この記事はfreee Advent Calendarの17日目の記事です。
自己紹介
こんにちは、@fuji_tipともうします。
freeeでは8月より、データサイエンティストとして従事しておりますが、8月まではfreee内でマーケティングやパートナーアライアンス等に従事をしていて、Wordpressやスプレッドシート、時にはパートナーさんとと対峙しながら、プロダクトを多くの人に広める仕事をしていました。
趣旨
多少プログラミングやSQLの経験はあるものの、
- エンジニアとしての技術も特筆してなく、
- コンサルのような課題整理能力もなく、
- 営業マンのような製品を売る能力もない、
- 専門家のような統計の知識もない、
ただプロダクトが好きだという気持ちしかないデータサイエンティストが、就任4カ月で学んだ、データ分析の心構えや短い時間で結果を出すためのデータ前処理方法などを、自戒の念も込めて書き連ねていきます。
一般的なデータサイエンティストは、技術面のスキルセットを持ち合わせたひとが多いですが、もしそのようなスキルセットを持ち合わせずにデータサイエンティスト/データ分析業務に従事するようになった方に読んで欲しいです。
心構え
まず手をつける
これが本当に重要だと感じます。仕事が降ってきたら、まず少しだけ手をつけて見立てを立てたり、必要なデータがどこにあるかを確認しておくことが重要です。
まだ設立して3年そこらの会社なので、そもそもデータがない!ということや、データがあっても取り出して加工するコストが半端無く高いことが多々あります。
まず、手を付けてどれくらい掛かりそうか見立てを立てるようにしています。
手順を作る
ただがむしゃらに目の前のデータと対峙していると、自分が何の数値を出そうとしていたのかわからなくなったり、一周回って同じ所に戻ってきたりしてしまいます。
まず一歩引いて、どのような構成のテーブルを作る必要があるのか、自分が出したいのはこの数値で、その数値を出すためには、どのようなステップを踏む必要があるのかを言語化し、どこかに書き留めたうえで作業を始めています
本は全体感を把握するために利用する
書籍はかなり重宝しますが、あまり本を開いて業務を行うということはしません。本はまず全体をさらっと読んで、そもそも自分が知りたいことによって何ができるのか?を把握するために読みます。
何ができるのか?がわかれば、あとはGoogleさんに聞けばなんとかなるし、調べて糧になった情報はがんがんEvernoteにあげて、前にみたことあると思った情報は基本Evernoteを検索するようにしています。
データ分析はデータ前処理が8割
freeeはWebアプリケーションなので、ほぼほぼデータは正規化されているものの、分析を行うためのテーブルを作るのに数百行のSQLを書くことも珍しくないです。その前処理が結構たいへんで、この数ヶ月間でゴリゴリSQL書いて、手元にあるSQLファイルの行数をカウントしてみると大体14,000行ぐらいでした。
分析を行っていて非常に重宝する手法/小技を僭越ながら紹介いたします。
ウィンドウ関数
freeeの分析環境はAmazon Redshiftなのですが、Redshiftにはウィンドウ関数という非常に便利な関数があります。それらを少しご紹介したいと思います。
ウィンドウ関数は指定した値でウィンドウ(窓)を作ると言う関数で、イメージとgroup byと似ているのですが、若干違う点があります。
例えば下記のようなテーブルがあったとき、user_id=2のvalue=2の前のvalueって何?であったり、user_id=3の最初のvalueは何?とか聞かれたときにどう出すかって結構面倒ですよね。
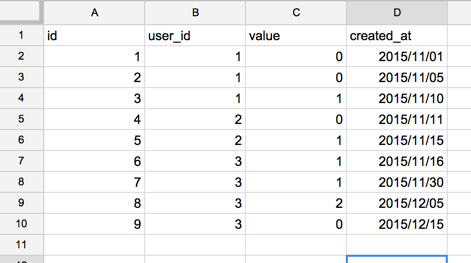
たぶん、普通に出そうと思うと、前社であれば、user_idごとに一個前のid値と結合させてvalue値をとってくるだとか、後者であれば、一旦user_idごとのid値の最小値をとって、そのid値のvalueに再度アクセスするというクエリを書かなければなりません。
ウィンドウ関数を使うと先ほどの質問には下記のように答えられます。
- user_id=2のvalue=2の前のvalueって何?
select
user_id,
value,
lag(value, 1) over (partition by user_id order by id) as pre_value
from dataset
where user_id = 2 and value = 2;
- user_id=3の最初のvalueは何?
