Amazon Machine Learning
Amazon Machine Learning は、複雑な機械学習を簡単に利用出来るサービスです。
今回は Amazon Machine Learning の予測分類機能の中で多項分類と呼ばれるものを試してみます。
多項分類データとしては、機械学習のデータとして有名な"あやめ"を利用します。
これは、以下の4項目のデータを元に Setosa、Versicolor、Virgíniaという3つの
"あやめ"の種類(Species)に分類します。
・萼(がく)片の長さ(Sepal Length)
・萼(がく)片の幅(Sepal Width)
・花びらの長さ(Petal Length)
・花びらの幅(Petal Width)
トレーニングデータ作成・配置
トレーニングデータの準備を行います。
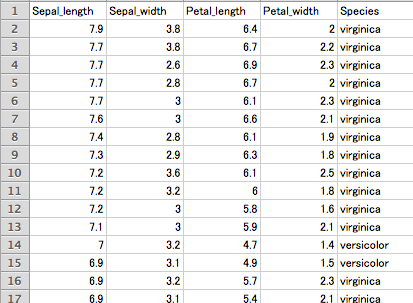
以下のような csv形式のデータを用意し AWS S3上へ配置します。
※注意点としては、改行コードが CR で保存されていると Amazon Machine Learning に
取り込む際にエラーが発生するため、CR/LF や LF で改行コードを保存する必要があります。
トレーニングデータ取り込み
トレーニングデータをAmazon Machine Learning に取り込みます。
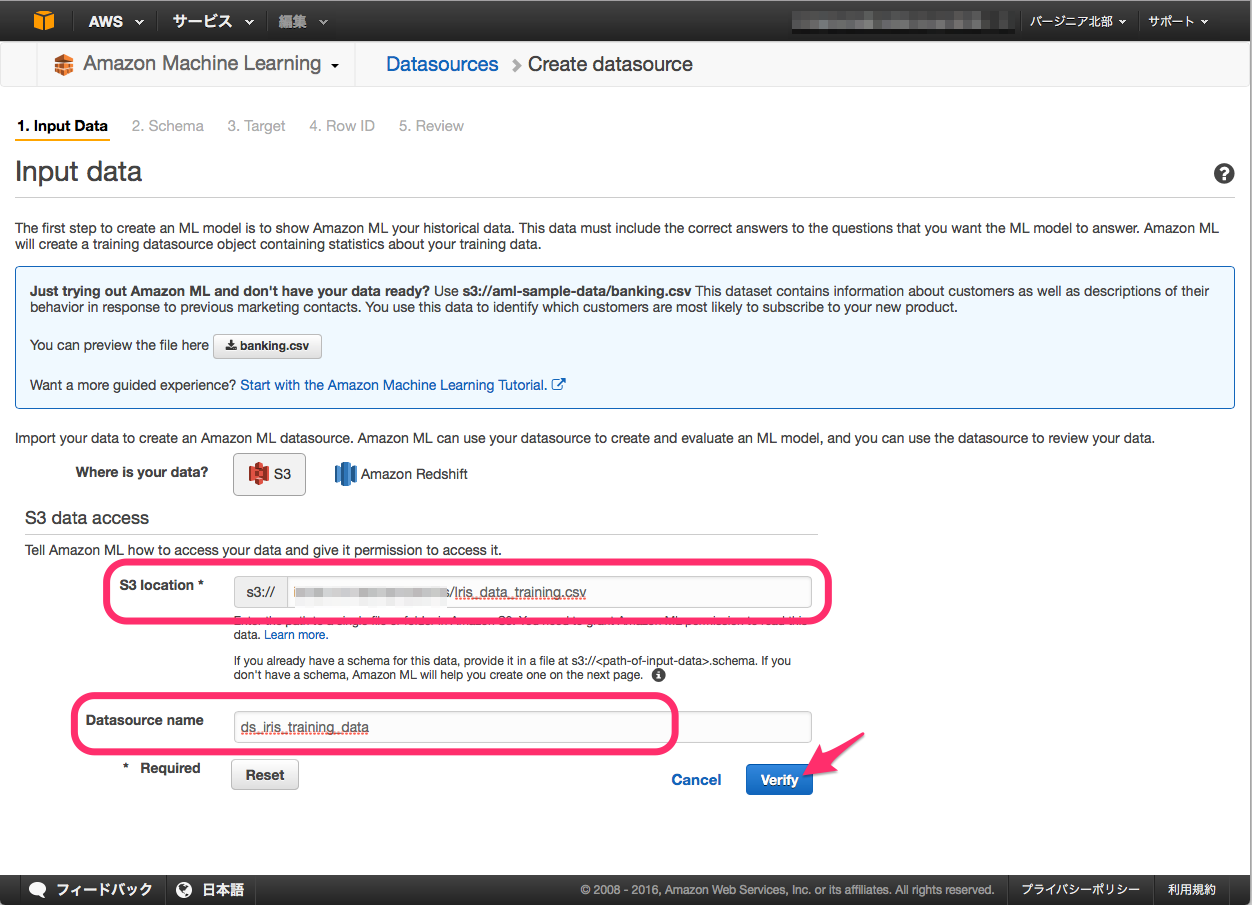
Input Data
