はじめに
私がQ学習をやろうと思ったのはちょっと金融取引に機械学習使えないかな・・・というのがはじまりでした。Q学習で迷路ってちょっとググると国内外では何番煎じかわかりませんが自分的メモということで。で、VBAだったらQiita内ではいないだろう・・・と思ってたらいらっしゃいましたのでこちらも先駆的ではないのですが、セルをそのまま迷路のグラフィックに使えるのでExcel VBAでやることにしました。
迷路について
迷路については言うまでもないですね。調べるといろいろタイプがあるようですが、今回の迷路は棒倒し法で生成します。ランダム生成で生成するたびに違う迷路になるようにします。
Q学習
上記の通り、何番煎じかわりませんが自分の言葉で記すことにします。
とりあえず、わかりやすくで言えばWidipediaが手軽です。で、簡単に言えばQ学習は迷路を解くという問題では最終結果をスタート地点まで伝搬さ、経路を特定する学習アルゴリズムです。
多くの方がすでに書かれている事ですが、Q学習では以下の式をつかむことがポイントになります。
$$Q(s_t,a) ← Q(s_t,a)+α[r_{t+1}+γ\max_pQ_(s_{t+1},p)-Q(s_t,a)]$$
$Q$ : Q値 , $s_t$ : tにおける状態 , $a$ : $s_t$での行動 , $p$ : $s_{t+1}$での行動 , $α$ : 学習率 , $γ$ : 割引率 $r_{t+1}$ , $s_{t+1}$に移行した時の報酬
パッと見て気づく点として、$Q(s_t,a)$をループごとに更新していく感じでプログラム組めるんだろうなというところだと思います。ちょっととっつきにくいのは$s_{t+1}$とか$r_{t+1}$ってどうやって組み込むのよ?ってとこかと思います(ってそれは私だけだろうか・・・)。
Q学習の学習効果の伝播
報酬というものは、迷路を解くという問題においてはゴールして初めてもらえるもので、それがゴールを繰り返すごとにスタート地点まで伝搬するようになります。迷路の形状全体を2次元的に認識させて、進みながらゴールに近づくにつれて報酬を与えるような感じではありません(私は最初、そう勘違いしていた・・・)。一度ゴールして得た報酬を徐々にスタートまで伝搬させるわけですね。よって、迷路の規模、報酬の大きさや学習率・割引率にっよってはスタート地点に伝搬しないくらい小さい値になってしまうこともあります。何度もループさせれば良いのですが、このくらいの規模でも変数型のLSBを割り込むような数値を繰り返し更新するようでは結構な時間がかかります。ちなみに経路に報酬を配置して最短経路を取らせるようなこともできますが、迷路の生成をランダムでやる仕様なので複雑になるためやめました。
また、学習効果(≒報酬)は各マス目に付与されているのではなく、各マス目からの移動経路(行動)に付与されます。あるマス目(状態)における移動経路(行動)が通過するごとにスコアリングされていくわけですね。(こちらをかなり参照しました。)
ランダム性について
今回はQ値による最適ルートの選択とランダムな選択はε-グリーディ手法として、εの確率でランダムに探索するような確率配置としました。小さい確率でもいいのでランダム性を入れないと確実に詰みます。もちろん、一番最初は全てランダムに選択をして迷路を解いていくようになります。この確率εが、学習度合いによって動的に減少していければ良いんだけどなぁ。(論文は結構あるみたいですね・・・)
学習率、割引率について
学習率は更新時の影響、割引率は次の行動の影響という感じでしょう。ところで、この値について特に学習率をどうするこうするとかあるようですが、とりあえずどちらも1とかから始めても収束はすると思います。最適値に最適ループ数で収まるかは別ですが、とにかく動かして値の変化をみたい!というのならそれで十分だと思います。ちなみに今回は$α=0.99$ , $γ=0.99$で始めました。
構成について
というわけで、本題です。他の投稿者でQ学習の根幹になる理論を分かりやすく述べている方が多いので、ここではコーディングベースでお話しします。まず、大まかな構成として、全体がゴールする回数(=エピソード数)分ループして、Q値に基づいて選択する側とランダムに選択する側に分けました。どちらもQ値の更新は行います。(以下フローチャート)
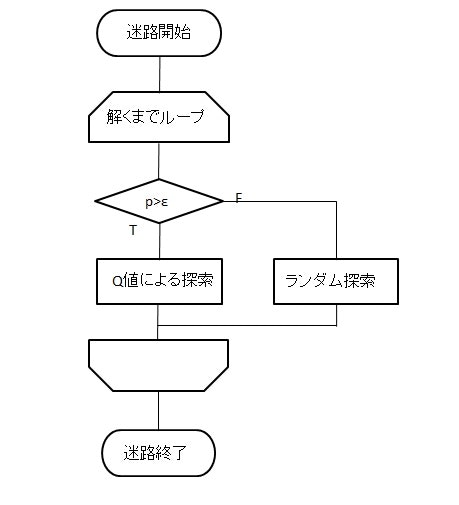
全体
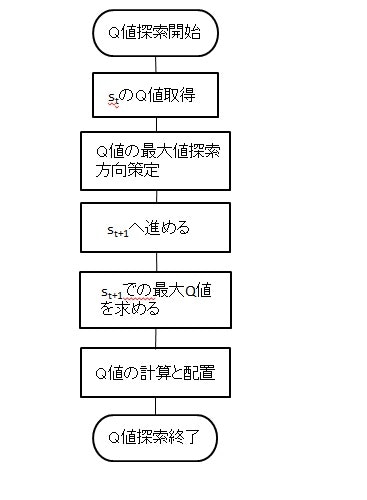
Q値による探索とQ値の更新
Q値の初期値については、初期値はランダムで配置している方もいるのですが、私は全て0としました。
また、ソースコードについてですが近日githubにより公開予定です。VBAプロジェクトの使い方について別記事で上げようか検討してます。ソース観たいという方は別途ご用命ください。
暫定的ですが、githubで公開しました。
VBAの画面と動作動画
迷路探索している動画作りました。現状のパラメータで大体50ループで収束しました。
今後の課題と応用について
今後について記します
その1 ランダム探索ってどうなの?
迷路を解く際に、一定確率でランダム探索をしていると思います。また、始めてゴールにたどり着くまでは全てランダムです。どこかでランダムな要素は必要なのですが、それが収束までの時間を延ばしている気がします。学習するにしてもある程度、法則に従って迷路探索するって実は大事なんじゃないかなぁ。
その2 最短距離で収束しない可能性について
かなり重大です。ロボットが自分で道筋を作るような目的で使うなら大事です。でも、十分な数のエピソード数こなしていれば最短距離に収束する気がするんですが未検証です。伝搬距離が短い方に大きなスコアがつくわけですので。パラメータの調整でしょうか。ちょっと今後の課題ですね。
その他
VBAは目に見える速さの処理速度との認識があったのですが、とにかく最初のころはプログラムが応答しなくなって全然進みませんでした。コード内に10msecのディレイを入れて動くようになりました。しかし...なぜかVBAのエディタを開いてフォームの実行ボタンを押さないとそもそも動かないようになりました。なぜだ・・・
あと、コーディングよりも記事の作成時間の方が掛かりました。