select
user_id,
value,
first_value(value) over (partition by user_id order by id rows between unbounded preceding AND unbounded following) as first_value
from dataset
where user_id = 3;
これを使えばクエリが完結に書けるだけでなく、関数の名称的にも何を表しているのかが明らかなので、非常に読みやすくなっておすすめです。
中間(静的)テーブル / viewへの意識
結構同じようなクエリを使うことも多く、そのクエリが非常に返ってくるのが遅かったりすることがあります。そのようなクエリは如実に作業効率を下げます。
create viewコマンドでviewを作成することで、後からtableのように扱うことができたり、そもそもクエリと同じ構造の静的テーブルを作り、insert into XXX values(select * from YYY)のようなコマンドを打ってクエリの結果を静的テーブルに置いておくだけで、分析業務が格段に早くなります。
上記は、日次バッチなどで毎日実行するようにしておけば、毎日最新のデータで分析を行えるようになるので、ほんとライフチェンジングです。(テーブルのTRUNCATEは忘れずに)
スプレッドシートを活用する
何もSQLだけですべてのデータを加工する必要はありません。ある程度考えて、SQLだけで表現は難しいと思ったら、さっさと違うツールを使うべきです。(もちろんそれがスポットの分析ではなく、自動化して定常的にレポートしないといけないことだったら別ですが、、)
そんなとき利用できるのが、Googleスプレッドシートです。
(freeeはツールは基本クラウドで完結させる主義なので、Google Appsをフル活用しています)
正直SQLである程度手元扱えるサイズになったデータは、ほとんどスプレッドシートで運用することが多いです。(レポーティングにも楽なので)
まずは下記コマンドで、クエリ結果をcsvで保存します。
psql < file.sql > result.sql -A -F,
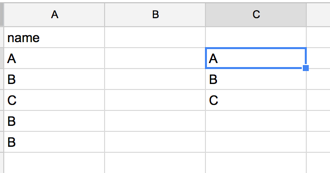
unique
この関数は結構利活用できて、指定した範囲の値のユニークなものだけを展開してくれる関数です。
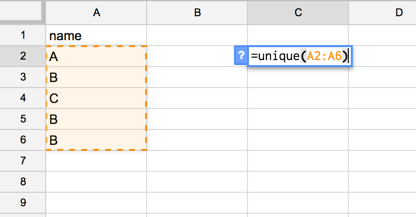
これを実行すると、下記のようになってユニークな列だけを取得することで、行数の比較などが簡単にできますし、値のユニークを取って、countif関数などで集計することで値の分布なども簡単にわかります。
googleスプレッドシートは簡易的なSQL文も使えるらしい
僕個人も最近知って非常に感銘を覚えたのですが、GoogleスプレッドシートではSQLも使えるらしく、今まで様々な関数をこねくり回していたのがSQL文で解決するみたいです。今後積極的に使ってみたいと思います。
詳しくはこちら。
あとはとにかくピボットテーブル
あとはとにかくピボットテーブル使えればなんとかなります。ほんとピボットテーブルは神です。これなかったらやっていけません。というか、日常の課題の8割ぐらいはピボットテーブルがあったら解決するんじゃないか(あと、集計されたデータに対してどのような示唆を与えるかも重要ですが)と思っています。
エンジニアの端末はマジで宝石箱
とくにエンジニアリング力がボトルネックになることがあるので、気兼ねなくfreeeのエンジニアに聞いています。また、エンジニア用の技術的な質問部屋がSlackにあるため、そこに質問を投げかけると1分もしないうちに返答が返ってきます。
時には、直接話をして質問したりするのですが、その時欠かさず行うのが、エンジニアの画面チェックです。エンジニアがどのようなツールを使っているのか、操作を行うときにどのようなショートカットキーを使っているのかをよくチェックしておき、自分の業務に活かすようにしています。
エンジニアは、同じ作業をとにかく嫌うので、さまざま自らの作業を早くするためのツール/コマンド/ショートカットを駆使している事が多く、それを間近で見ることは非常に勉強になります。
総括
なんだかんだすごくしんどいながらもデータサイエンティストを4カ月やってこれました。
それを支えて来たのは、新しいことを知りたいと思う好奇心と、プロダクトへの愛だと思っています。
データサイエンティストって聞こえはかっこいいですが、「最もプロダクトに触れない人」なんですよね。エンジニアはプロダクトを開発/改善するし、マーケティングはプロダクトを広める、セールスはプロダクトを売る、サポートはプロダクトの使い方を説明する。データサイエンティストはプロダクトを◯◯できないんです。
そうなると僕が行えるのはプロダクトへの愛を伝えること。エンジニアにもっと良い機能を開発してほしい、マーケティングに今まで広められなかった人にプロダクトを広めてほしい、セールスには今まで売れなかった人にプロダクトを売って欲しい、サポートにはより効率的により多くのユーザーにプロダクトを説明してほしいと思う気持ちが、**「プロダクトを使ってもらって楽になってもらいたい、そのユーザーを一人でも増やしたいという気持ち」**が、僕をデータと向き合わせるんだと感じています。
逆に言えば、データサイエンティストはどの職種の気持ちにもなれて、どの職種の行動でも変えられる力を持っているということで、そのやりがいは絶大なものがあります。
これからまだまだ学んでいかなければなりませんが、4カ月ちょっとで思った所感をつらつらと書き連ねてみました。
ご精読ありがとうございました。
さて明日は、freeeの頼れるアニキで"在社"の先駆者、freeeのUXチームを牽引する鳥貴族組組長@sousukeが午前0時をお知らせ致します。