"S3 Location" に AWS S3上へ配置したデータパスを設定し、
"Datasource name" に任意の名前を付けて次に進みます。
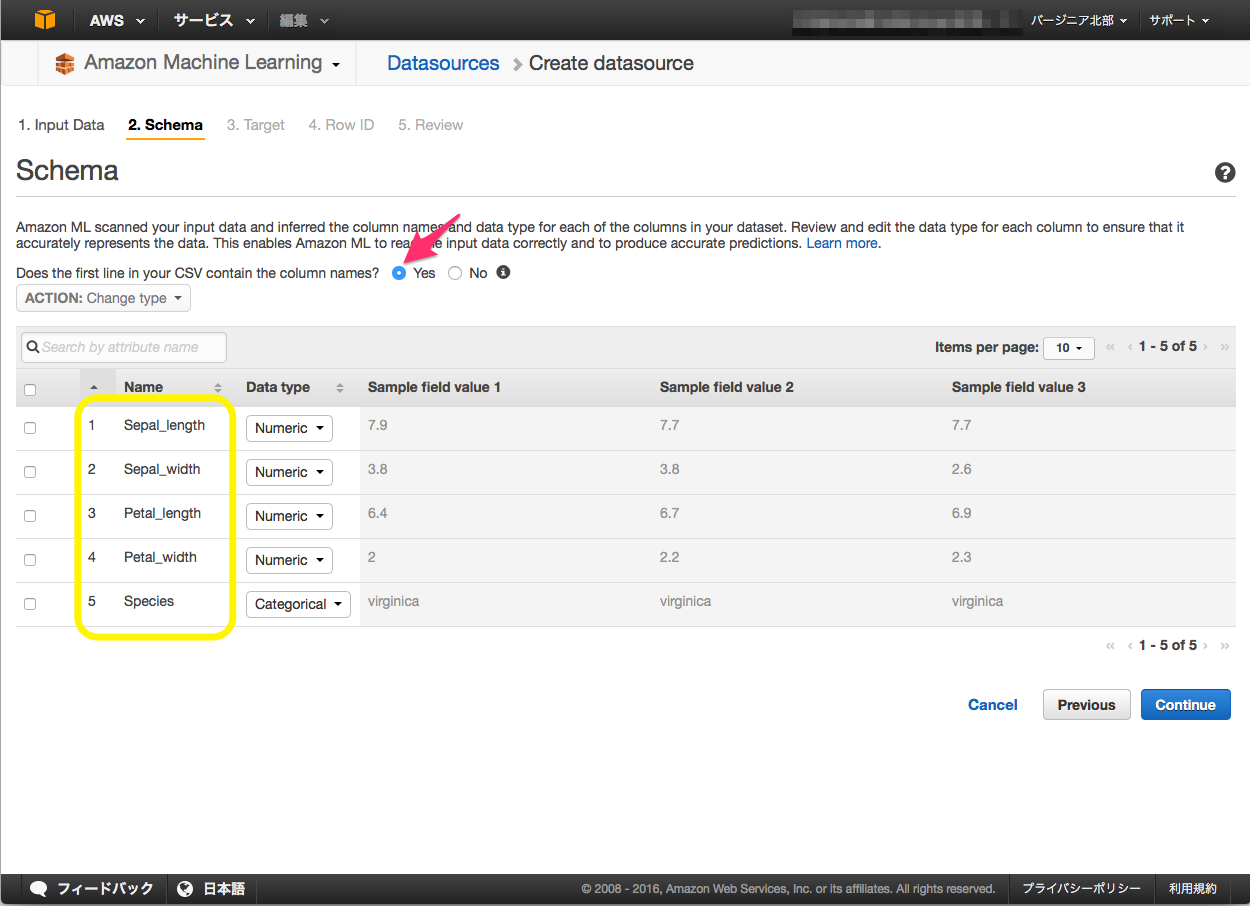
Schema
今回使用する csvデータの一行目に項目名が設定されているため、"Done the first..." のラジオボタンから "YES" を選択します。
"YES" を選択すると項目名が自動で入力されます。
