(Z-1)+4:IFPEEK(Z-3)+PEEK(Z-2)GOTO3
6 CLS:CLT:FORI=1TO100:Z=USR(#700,0):NEXT:LC0,23:?TICK()
10 'サNR\!Ea!"#$!"&Mk"EA*)CFa:"オFCI$1"GAj)7A"1A!Qua&>%GB:1z.i,」"」a・#2&2kE@aP!(-$)Aemg\1ケ"e%g+pア)Aw」49a'q、kR'」!#45)、{=a)ァ#イ0W!
11 '3cTA]セA8a$c"e%C+D5i`!。!/9'1b*"-aB、d!uチソc&W":キiS3.4)W!!0:D'.r、!|ィーa]!B!'d%ゥ9$!!m'i!i」]ツA8a$c"e1CCD5i`a。!/='1r*B-aB、ヲ!uゥ?c
12 '&W!ャkiQ3.:IWa!0:Dg/、、!~ィーa]!b!'d"ァ」#Q;[)n[#サ!Yq9c%EuTV(q,」"、!・!2"2kE;eS$4ツ」1uアSc&ケ!ャlER..9)U!!2:B'/、、!~ヲーaカ18!%A"ゥA597Q"
13 'Y#TN1ァ*:eh)"・!s!ー;=ウeヲ!:"2a*mEY"m)'$"E"{Lシ」#!O、ウ。ウ)」(\ツツ!X@ツソdタツ`aA!!!
となり、実行した結果が
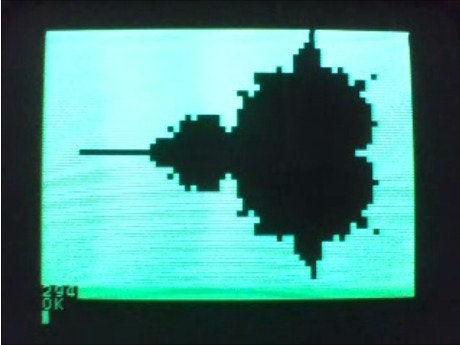
(294-9)/100 = 2.85 という結果となりました。clang での先の例 2.98 よりは改善していますが 約4%程の改善であり、gcc の場合と比べると効果は大きいものではありませんでした。
#アセンブラ
先の手動による最適化とロジックの変更の経験を踏まえた上でアセンブラでプログラムを書いてみました。
.syntax unified
.cpu cortex-m0
.thumb
.macro mandelbrot2 bit
mov r2, r8
mov r3, r9
movs r4, #n
0:
asrs r0, r2, #6
lsrs r0, r0, #26
adds r2, r2, r0
asrs r2, r2, #6
asrs r0, r3, #6
lsrs r0, r0, #26
adds r3, r3, r0
asrs r3, r3, #6
movs r1, r2
muls r1, r3
muls r2, r2
muls r3, r3
adds r0, r2, r3
cmp r0, r10
bgt 9f
subs r2, r2, r3
add r2, r8
lsls r3, r1, #1
add r3, r9
subs r4, #1
bne 0b
subs r5, #\bit
9:
.endm
.text
.align 1
.global mandelbrot
mandelbrot:
.equiv vramoffset, 0x900
.equiv n, 32
.equiv w, 64
.equiv h, 48
.equiv a, 2<<6
.equiv b, a*a
.equiv c, (3<<12)/w
push {r4, r5, r6, r7, lr}
mov r3, r8
mov r4, r9
mov r5, r10
mov r6, r11
mov r7, r12
push {r3, r4, r5, r6, r7}
movs r0, #vramoffset>>4
lsls r0, r0, #4
adds r6, r0, r1
movs r0, #c
mov r12, r0
rsbs r0, #0
mov r14, r0
movs r0, #b>>12
lsls r0, r0, #12
mov r10, r0
ldr r7, uend
ldr r0, vend
mov r11, r0
ldr r0, vstart
mov r9, r0
yloop:
ldr r0, ustart
mov r8, r0
xloop:
movs r5, #0x8f
mandelbrot2 1
add r9, r12
mandelbrot2 4
add r8, r12
mandelbrot2 8
add r9, r14
mandelbrot2 2
add r8, r12
strb r5, [r6]
adds r6, #1
cmp r7, r8
bne xloop
add r9, r12
add r9, r12
cmp r11, r9
bne yloop
pop {r3, r4, r5, r6, r7}
mov r8, r3
mov r9, r4
