はじめまして。
Liaroというスタートアップでエンジニアインターンをしている@eve_ykと申します。
この度はLiaroが日々利用している技術について、理解をより深めること、積極的にアウトプットを行い知見を共有していくこと、あわよくばその道のプロフェッショナルな方から鋭いマサカリを投げてもらうことなど、様々な目的のために「ブログを書いていこうぜ!」ということになりました。
書ける内容は多くは無いですが、精一杯書きたいと思います。どうぞよろしくお願いいたします〜!
今回は、Convelutional Neural Network(CNN)を用いて顔画像識別器を作成してみます。
目的
顔分類というタスクはFacebookのDeepFaceやGoogleのFaceNetなどが人間並み(それ以上?)の精度を達成しています。
なぜ顔画像の識別にチャレンジするのか?
それを説明するために、次の画像をみていただきたいです。
はじめに、私がfacebookに登録しているアイコンです。

いい笑顔でしょう。
次に、こちらは2015年のM-1グランプリのファイナリスト、「スーパーマラドーナ」の田中一彦さんです。

!?!?!?
超そっくり!!!
今まで誰かに似ていると言われたことがなかった私にとって非常に衝撃的な経験でした。こりゃあもう自分と田中さんを見分ける識別器を作るしか無いだろうと。
くだらない理由です。
※今回は二値分類であり、データセットも大きくないのでつまらないタスクですが、ご容赦ください。
0. 開発環境を構築する
今回は以下の環境でテストしました。
- python 2.7.9
- numpy 1.10
- opencv 2.4
- chainer 1.6.0
- ProgressBar2 3.6.0
環境構築にはpyenvを使うとラクチンです。以下のリンクなどを参考にすると良いと思います。
numpy, opencvはanacondaで、chainerとProgressBar2はpipでインストールできます。
1. 学習に使用する画像を収集する。
次に学習に使用する画像を収集します。
機械学習をやる上で、使うデータを集めることが一番大変であると言っても過言ではありません。
今回の場合は 目的に対する需要が無さすぎるため 特に大変です。
頑張って手動で集めます。
ひとまず自分の画像が80枚、田中さんの画像が68枚集まりました。(自分のスマホやPC、facebookを漁ってもこれしか集まらなかったのに驚き)
この中からそれぞれ5枚ずつテスト用画像として避けておきます。残った75,63枚の画像を訓練用画像としてデータセットを作成していきます。
枚数が少なすぎますが、今回はお遊びなのでこのくらいにしましょう。
2. 画像の前処理を行う
顔分類を行うために、少しだけ画像の加工を行います。次の4ステップです。
- 画像の顔部分の切り取り
- リサイズ
- データ拡張(反転、回転)
- np.ndarray形式に変換
はじめに画像内の顔部分の領域を切り取ります。これにはOpenCVに用意されているHaar-Like特徴量を用いたカスケード型分類器を使います。分類器の学習などは今回はしません。
次に画像のサイズを64*64pxにリサイズします。chainerには入力画像のサイズに関わらず任意の固定長サイズの特徴量を計算できるSpatial Pyramid Poolingも実装されていますが、今回は使っていません。
その後にはデータの拡張を行います。画像分類を行うときは、元画像に対して反転、平行移動、回転、色調変化、平滑化などの処理で加工し、データ量を水増しすることをします。
今回は元画像を反転、回転させてデータ量を増やしています。
上記の処理をコーディングするとこんな感じになります。
# coding:utf-8
"""
指定フォルダ内の画像に存在する顔領域を抽出
画像の反転と回転させて拡張
"""
import os
import glob
import argparse
import cv2
import numpy as np
CASCADE_PATH = "/path/to/haarcascade/haarcascade_frontalface_alt.xml"
cascade = cv2.CascadeClassifier(CASCADE_PATH)
def detectFace(image):
"""
顔画像部分を抽出
"""
image_gray = cv2.cvtColor(image, cv2.cv.CV_BGR2GRAY)
facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=3, minSize=(50, 50))
return facerect
def resize(image):
"""
画像のリサイズ
"""
return cv2.resize(image, (64,64))
def rotate(image, r):
"""
画像の中心を軸にをr度回転
"""
h, w, ch = image.shape # 画像の配列サイズ
M = cv2.getRotationMatrix2D((w/2, h/2), r, 1) # 画像を中心に回転させるための回転行列
rotated = cv2.warpAffine(image, M, (w, h))
return rotated
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='clip face-image from imagefile and do data argumentation.')