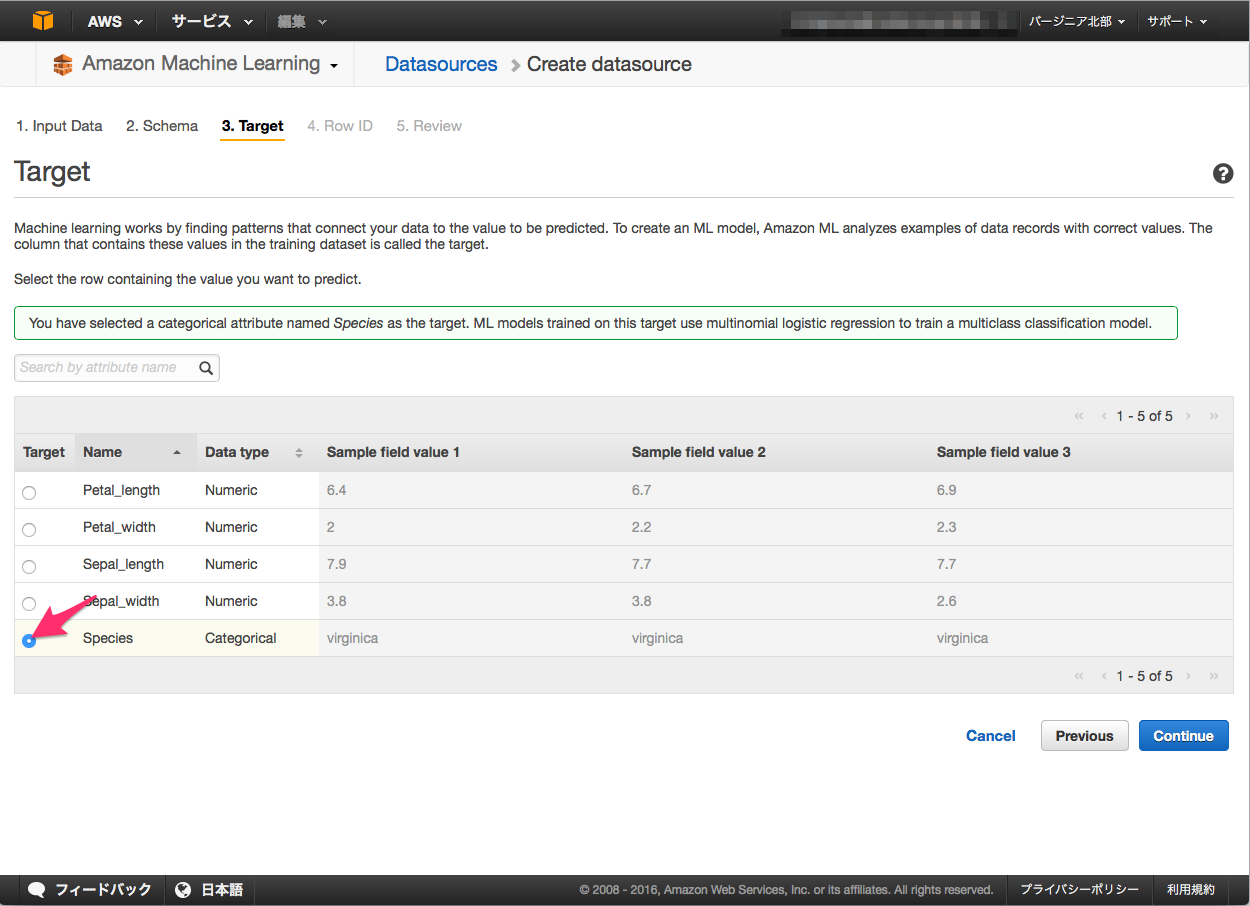
Target
分類する対象である"Species"を選択します。
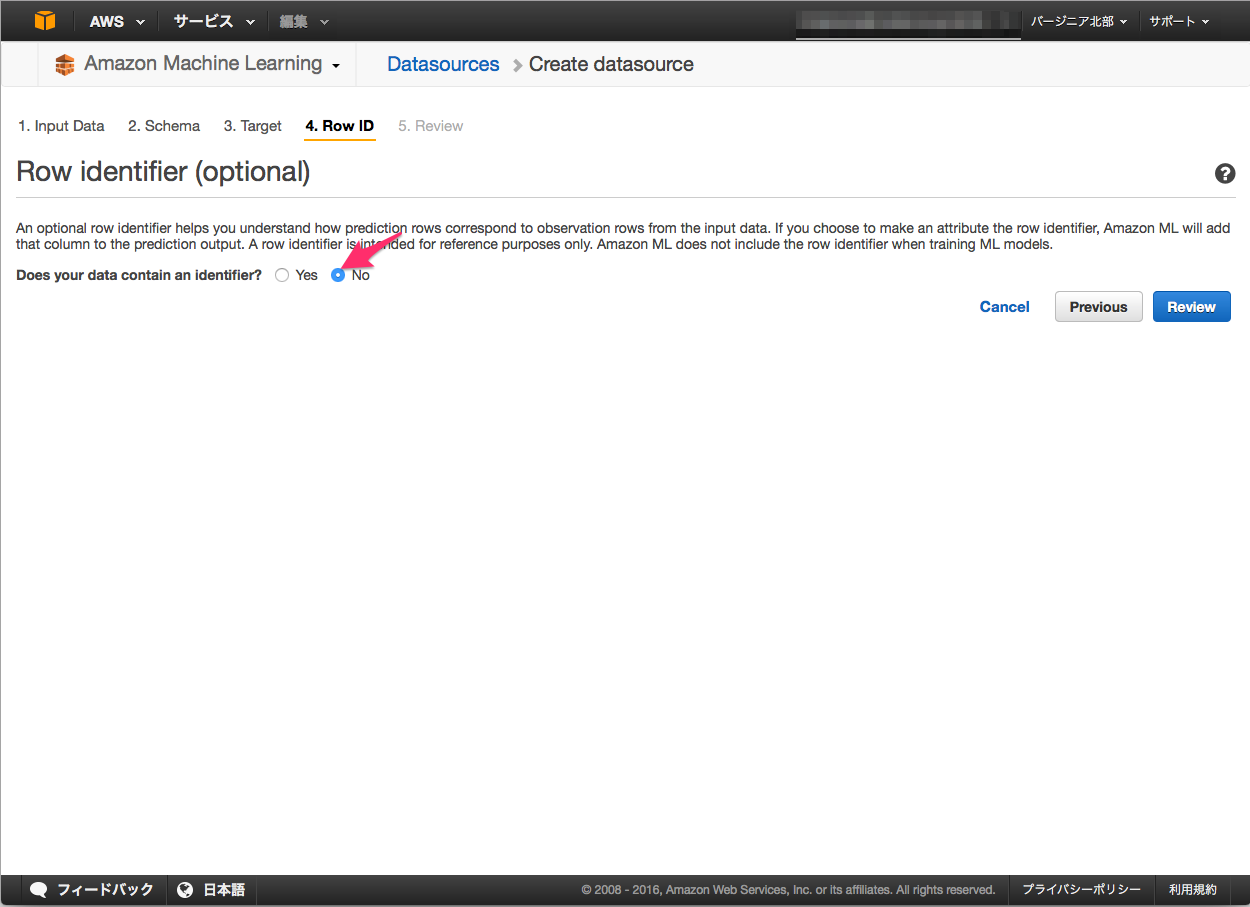
Row Identifier
"No" を選択します。
MLモデル作成
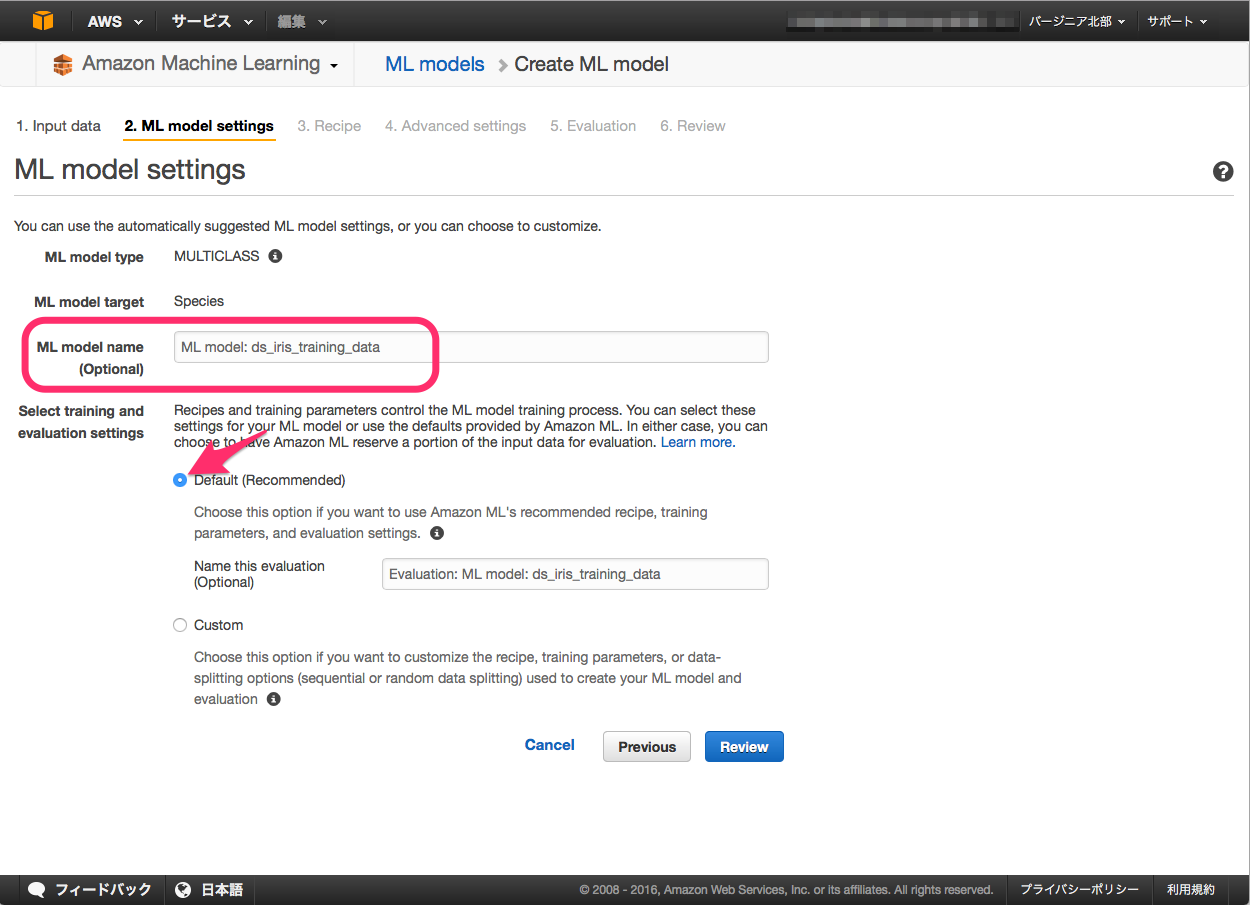
次に、トレーニングデータを使いMLモデルの作成を行います。