mov r10, r5
mov r11, r6
mov r12, r7
movs r0, #0
pop {r4, r5, r6, r7, pc}
.align 2
vstart:
.word (-h/2)*c
vend:
.word (h/2)*c
ustart:
.word -((w*3)/4)*c
uend:
.word ((w*(4-3))/4)*c
.end
レジスタを極力活用するよう努めた結果、C コンパイラの出力コードでは存在したスタックフレームにデータを置くことが不要となりました。
これを BASIC のプログラムとしたものが下記となります。
1 ' Mandelbrot set(asm)
2 Z=#C03:Y=#700
3 X=0
4 IFPEEK(Z)=39X=X-1:W=33-PEEK(Z-X):IFW<1V=V<<7-W+W/96*34:POKEY,V>>(X&7):Y=Y+(X&7<7):GOTO4
5 Z=Z+PEEK(Z-1)+4:IFPEEK(Z-3)+PEEK(Z-2)GOTO3
6 CLS:CLT:FORI=1TO100:Z=USR(#700,0):NEXT:LC0,23:?TICK()
10 'サNIUSR-vD8iゥ[<エUi)!!+9Ra1B)ァ#+-g#)!!=*-dHq*);9ソiarhキe".03qiァ{9aEi%Q!ウiR3)ゥ#9!YW9neC1#ィ'sBwォ^!、Af$X;Bs*)l!3ォa*カvr!p]5C*-l
11 'D)%j!g!/*'3B-」D!('ヲ*yeC!MqュE;ー(q-5)qWカE;B2*Q#N)"?[{1BコaeB2jUR!j1)」"、1・E2m%Q!ウッR<)eA&k.EdNqス"cb+'アUdE327!Fr!4ェLC)?ソIe3:7g
12 '1*3"-!=3-Ec:ag!/.g4R)e!zBuiV{0A9I2AーゥiUcC3」%{1#]クUADイ")VY!Gァ[7Frウr=5GN,-ォチ8jc;cgv2wUVエ-!1]8}#9"アツツ」"1!!!ア`ツウ!Q!!
実行結果は、

(215-9)/100 = 2.06 ということで、これまでの中では最速の結果となりました。
#まとめ
以上の結果を表にしたものが下記となります。
| 処理系 | プログラム | 処理時間(単位は約1/60秒) | 処理時間最短のものと比べての倍率 |
|---|---|---|---|
| IchigoJam BASIC | オリジナル | 31008 | 15052.43 |
| gcc 5.4.1 | BASIC プログラムからの忠実移植 | 2.84 | 1.38 |
| clang 3.9.1 | BASIC プログラムからの忠実移植 | 2.98 | 1.45 |
| gcc 5.4.1 + 手動最適化 | BASIC プログラムからの忠実移植 | 2.44 | 1.18 |
| gcc 5.4.1 | ロジック小変更 | 2.60 | 1.26 |
| clang 3.9.1 | ロジック小変更 | 2.85 | 1.38 |
| GNU Binutils 2.26.2 | 2.06 | 1.00 |
まとめると、
- IchigoJam BASIC と比べると C やアセンブラで組まれた機械語プログラムは大変に速い
- gcc と clang の比較では、今回のテストでは gcc の方が実行速度の面では優秀だった
- gcc や clang が生成するコードより手でコーディングしたコードの方が今回のテストでは優秀だった
以上という感じです。
プログラムの実行速度向上を考えるに当たって
- ロジックを工夫する
- アセンブラを使用する
等は悩ましいところですが、プログラムのコーディングや保守に要するコストと効果のバランスを考慮して決定すべきでしょう。今回はまったくの戯れで行っていることなのでコストは考慮の外ですが。
プログラムを C 等の高級言語で書けば高速化のためのロジックを工夫することは容易く、逆に、一度アセンブラで書いてしまうとロジックの変更等は困難なものとなるので、先ずは C 等の高級言語で書いてロジックの工夫をすることは最適化の手段としては有効と思われます。
今回見た gcc の出力コードには明らかに無駄と思われる箇所はありました。gcc や clang の更なる改良も期待したいところです。
#更なる高速化を思い付いたので追記
C のプログラムでの変数 r や s を計算する箇所の 64 での除算について、
int r = p / 64;