parser.add_argument('-p', required=True, help='set files path.', metavar='imagefile_path')
args = parser.parse_args()
# 出力用ディレクトリがない場合は作成
result_dir = args.p + "_result"
if not os.path.exists(result_dir):
os.makedirs(result_dir)
face_cnt = 0
# jpgファイル取得
files = glob.glob(args.p+"\*.jpg")
print args.p+"\*.jpg"
for file_name in files:
# 画像のロード
image = cv2.imread(file_name)
if image is None:
# 読み込み失敗
continue
# -12~12度の範囲で3度ずつ回転
for r in xrange(-12,13,4):
image = rotate(image, r)
# 顔画像抽出
facerect_list = detectFace(image)
if len(facerect_list) == 0: continue
for facerect in facerect_list:
# 顔画像部分の切り抜き
croped = image[facerect[1]:facerect[1]+facerect[3],facerect[0]:facerect[0]+facerect[2]]
# 出力
cv2.imwrite(result_dir+"/"+str(face_cnt)+".jpg", resize(croped))
face_cnt += 1
# 反転画像も出力
fliped = np.fliplr(croped)
cv2.imwrite(result_dir+"/"+str(face_cnt)+".jpg", resize(fliped))
face_cnt += 1
このコードで出力される画像群には、写真に写っている他の人の顔画像や誤検出された画像が含まれているので、またまた手動で不要な画像をひとつずつ取り除いていきます。
出来上がったデータセットがこちらです。
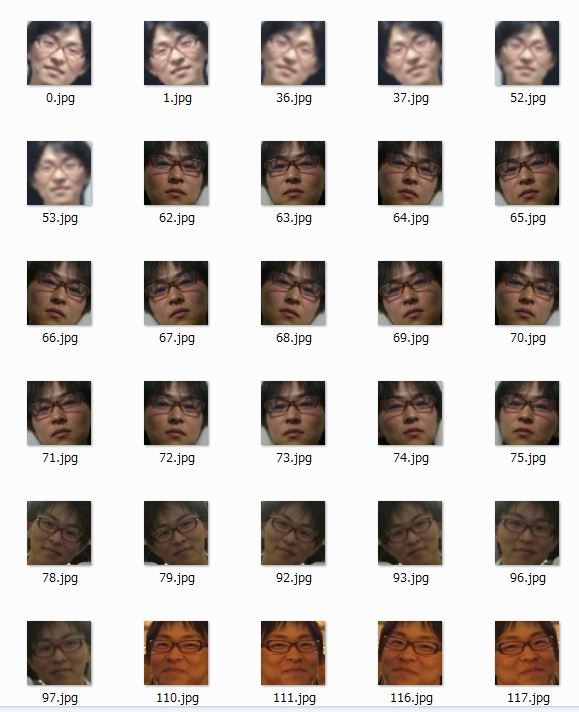
…。
キモチワルイですね。
訓練用画像として、自分の画像が393枚、田中さんの画像が187枚できました。
最後に、chainerで扱うためにnp.ndarrayの形式に変換したデータを作成します。
chainerで用いるVariableクラスへはnp.ndarray型のデータが入力されると想定されているので、事前にその形式に変換しておきます。この時、PythonのOpenCVで扱う画像の形式とchainerのCNNで扱う画像の形式が異なっているので注意が必要です。
OpenCV => (height, width, channel)
chainer => (channel, height, width)
以下のコードで変換します。
# coding:utf-8
import os
import sys
import argparse
import glob
import cv2
import numpy as np
"""
CNNで使用するデータセットを作成する
画像をCNNの入力形式に変換する
データセットの形式は以下のようにする
- dataset
- train
- [class_name_1]
- hogehoge.jpg
- foofoo.jpg
- ...
- [class_name_2]
- hogehoge.jpg
- ...
- ...
- test
- [class_name_1]
- hogehoge.jpg
- ...
- ...
"""
def transpose_opencv2chainer(x):
"""
opencvのnpy形式からchainerのnpy形式に変換
opencv => (height, width, channel)
chainer => (channel, height, width)
"""
return x.transpose(2,0,1)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='CNN用データセット作成')
parser.add_argument('--input_path', required=True, type=str)
parser.add_argument('--output_path', required=True, type=str)
args = parser.parse_args()
# jpgファイル一覧取得
train_files = glob.glob(args.input_path+"/train/*/*.jpg")
test_files = glob.glob(args.input_path+"/test/*/*.jpg")
# 出力用ディレクトリがない場合は作成
if not os.path.exists(args.output_path):
os.makedirs(args.output_path)
train_data = []
train_label = []
test_data = []
test_label = []
label_dict = {}
# 訓練データ作成
for file_name in train_files:
image = cv2.imread(file_name)
if image is None:
# 読み込み失敗
continue
# ディレクトリ構造からクラス名を取得
class_name = file_name.replace("\\", "/").split("/")[-2]
# chainer用形式に変換
image = transpose_opencv2chainer(image)
train_data.append(image)
train_label.append(label_dict.setdefault(class_name, len(label_dict.keys())))
# データ作成・保存
train_data = np.array(train_data)
train_label = np.array(train_label)
np.save(args.output_path+"/train_data.npy" , train_data)
np.save(args.output_path+"/train_label.npy", train_label)
for file_name in test_files:
image = cv2.imread(file_name)
if image is None:
# 読み込み失敗
continue
# ディレクトリ構造からクラス名を取得
class_name = file_name.replace("\\", "/").split("/")[-2]
# chainer用形式に変換
image = transpose_opencv2chainer(image)
test_data.append(image)
test_label.append(label_dict.setdefault(class_name, len(label_dict.keys())))
# データ作成・保存
test_data = np.array(test_data)
test_label = np.array(test_label)
np.save(args.output_path+"/test_data.npy" , test_data)
np.save(args.output_path+"/test_label.npy" , test_label)
少し短いですが今回はここまでにします。
次回は識別器のモデルを記述し、実際に顔判別の学習・評価を行いたいと思います。
お楽しみに!
参考
Pythonで機械学習アプリケーションの開発環境を構築する - qiita
https://github.com/mitmul/chainer-cifar10