"ML model name" に任意の名前を入力し、"Select training and evaluation settings" は "Default" を選択します。
"Default" を選択した場合、始めの 70%のデータをトレーニングデータとして使い、残りの 30%のデータを評価用のデータとして使う設定となります。
分類実行
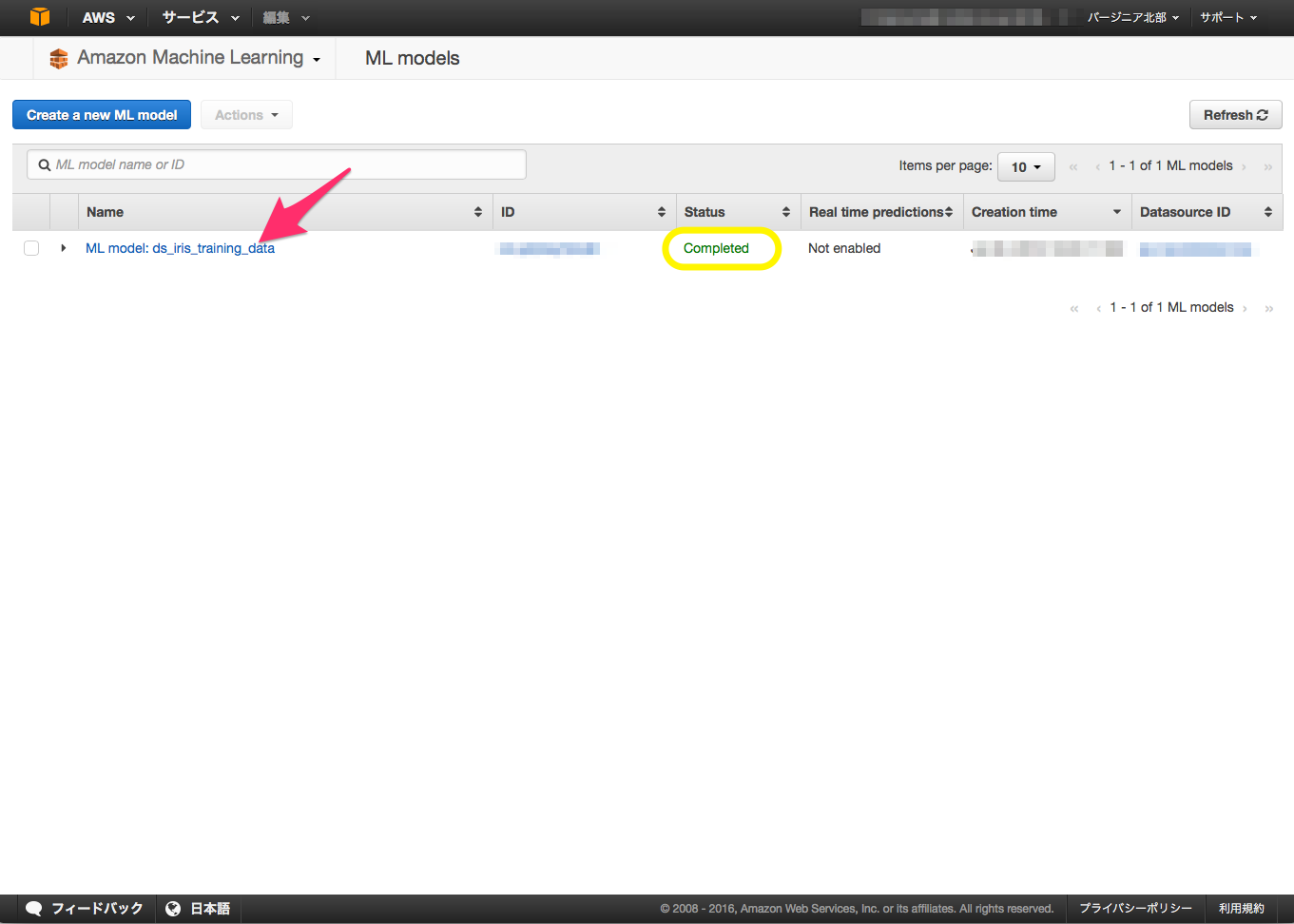
Amazon Machine Learning の処理が完了したら、先ほど作成したMLモデルを選択します。
