Deep Feature Interpolation for Image Content Changes
Deep Feature Interpolation(DFI)は、画像に特定の属性(例えば「笑顔」「年配」「あごひげが生えている」)を持たせるための手法です。
特定の属性をもたせる手法としては、"Autoencoding beyond pixels using a learned similarity metric"のようなGenerative Adversarial Network(GAN)を使った手法が知られていますが、DFIはGANとは異なるアプローチをとっています。
論文は https://arxiv.org//abs/1611.05507 にあります。
概要
"A Neural Algorithm of Artistic Style"などで知られているように、画像をCNNに入力して得られたFeature Map(中間レイヤー出力)から、画像を復元することができます。画風を変換するアルゴリズムに解説があるので、こちらのブログを読むと理解が深まると思います。
DFIでは、「画像から得られたFeature Map」に属性ベクトルを加えることで「特定の属性を持たせた画像のFeature Map」を求めます。そして求めたFeature Mapから「特定の属性持たせた画像」の復元を行います。
画像変換の手順
画像変換は以下の手順で行います。
- VGG 19-layer modelなどの、画像認識に使うCNNを用意します。
- 変換元の画像(元画像と呼びます)を用意します。
- 元画像にもたせたい属性(目的の属性と呼びます)を決めます。
- 以下の画像の集合をそれぞれ集めます。
- 元画像に近く、かつ目的の属性をもつ画像(ターゲット集合と呼びます)
- 元画像に近く、かつ目的の属性をもたない画像(ソース集合と呼びます)
- ターゲット集合に含まれる画像をCNNに入力し、Feature Mapを得ます。その平均$\bar{\phi}^{t}$を計算します。
- 同様にソース集合に含まれる画像についても、CNNのFeature Mapの平均$\bar{\phi}^{s}$を計算します。
- 属性ベクトル$w = \bar{\phi}^{t} - \bar{\phi}^{s}$を計算します。
- 元画像$x$をCNNに入力し、Feature Map $\phi(x)$を得ます。
- 元画像から得たFeature Mapと属性ベクトルの重みつき和 $\phi(x) + \alpha w$ を計算します。
- 変換後の画像 $z$ の最適化を行います。$z$ をCNNに入力した時に得られるFeature Map $\phi(z)$ が $\phi(x) + \alpha w$ に近づくように最適化を行います。
論文で使用していたアルゴリズムの図を載せます。Step番号は論文中のもので本記事とは異なります。
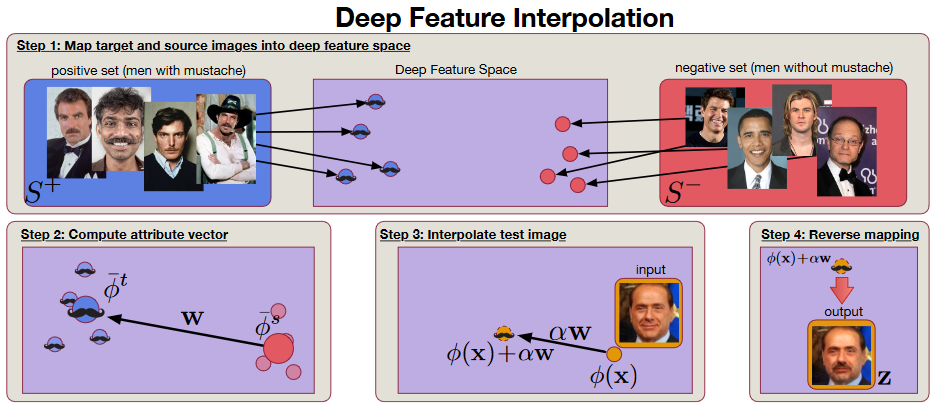
実装
Chainerで実装を行いました。
https://github.com/dsanno/chainer-dfi
DFIで人を笑顔にする
DFIを使って顔画像に笑顔属性を持たせてみます。
Labeled Faces in the Wild データセットを使う
論文ではLabeled Faces in the Wild(LFW)データセットの画像を使ってFeature Mapを計算していました。LFWには13,000枚以上の顔画像と、顔画像の"Male", "Smiling"などの属性を数値化したベクトルが含まれています。
論文ではソース・ターゲット集合として使う類似画像として、元画像との共通属性が多い画像を選択していました。
同様の方法でLFWに含まれる画像を笑顔にしてみます。
結果は以下のようになりました。
| 元画像 | 笑顔 | 笑顔+口を開ける |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
パラメータなどは以下の通りです。
- 属性ベクトルの重み$\alpha$は0.4
- 元画像は大体顔部分を切り抜くようにクリッピング
- ターゲット・ソース集合の画像として元画像の属性値とユークリッド距離が小さい属性値をもつ画像を選択
- "笑顔"はターゲット集合としてSmiling属性が0.5以上のもの、ソース画像としてSmiling属性が-0.5未満のものを選択
- "笑顔+口を開ける"はターゲット集合としてSmiling属性0.5以上かつMouth_closed属性が-0.5未満、ソース画像としてSmiling属性が-0.5未満かつMouth_Closed属性が0.5以上のものを選択
- ターゲット集合とソース集合の画像はそれぞれ100枚まで
自分で用意した画像を使う
ぱくたそで配布している画像を変換してみました。

ちょっと緊張が感じられる表情を笑顔にしてみます。重みパラメータ $\alpha$ は0.1~0.5の範囲で変更しました。重みが大きすぎると画像の歪みも大きくなります。
| 重み0.1 | 重み0.2 | 重み0.3 |
|---|---|---|
 |
 |
 |
| 重み0.4 | 重み0.5 | |
 |
 |
- 顔画像データセットにはCelebAデータセットを使用
- 元画像の属性ベクトルが不明なので、以下のようにしてソース・ターゲット集合を選択しました
- "Young"属性がポジティブ、"Male"属性がネガティブといったように、元画像の属性を手動で決める
- データセットが持つ属性情報をもとに元画像と属性が共通する画像を選択
- 目的の属性がポジティブな画像をターゲット、ネガティブな画像をソースに含める
本当に属性を持たせているのか?
