<訂正のお知らせ>
本文コードにトンチキなミスがあったので、内容を大幅に修正しました。
(2017/10/27)
結論も変わってます。ごめんなさい…
イントロ
一頃、「最近のラノベは文章みたいなタイトルが付いてる」と話題になっていました。
国内最大手の小説投稿サイト、「小説家になろう」でも、その傾向は顕著です。
私は何年も「なろう」で小説読んでますが、うーん、確かに年々タイトルが長くなっていくような気がしますね。
とはいえ、「気がする」ではいけません。ささっと確かめてしまいましょう。
PythonとPandasライブラリを使えば、かなり簡単なお仕事です。
(2017/10/27追記 簡単だと思ってましたが、アホなミスをしてました。
お恥ずかしい……)
なろう小説API
こちらに公式の解説があります。
今回はざっくり、
- タイトル
- 初投稿日(世代管理に使う)
- 総合評価(小説に振られるポイント。ランキングの指標になる)
の3点を引っ張ってくることにします。
マニュアルによれば、ofパラメータにt, gf, gpを指定すればいいそうです。
データ取得
import pandas as pd
import requests
import numpy as np
import seaborn as sns
from scipy import stats
import matplotlib.pyplot as plt
%matplotlib inline
url = "http://api.syosetu.com/novelapi/api/"
# APIのパラメータをディクショナリで指定する
# この条件で、総合評価順でjson形式のデータを出力する
payload = {'of': 't-gp-gf', 'order': 'hyoka','out':'json'}
r = requests.get(url,params=payload)
x = r.json()
x
[{'allcount': 518855},
{'general_firstup': '2012-11-22 17:00:34',
'global_point': 410915,
'title': '無職転生\u3000- 異世界行ったら本気だす -'},
{'general_firstup': '2013-11-07 15:49:34',
'global_point': 330557,
'title': 'ありふれた職業で世界最強'},
{'general_firstup': '2013-07-21 07:55:05',
'global_point': 324413,
'title': '謙虚、堅実をモットーに生きております!'},
{'general_firstup': '2013-02-20 00:36:17',
'global_point': 318810,
'title': '転生したらスライムだった件'},
上手くデータを取得できたようですね。
先頭にallcount属性があり、全データ数を教えてくれます。
実際の作業では使いませんので、x[1:]みたいにして飛ばしましょう。
データの確認と整形
実は「なろう小説API」、取得上限が500です。
stパラメータをいじると、先頭位置を変更できますが、これも2000が上限です。
まあ、2000あれば十分と考えて、ちょっとループを回しましょう。
2017/10/27 追記
最初、ループの外でディクショナリを定義してたんですが、そうするとパラメータが更新されず、毎回同じデータを取得してました…
(つまり、実質500件のみの分析になっていた)
後で別な分析をしてる時に気付きました。ううう……
st = 1
lim = 500
data = []
while st < 2000:
# ディクショナリはループ内で定義する。最初ループ外で定義するというアホなミスをしてた…
# デバックのため、パラメータにncode(小説コード。一意にならないとおかしい)を追加
payload = {'of': 't-gp-gf-n', 'order': 'hyoka',
'out':'json','lim':lim,'st':st}
r = requests.get(url,params=payload)
x = r.json()
data.extend(x[1:])
st = st + lim
df = pd.DataFrame(data)
df.head()
| general_firstup | global_point | title |
|---|---|---|
| 2012-11-22 17:00:34 | 410915 | 無職転生 - 異世界行ったら本気だす - |
| 2013-11-07 15:49:34 | 330557 | ありふれた職業で世界最強 |
| 2013-07-21 07:55:05 | 324413 | 謙虚、堅実をモットーに生きております! |
| 2013-02-20 00:36:17 | 318810 | 転生したらスライムだった件 |
| 2013-06-01 20:37:58 | 307209 | 八男って、それはないでしょう! |
これで、2000行のデータを持つデータフレームの出来上がりです。
ちょっと中身を確認してみましょう。
df.info()メソッドを使ってみます
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2000 entries, 0 to 1999
Data columns (total 3 columns):
general_firstup 2000 non-null object
global_point 2000 non-null int64
title 2000 non-null object
dtypes: int64(1), object(2)
memory usage: 47.0+ KB
うーん、ぱっと見では日付データに見えるgeneral_firstup列がオブジェクトになっちゃってますね。
これは日付データに変更しないといけません。
それに、タイトルも欲しいのは文字数です。こっちも処理しましょう。
df['general_firstup'] = pd.to_datetime(df['general_firstup'])
df['year'] = df['general_firstup'].apply(lambda x:x.year)
df['title_len'] = df['title'].apply(len)
| general_firstup | global_point | title | year | title_len |
|---|---|---|---|---|
| 2012-11-22 17:00:34 | 410915 | 無職転生 - 異世界行ったら本気だす - | 2012 | 20 |
| 2013-11-07 15:49:34 | 330557 | ありふれた職業で世界最強 | 2013 | 12 |
| 2013-07-21 07:55:05 | 324413 | 謙虚、堅実をモットーに生きております! | 2013 | 19 |
| 2013-02-20 00:36:17 | 318810 | 転生したらスライムだった件 | 2013 | 13 |
| 2013-06-01 20:37:58 | 307209 | 八男って、それはないでしょう! | 2013 | 16 |
これで、タイトルの長さを示すtitle_len列と投稿開始年だけを抽出したyear列が出来ました。
さっそく、タイトルの長さをチェックしてみましょう!