int s = q / 64;
gcc の出力コードでは
.L4:
asrs r0, r1, #31
asrs r2, r3, #31
ands r0, r7
ands r2, r7
adds r1, r0, r1
adds r3, r2, r3
asrs r0, r1, #6
asrs r3, r3, #6
変数 p や q の符号ビットを 32bit に拡張し、r7の値(63) でマスクし、元の値に加え、6bit 算術右シフトしています。
アセンブラ版のプログラムでもレジスタの使い方は異なるものの考え方としては同じことを行っています。
0:
asrs r0, r2, #6
lsrs r0, r0, #26
adds r2, r2, r0
asrs r2, r2, #6
asrs r0, r3, #6
lsrs r0, r0, #26
adds r3, r3, r0
asrs r3, r3, #6
これは、符号付の値を 2のべき乗の値で割る場合、被除数の正負にかかわらず 0 に収束させるために行う負の値への補正です。単純な算術右シフトだけの使用では正の値では 0 へ収束するものの、負の値は -1 へ収束してしまうため、それへの対策として行っています。
今回の C のプログラムでは元の BASIC のプログラムから変数のサイズが 16bit から 32bit に変更されており、精度的には余裕があるためプログラム中で変数 p と q について取り得る値の範囲では MSB 側 15bit は常に同じ値を持ちます。
これを利用すると、先のアセンブラのプログラムの上の箇所は
0:
lsrs r0, r2, #26
adds r2, r2, r0
asrs r2, r2, #6
lsrs r0, r3, #26
adds r3, r3, r0
asrs r3, r3, #6
と記述することが可能です。この変更を行い BASIC のプログラムに変換したものが下記となります。
1 ' Mandelbrot set(asm)
2 Z=#C03:Y=#700
3 X=0
4 IFPEEK(Z)=39X=X-1:W=33-PEEK(Z-X):IFW<1V=V<<7-W+W/96*34:POKEY,V>>(X&7):Y=Y+(X&7<7):GOTO4
5 Z=Z+PEEK(Z-1)+4:IFPEEK(Z-3)+PEEK(Z-2)GOTO3
6 CLS:CLT:FORI=1TO100:Z=USR(#700,0):NEXT:LC0,23:?TICK()
10 'サNIUSR-vD8iゥ[<エUi)!!+9Ra1B)ァ#+-g#)!!=*-`Hp*);9キiarhUe".03qiァ{9aEi$cBeiD9('ヲ*yeC!MqュE;ー(q-5)qWカE;B2*Q#N)"?\;1*コceB2jUR!j1
11 '(%d*1gQ/.g4R)e!zBuiV{0A9I2AーゥiUcC3」%{1#]ケUAdイ")cD3ォ・"3A/*'3B-」=<-G・2)"SdJ1ョU?aQqCb|n1ャ%eFa*UA%シッォc(「+2%gFre#Ea=3-Ec:aYW9
12 'neC1#ィ'sBwォ^!、Af$X;Bs*)l!3ォa*カzr"0]%Bv」"<2ォzwhceウr:UMtDサ。G)ュ+;ugzrxeQ!bウ。ウ)」(\ツツ!%a!!$Zツツa"a!!
これを実行すると (198-9)/100 = 1.89 という結果となりました(画像キャプチャは略)。まとめの表を更新したものが下記となります。
| 処理系 | プログラム | 処理時間(単位は約1/60秒) | 処理時間最短のものと比べての倍率 |
|---|---|---|---|
| IchigoJam BASIC | オリジナル | 31008 | 16406.35 |
| gcc 5.4.1 | BASIC プログラムからの忠実移植 | 2.84 | 1.50 |
| clang 3.9.1 | BASIC プログラムからの忠実移植 | 2.98 | 1.58 |
| gcc 5.4.1 + 手動最適化 | BASIC プログラムからの忠実移植 | 2.44 | 1.29 |
| gcc 5.4.1 | ロジック小変更 | 2.60 | 1.38 |
| clang 3.9.1 | ロジック小変更 | 2.85 | 1.51 |
| GNU Binutils 2.26.2 | 2.06 | 1.09 | |
| GNU Binutils 2.26.2 | 除算を高速化 | 1.89 | 1.00 |