顔画像を笑顔にできることを上で示しましたが、この手法は本当に画像に属性を付与しているのでしょうか?
私はNoだと考えています。
使用したCNNは画像認識用途のもので、そのFeature Mapは特定の属性について学習しているわけではありません。
そのためソースとターゲット集合のFeature Map差分を使って生成できるのは「ソース・ターゲット間の平均的な画像差分」です。
属性が笑顔の場合は、元画像に「笑っていない顔と笑顔との画像差分」を加えることで笑顔画像を生成していることになります。
画像差分を加えているだけなので、元画像とソース・ターゲットの画像とで顔のパーツ配置も揃える必要があります。
実際、元画像とソース・ターゲット画像とで顔の位置がそろっていないと変な位置に唇が浮かび上がるということがありました。
使用した顔画像データセットにはパーツ配置情報や顔の向きの属性は含まれていませんが、画像内の顔の位置・大きさはアライメントされているので大体うまくいっているのだと思います。
より自然な画像変換を行うためには、顔のパーツ配置も考慮してソース・ターゲット画像を選択する必要があると思います。
GANベースの手法との比較
論文では生成画像についてGANベースの手法と比較も行っています。
実際に生成した画像については論文をご覧ください。
ここでは手法の特性の比較を行います。
| DFI | GANベース | |
|---|---|---|
| 学習済みモデルが必要か | 必要 | 不要 |
| 事前学習 | 不要 | 画像生成モデルを学習する必要がある |
| 1枚の画像生成時間(GPU使用時) | 数十秒 | 1秒もかからない |
| 画像生成時に必要な画像 | 画像生成時に似た画像が数十枚~百枚くらい必要 | なし |
実装について
論文の記述と今回使用した実装との差分について書いておきます。
実装の細かい部分に興味がない人はとばしてかまいません。
Feature mapを正規化するか否か
論文には"We use the convolutional layers of the normalized VGG-19 network pre-trained on ILSVRC2012, "と書かれており、Feature Mapを正規化していることがわかります。
Feature Mapの正規化については"Understanding Deep Image Representations by Inverting Them"で書かれていますが、Feature MapをL2 normで割ることを指します。
以下の理由から正規化は行いませんでした。
- 正規化しなくても動作している
- 正規化する場合にはFeature Mapに関する損失(二乗誤差)を$10^6$~$10^8$倍する必要があり、調整が面倒だと感じた
Feature mapを結合するか否か
論文ではVGG-19 layersの中間レイヤーのうちconv3_1, conv4_1, conv5_1をFeature Mapとして使っています。
この点は今回の実装も同じです。
さらに論文には"The vector $\phi(x)$ consists of concatenated activations of the
convnet when applied to image x"とあり、複数のFeature Mapを結合していることがわかります。
ただFeature Mapを結合しなくても動作したので今回の実装では結合しませんでした。
属性ベクトルの正規化
論文では属性ベクトル$w = \bar{\phi}^{t} - \bar{\phi}^{s}$を、$w / ||w||$とL2正規化して使用しています。
これは属性の重み係数$\alpha$が元画像、ソース・ターゲットの選択についてロバストにする(同じ$\alpha$を使いまわせるようにする)ためです。
しかしながら属性ベクトルの正規化はFeature Mapが正規化されている場合のみに有効です。
Feature Mapを正規化していない場合には属性ベクトルの長さをFeature Mapの大きさを考慮して決めるのが自然なので実装では$w / ||w||$に元画像のFeature MapのL2 normを掛けたベクトルを属性ベクトルとしました。
参考文献
- Paul Upchurch et al. "Deep Feature Interpolation for Image Content Changes", 2016
- A. B. L. Larsen et al. "Autoencoding beyond pixels using a learned
similarity metric", 2015 - Leon A. Gatys et al. "A Neural Algorithm of Artistic Style"
- A. Mahendran and A. Vedaldi. "Understanding deep image
representations by inverting them",
2015 - 画風を変換するアルゴリズム