"Try real-time predictions" を選択します。
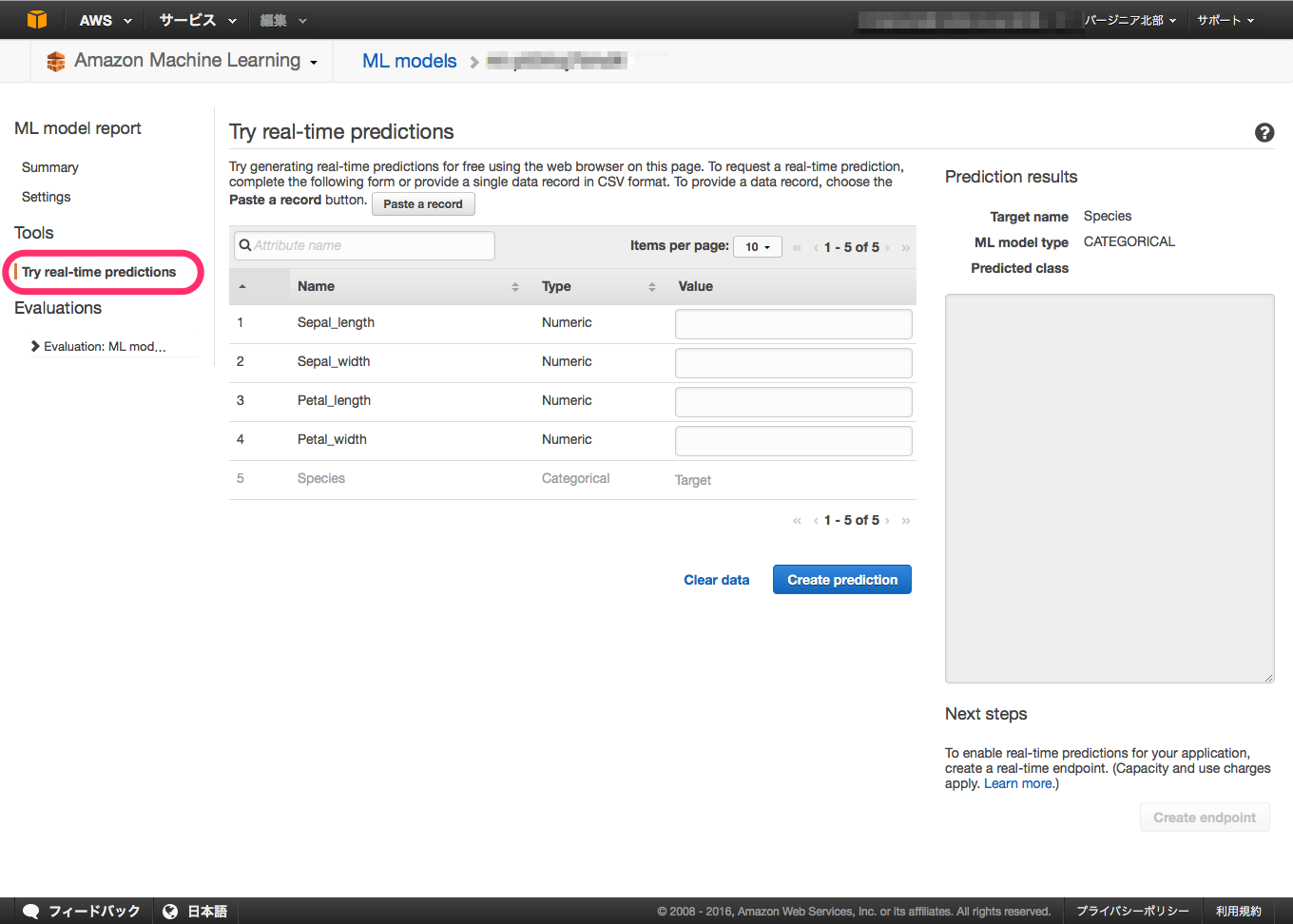
確認用テストデータとして以下を使用し、
各入力項目にテストデータを入力していきます。
※"Paste a record" から csv形式でデータを入力する事も可能です。

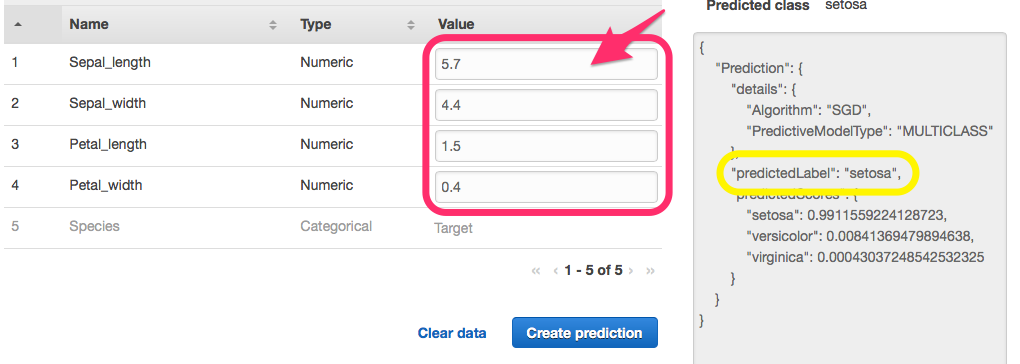
