概要
Chainerを使って画像のキャプション生成を実装しました。画像を入力するとその説明文を生成します。ソースコードは以下にあります。
https://github.com/dsanno/chainer-image-caption
以下の論文のアルゴリズムを使いました。
Show and tell: A neural image caption generator
すでにChainerでキャプション生成を実装されている方もいたので、そちらも参考にしました。
Image caption generation by CNN and LSTM ~ Satoshi's Blog from Bloomington
キャプション生成モデル
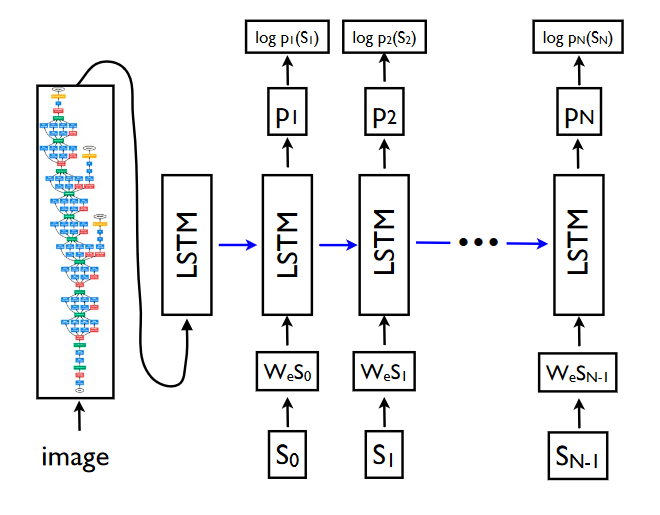
論文で使用するキャプション生成モデルは大きく分けて3つのネットワークで構成されています。
- 画像をベクトルに変換する${\rm CNN}$
${\rm CNN}$には、GoogleNetやVGG_ILSVRC_19_layers等の画像分類用の既存のモデルを使います。 - Word embedding(単語からベクトルへの変換)$W_e$
- ベクトルを入力し、次の単語の出現確率を出力する${\rm LSTM}$
実装に使用したモデル
論文そのままの実装だとGPUメモリが足りなかったので変更して実装しました。
- 画像をベクトルに変換する${\rm CNN}$ (入力: 224 x 224 x 3次元 出力: 4096次元)
- 画像の特徴ベクトルを${\rm LSTM}$の入力に変換する行列$W_I$ (入力: 4096次元 出力: 512次元)
- Word embedding(単語からベクトルへの変換)$W_e$ (入力: 単語ID 出力: 512次元)
- ${\rm LSTM}$ (入力 512次元 出力: 512次元)
- ${\rm LSTM}$の出力を単語の出現確率に変換する$W_w$ (入力 512次元 出力: <単語数>次元)
以降の論文のモデルに基づいて説明しますが、実際に使用したモデルに置き換えるのは難しくないと思います。
モデルの学習
学習対象は$W_e$と${\rm LSTM}$です。${\rm CNN}$は学習済みのパラメータをそのまま使用します。
学習データは画像$I$と単語列$\{S_t\} (t = 0...N)$です。ただし$S_0$は文の開始記号<S>、$S_N$は終端記号</S>です。
以下のように学習を行います。
- 画像$I$を${\rm CNN}$に入力し、特定の中間層の出力を特徴ベクトルとして取り出す。
- 特徴ベクトルを${\rm LSTM}$に入力する。
- $S_t$を$t=0$から$N-1$まで順に入力し、それぞれのステップで$p_{t+1}$を得る。
- $S_{t+1}$を出力する確率$p_{t+1}(S_{t+1})$から求まるコストを最小化する
論文ではコスト関数として負の対数尤度
L(I,S)=-\sum_{t=1}^{N}\log p_t(S_t)
を使っていましたが、私の実装ではsoftmax cross entropyを使いました。
また論文ではパラメータ更新をmomentumなしのSGDで行っていましたが、私の実装ではAdam(パラメータはAdam論文の推奨値)を使いました。
対数尤度とSGDによる実装も試してみましたが、学習の収束が遅くなるだけでメリットがなさそうに思えるのですが、なぜ論文で採用しているのか理解できていません。
また論文と同様にdropoutを使いました。
論文ではさらに"ensembling models"を使用とあったのですが、具体的な実装方法がわからなかったため実装していません。
キャプションの生成
学習済みのモデルを使ってキャプションを生成するときには、以下のように単語の出現確率を先頭から順に求め、単語の出現確率の積が高い単語列をキャプションとします。
- 画像を${\rm CNN}$に入力し、特定の中間層の出力を特徴ベクトルとして取り出す。
- 特徴ベクトルを${\rm LSTM}$に入力する。
- 文の開始記号<S>を$W_e$を使ってベクトルに変換し、${\rm LSTM}$に入力する。
- ${\rm LSTM}$の出力から単語の出現確率がわかるので、上位$M$個の単語を選ぶ。
- 1つ前のステップで出力した単語を$W_e$を使ってベクトルに変換し、${\rm LSTM}$に入力する。
- ${\rm LSTM}$の出力から、これまでに出力した単語の確率の積を計算し、上位M個の単語列を選ぶ。
- 5.と6.を単語の出力が終端記号</S>になるまで繰り返す。
今回の実装では$M=20$としました
学習データ
学習データにはMSCOCOのAnnotationつき画像データセットを使用しました。
ただしMSCOCOで配布されているデータではなく、以下のサイトで配布しているデータを使わせて頂きました。
このサイトで配布しているのはVGG_ILSVRC_19_layersを使って画像から抽出した特徴ベクトルのデータと、Annotationの単語列のデータです。
このデータを使うことで画像から特徴ベクトルを抽出する手間と、Annotationの前処理(文を単語に分割)の手間を省くことができました。
Deep Visual-Semantic Alignments for Generating Image Descriptions
以下のサイトによると、MSCOCOのAnnotationデータは表記ゆれが激しく(文の最初が大文字だったり小文字だったり、ピリオドがあったりなかったり)扱うのが難しいようです。
Microsoft COCO ( MS COCO )データセットについてまとめてみた ~ 人工知能の話題でご飯3杯いける
学習データに含まれる単語のうち、5回以上出現する単語のみを用い、それ以外は未知語として学習しました。
