numpyのallについて(第二弾)
以前書いた記事での@shiracamus さんのコメントを元により良い記事を作成した(つもり)なのがこちらの記事です.
はじめに
numpyのallとはnumpyの配列の要素が全てTrueであればTrueを, そうでなければFalseを返す関数です. ドキュメントはこちら. ここではndarray.all()のことについて言及しています. ドキュメントにもあるようにnp.all()でも同じ意味であり, またnp.alltrue()という関数もあるようですが, githubのソースコードを見るとこの2つの関数は結局ndarray.all()を呼び出しているように見受けられたので今回は用いません.
numpyを用いた計算は非常に高速なので基本的にはnumpyで計算する方がpythonで直接記述するよりも高速です. しかし限定的な条件であればそれを覆すことができてしまったので紹介したいと思います.
またnumbaはJust In Time(JIT)コンパイルを行い高速化を実現するライブラリです. そのため一番最初に関数にアクセスするときにはコンパイルするため時間がかかる可能性があります. 具体的にはヒント(@numba.jit(numba.b1(numba.b1[:])))を与えた場合にはほとんどコンパイル時間がかかりませんが, 与えなかった場合(@numba.jitとしたとき)は数秒程度かかることがあります. コンパイル後の実行時間に関しては大きな違いはないです.
手法
最初にnumbaを使用しなかった時の以下の3つを比較します.
- for文で順に配列要素にアクセスする
- 組み込み関数のall(ドキュメントはこちら)
- numpyのall
1, 2は一見同じようですが異なることが結果を見ればわかります.
またnumbaを使用した時の時間も同様に調べたいと思います.
ソースコード
numbaを使用しない場合は@numba.jitの部分をコメントアウトすればいいです.
import numpy as np
import numba
import time
import matplotlib.pyplot as plt
# 組み込み関数を用いる
@numba.jit(numba.b1(numba.b1[:]))
def builtin(arr):
return all(arr)
# for文で記述する
@numba.jit(numba.b1(numba.b1[:]))
def use_for(arr):
for element in arr:
if not element:
return False
else:
return True
# numpyのallを用いる
@numba.jit(numba.b1(numba.b1[:]))
def np_all(arr):
return arr.all()
# 関数を引数としてテストしていく
def test(func):
elapsed_time = []
for arr_size in range(1000):
arr = np.ones(arr_size).astype(np.bool)
start = time.time()
func(arr)
end = time.time()
elapsed_time.append((end - start) * 1e6)
return elapsed_time[1:]
if __name__ == '__main__':
plt.plot(test(use_for), 'g', label='for')
plt.plot(test(builtin), 'r', label='built-in')
plt.plot(test(np_all), 'b', label='numpy')
plt.legend()
plt.xlabel('array size')
plt.ylabel('elapsed time[us]')
plt.show()
実行方法
python test.py
結果
numba不使用
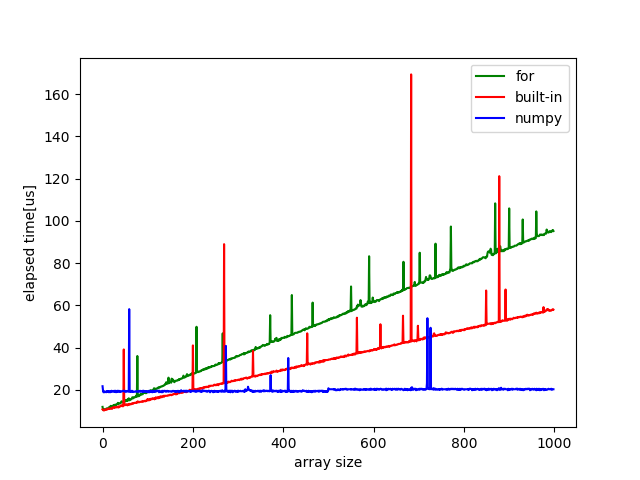
配列のサイズが1000以下のときの実行時間は図のようになります. ここからnumpyは配列のサイズが大きくなるほど有用であることがわかります. また組み込み関数の方がfor文で記述するよりは高速であるというのはPythonの性質という気がしますね. 200以下の場合はnumpyよりも他の2つの手法の方が高速であることがわかりました. この200という数字は環境に依る可能性があります.
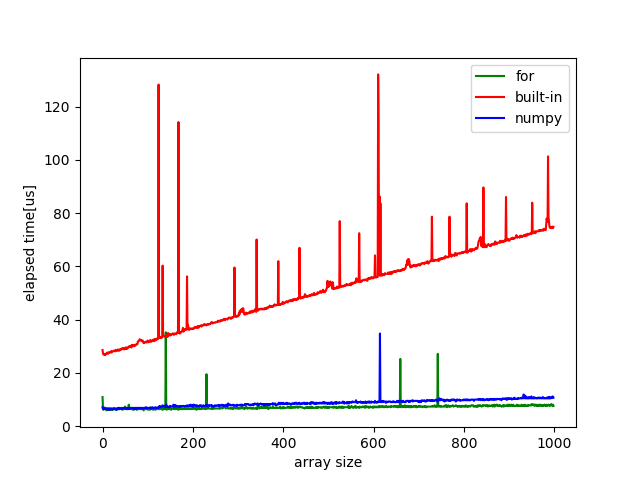
numba使用
一番最初のアクセスにかかる経過時間を除いてplotしています.すると図のような結果が得られました. 組み込み関数はnumbaでは高速化できないようですが, numpyのallとfor文は高速化するようです. また組み込み関数に関してはnumbaを使用しなかった時より遅くなっているのが興味深いです. 一方for文で記述した場合は高速であり, その高速さはnumpyを上回っています.
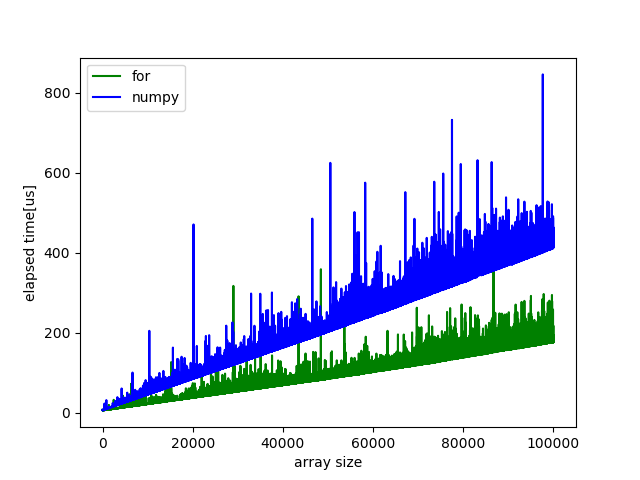
配列がより大きい場合は次の図のようになります. 組み込み関数は除いています. 依然for文の方が高速のようです.
結論
numba不使用
- 配列のサイズが小さい時は組み込み関数のallを用いた方が高速
- 配列のサイズが大きい時はnumpyのallを用いた方が高速
numba使用
- 配列のサイズにかかわらずfor文で記述するとよいが, 記述の手間や呼び出し回数などを考慮するとnumpyのallでも良い. ただし組み込み関数はダメ
- numbaは高速化に非常に貢献する
ここまで書いてCPUの使用に気を使っていなかったことに気づき, 改めて
taskset -c 0 python test.py
として実行しても同じようなグラフが得られたので問題ありませんでした.
最後に
@shiracamus さんに感謝.