こんにちは。古橋です。今日はいつものはてなブログから趣向を変えて、QiitaでTDアドベントカレンダー14日目の投稿です。
Hiveのクエリ結果をRDBに書き出したい
MapReduceはメモリに収まりきらないデータをJOINしたり集計したりできる信頼性の高いアーキテクチャですが、どうしても1発のクエリを実行するのに時間がかかるので、人間がいじりながら使う可視化ツールに直接繋ぎ込むには向いていません。
そこで Prestoを使って集計する 方法もありますが、やはりMapReduceの方が向いているケースもあります。例えば、
- Webサイトに一度は来てくれたのに、その後1週間アクセスのない人が、最後に見ていったページはどこだろう?
- 過去にアイテムAを買った人が良く買っている別のアイテムは何だろう? (バスケット分析のクエリ例)
といった、巨大テーブル同士のJOINや自己結合が必要なケースは、やはりMapReduce + Hiveの出番ですね。バッチ集計は時間がかかっても良いので、その結果はMySQLやRedshiftに保存しておこう、という使い方です。
そこで気になるのは、MapReduce + Hiveでバッチ解析した結果をMySQLやRedshiftなどに書き出しておいて、それらをインタラクティブな可視化ツールに繋ぎ込むことはできないだろうか? という方法です。そう、Treasure Dataなら簡単にできてしまいます…!
ココを押して、書き出し先DBの情報を入れるだけ:
MySQL & PostgreSQL への追記
さて、ときに数GBを超える集計結果を、MySQLやRedshiftに確実に投入するにはどうしたら良いか。
Treasure Dataのクエリの結果をMySQLやPostgreSQLに書き出すとき、いくつかのモードを選べます。そのうちappendモードでは、データをテーブルの末尾に追記します。ここで問題になるのは、書き込み中にエラーが起きたらどうなるのか? ということです。
一番困るのは、中途半端なデータが書き込まれて、一部のデータがダブってしまうケースです。特に大きなクエリ結果を書き込む場合、データの転送途中でエラーが発生することはあり得る問題です。
そこでappendモードでは、まず一時的なテーブルを作り、そこに少しずつデータを書き込んでいきます。すべてのデータの転送が完了したら、最後に一気に目的のテーブルに書き込みます:
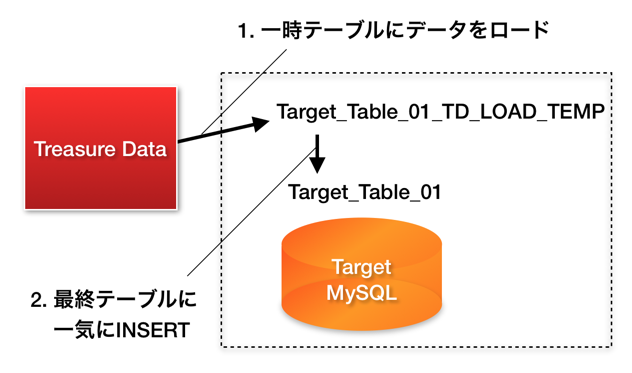
最後のINSERTはトランザクショナルに行われるので、中途半端なデータが書き込まれたままになることはありません。また、一時テーブルにはインデックスを作成しません。このため高速にロードすることができます。
あわせて読みたい:Something awesome in InnoDB -- the insert buffer
冪等な更新 — updateモード
データの追記は冪等な処理ではないので、どうしてもリトライ可能な処理ではありません。→リトライと冪等性のデザインパターン - Blog by Sadayuki Furuhashi
一方、PRIMARY KEY が重複したら上書きする update モードは、何度でもリトライできる信頼性の高い方法です。
updateモードでも、一時テーブルにデータをロードするまでは同じです。最後にINSERTする代わりに REPLACE INTO文を実行することで、重複した行を上書きします:
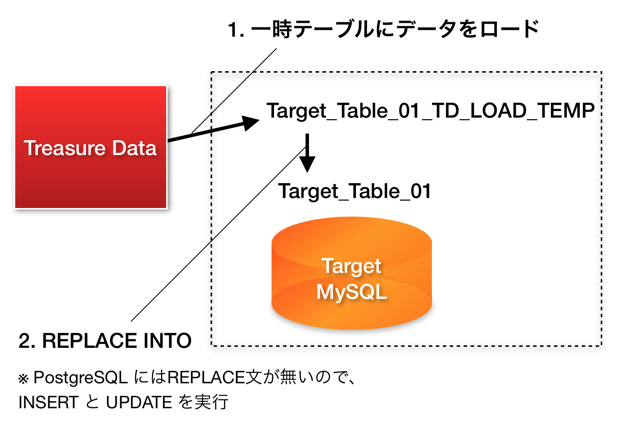
PostgreSQLではREPLACE文もMERGE文もサポートされていないので、PRIMARY KEYやUNIQUE KEYを指定する代わりにキー名を書き出し時にオプションで指定する必要がありますが、INSERTとUPDATEを発行することで同じ挙動を再現しています。
Redshiftの場合
さて、書き出し先がRedshiftの場合はどうするか?