生成キャプションの評価
生成したキャプションを評価する指標として、BLEU、METEOR、CIDERといったものがあるそうなのですが、今回は指標の計算までは行いませんでした。
キャプション生成例
PublicDomainPictures.netからダウンロードしたパブリックドメインの画像を使ってキャプション生成を行いました。
生成した文字列のうち上位5個を載せます。
時計
 ```
a clock on the side of a building
a clock that is on the side of a building
a clock on the side of a brick building
a close up of a street sign on a pole
a clock that is on top of a building
```
```
a clock on the side of a building
a clock that is on the side of a building
a clock on the side of a brick building
a close up of a street sign on a pole
a clock that is on top of a building
```
交通整理中?の警察官
 ```
a man riding a skateboard down a street
a man riding a skateboard down a road
a man riding a skateboard down the street
a man riding a skateboard down a sidewalk
a man riding a skateboard down the side of a road
```
スケートボード。。。?
```
a man riding a skateboard down a street
a man riding a skateboard down a road
a man riding a skateboard down the street
a man riding a skateboard down a sidewalk
a man riding a skateboard down the side of a road
```
スケートボード。。。?
テニスラケットをもった女性
 ```
a woman holding a tennis racquet on a tennis court
a man holding a tennis racquet on a tennis court
a woman holding a tennis racquet on a court
a woman holding a tennis racquet on top of a tennis court
a man holding a tennis racquet on a court
```
2番目と5番目が"man"となっていますが、たまにmanとwomanを間違えることがあります。
```
a woman holding a tennis racquet on a tennis court
a man holding a tennis racquet on a tennis court
a woman holding a tennis racquet on a court
a woman holding a tennis racquet on top of a tennis court
a man holding a tennis racquet on a court
```
2番目と5番目が"man"となっていますが、たまにmanとwomanを間違えることがあります。
リビングのソファ
 ```
a cat laying on top of a bed
a cat sitting on top of a bed
a cat sitting on top of a couch
a black and white cat laying on a bed
a cat laying on a bed in a room
```
クッションを猫と誤認識しているようです。
```
a cat laying on top of a bed
a cat sitting on top of a bed
a cat sitting on top of a couch
a black and white cat laying on a bed
a cat laying on a bed in a room
```
クッションを猫と誤認識しているようです。
正しく生成できているものもあれば、明らかに間違っているものもありました。
参考文献
- Oriol Vinyals, Alexander Toshev, Samy Bengio, et al. Show and tell: A neural image caption generator . 2015
- Diederik Kingma, Jimmy Ba Adam: A Method for Stochastic Optimization. 2014
- MSCOCO
- Deep Visual-Semantic Alignments for Generating Image Descriptions
- Image caption generation by CNN and LSTM ~ Satoshi's Blog from Bloomington
- Microsoft COCO ( MS COCO )データセットについてまとめてみた ~ 人工知能の話題でご飯3杯いける