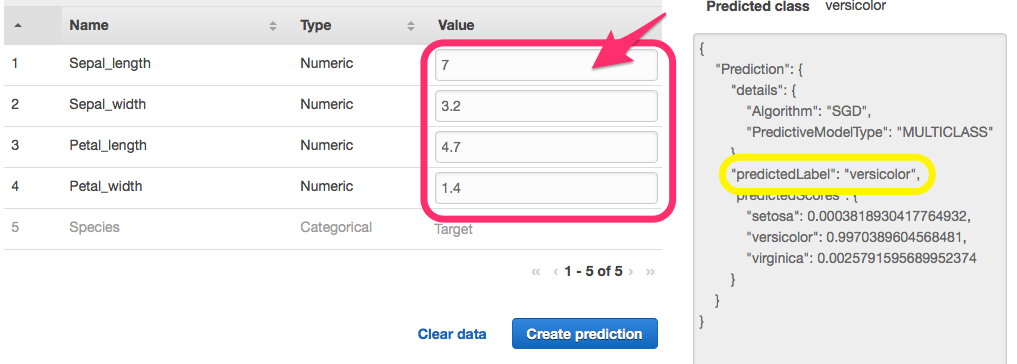
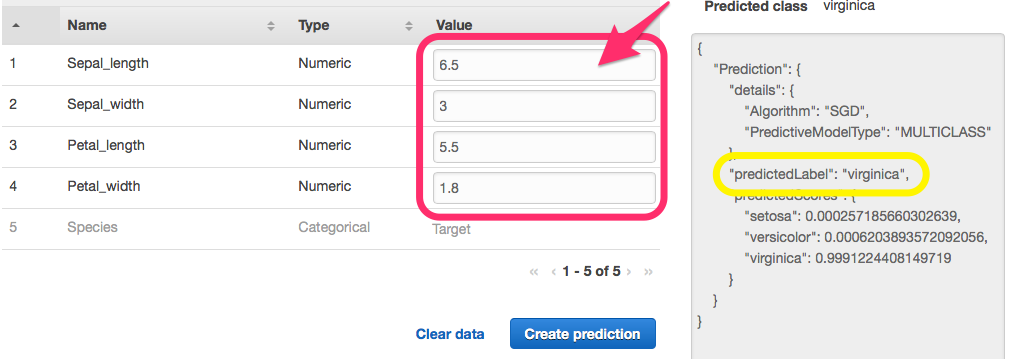
結果がJSON形式で出力され "predictedLabel" に分類結果が表示され、
Setosa、Versicolor、Virgínia に正しく分類されている事がわかります。
以上、今回は Amazon Machine Learning の多項分類を試してみました。