Redshiftへ大規模データを高速かつ確実に書き出すには AWS Blog (Best Practices for Micro-Batch Loading on Amazon Redshift) で解説されているように、結構骨が折れる最適化が必要でした:
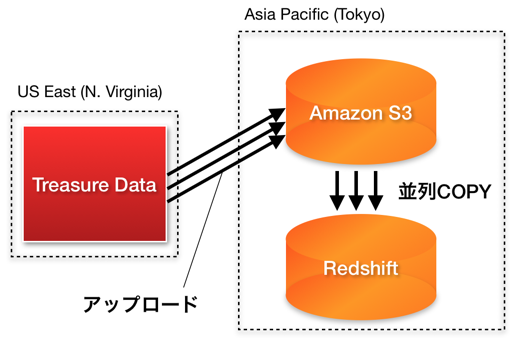
並列アップロード & COPY
まず、Treasure DataのサーバはUS East (N.Virginia)リージョンにあります。書き出し先のRedshiftがAsia Pacific (Tokyo)リージョンにあれば、Asia PacificリージョンのS3 bucketにデータをアップロードしていきます。
アップロードは小さなチャンクに区切って行われ、1チャンクのアップロードが完了次第、RedshiftへCOPYを始めます。この各チャンクのアップロードやCOPYは並列して実行されます。
ここで問題になるのは、S3へのデータ転送には無視できない確率でエラーが起きることです。そこで、このアップロードはリトライを実装してあり、確実にデータ転送されるまで2度、3度とリトライします。
長い文字列
また、Redshiftではtext型は自動的に varchar(256) に変換され、256より長い文字列を弾くようになっています。また、COPYするときに1行でも varchar(256) に収まらない文字列があると、COPY全体が失敗してしまいます。これは結構ハマりました。
Treasure Dataから結果を書き込むときは、まず文字列型に明示的に varchar(65535) を使うことで、長い文字列でも保存できるようにしています。また長すぎる文字列は長さを切り詰めることで、COPY全体が失敗してしまわないように防いでいます。
STATUPDATE OFF
さらに、デフォルトのRedshiftはCOPYが走るたびに統計情報の再計算を行って、データを再度圧縮したりします。これはかなり大きなオーバーヘッドで、毎回この処理が走ると通常のSELECT文にまで影響が出てしまいます。
そこでTreasure Dataからの書き出しでは、STATUPDATE や COMPUPDATE を無効化して高速にバルクロードし、統計情報の再計算が走るタイミングを自由にコントロールできるようにしています。
まとめ
Treasure Dataのクエリ結果をデータベースに書き出す機能の実装方法について紹介しました。
ここでは触れませんでしたが、HiveだけでなくPrestoのクエリ結果を書き出したり、書き出し先にもFTPサーバやTableau Server、Google Spreadsheet、Amazon S3 などを選ぶこともできます。
Treasure Dataでは、データベースや分散処理に興味があるエンジニアを募集中ですよ。