ファジィクラスタリング
今回は、クラスタリングの一手法であるファジィc-平均法(Fuzzy c-means)を紹介します。
クラスタリング
データ解析の分野で広く用いられる、データの集合を部分集合(クラスタ)に分割する手法です。
教師なし学習の一種でもあります。
階層的クラスタリング
- 重心法
- 群平均法
- ウォード法
などなど。
出力がデンドログラムによって表示されるのが特徴
非階層的クラスタリング
計算の高速なことなどから、ビジネスの場で用いられることが多い手法です。
k-meansが非常に有名ですが、他にもbayonで用いられているRepeated Bisectionが有名です。
[機械学習の過程をD3.jsで可視化する]
(http://qiita.com/dr_paradi/items/dfd4442bd4122fb955a6)
ファジィ理論 (Fuzzy Logic)
深くは語ると長くなるので触れませんが、1990年くらいに流行した理論で、洗濯機やクーラーなどの制御に使われています(今はどうだか知りません)。
ファジィ集合論においては、をメンバーシップ値という値を用いることで、集合への帰属度を柔軟に表現することが可能です。
たまにファジーと表記する人がいますが、間違いです。
ファジィクラスタリング
ファジィクラスタリングにもいくつか種類がありますが、今回は最も有名であるFuzzy c-meansを紹介します。ファジィの世界ではk-meansなどの非階層クラスタリングのことをハードクラスタリングと呼んだりします。
個体のクラスタへの帰属が0か1かで判断されますが、ファジィクラスタリングでは[0,1]の範囲で記述することができます。そのため、[サッカー: 0.5, 野球: 0.4, マラソン: 0.1]のようなまさに曖昧で柔軟な表現が可能です。
また、多くのクラスタリング手法では境界線線上のデータに困ることが多い(いずれかのクラスタに属さなければいけない)のですが、ファジィクラスタリングでは複数のクラスタに所属することが可能です。
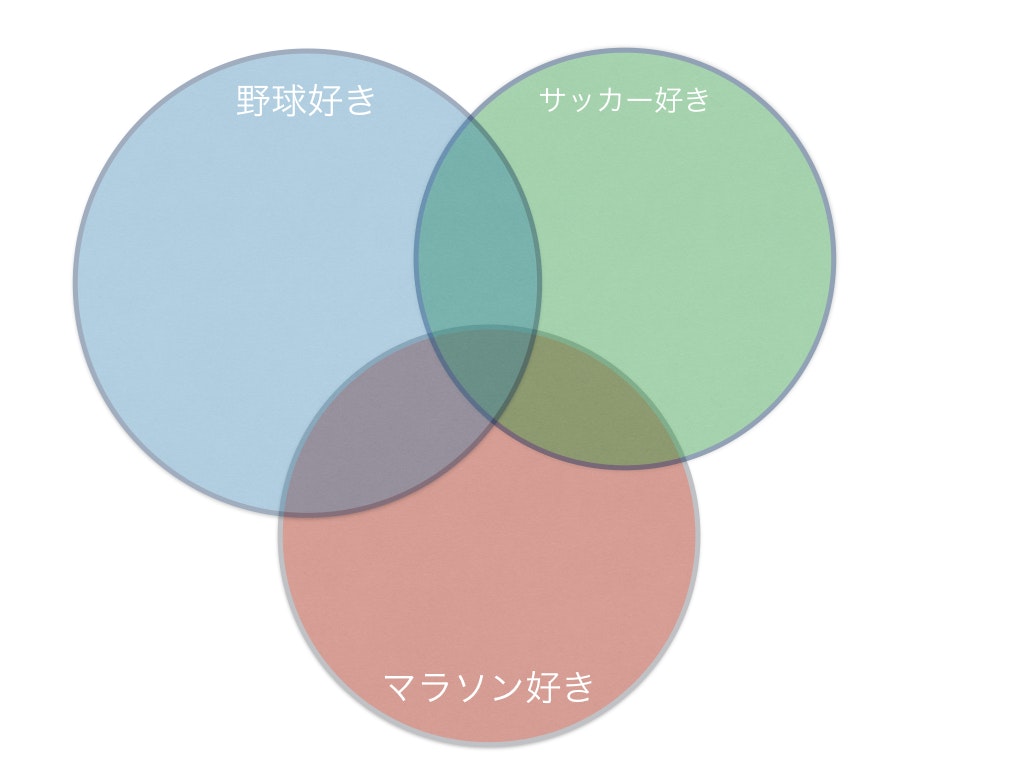
また帰属度を持つことでその他のファジィ理論に応用することも可能になります。
私が所属するチームではキノコ、タケノコ論争がよく起こるのですが、Fuzzy c-meansであれば境界線上の人も安心です。(参考: Mahout で fuzzy k-means やってみた)
Pythonでの利用
最近はJupyter環境で分析を行っていますが、Pythonで実行するライブラリが提供されています。
https://github.com/scikit-fuzzy/scikit-fuzzy
$ pip install -U scikit-fuzzy
で利用可能になります。
応用
個体のクラスタへの複数所属を許すことでより個体を柔軟に表現することができます。
参考
https://github.com/scikit-fuzzy/scikit-fuzzy
ファジィクラスタリングの有用性について 宮本 定明