データフレームを操作して、探索的に分析する
何はともあれ、describeメソッドです。
データのサマリをさくっと見れるので、本当によく使うメソッドですね。
df['title_len'].describe()
count 2000.000000
mean 17.362500
std 10.088755
min 2.000000
25% 10.000000
50% 15.000000
75% 23.000000
max 77.000000
Name: title_len, dtype: float64
面白い数字です。平均値が17字ですが、これは俳句の文字数と同一ですね。
つまり、なろうのタイトルは俳句だったのです!
古池や 蛙飛び込む 水の音…
ヒストグラム
ちょっとデータを可視化して、分布を見てみましょう。
pandasには組み込みの.plotメソッドがありますし、ヒストグラム専用の.histメソッドなんてものもあります。
df['title_len'].hist()
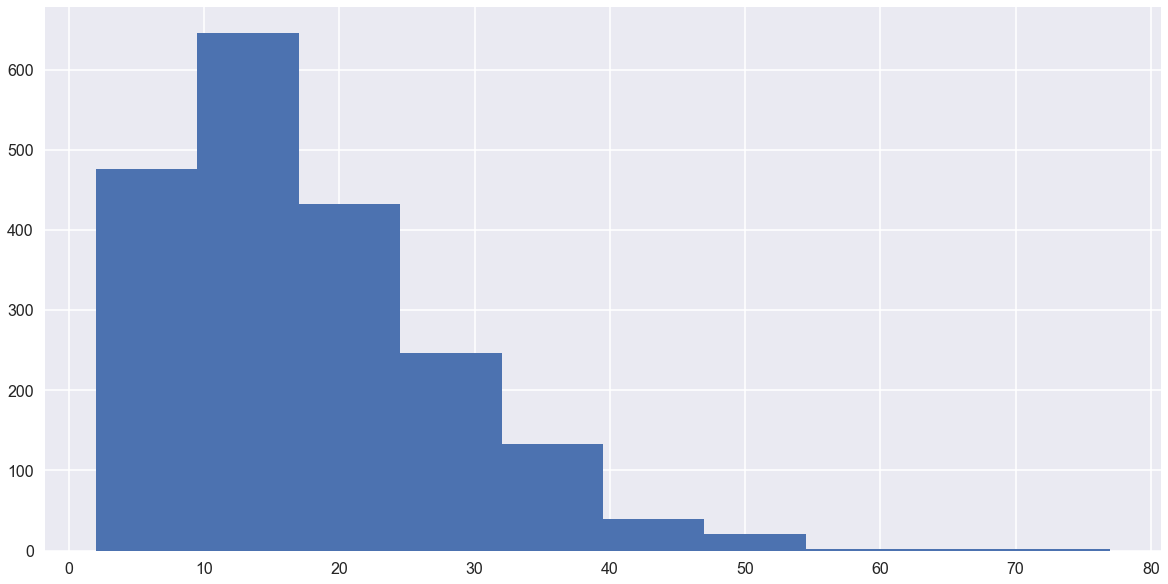
これだけ見ると、30文字くらいでも普通なんじゃね?と思ってしまいますね。
グループ集計
さて、今度は時系列で見ていきましょう。
pandasではSQLライクなgroupby集計が使えます。
title_by_year = df.groupby('year')['title_len'].agg(['mean','count','std']).reset_index()
.aggで複数の集約関数を渡せるのがミソですね。
.reset_indexメソッドをチェインしてますが、これをしないと集約条件であるyearカラムがindexになってしまうからです。
今回の分析ではyearカラムがindexのままだと面倒になるので.reset_indexで普通のカラムに戻しています。
逆に、集約条件がindexじゃないと面倒なケースもあるでしょうから、ケースバイケースです。
さて、結果を見てみますと…
| year | mean | count | std |
|---|---|---|---|
| 2008 | 7.500000 | 2 | 2.121320 |
| 2009 | 11.100000 | 10 | 6.983313 |
| 2010 | 9.750000 | 44 | 4.457160 |
| 2011 | 10.436893 | 103 | 5.071392 |
| 2012 | 12.527174 | 184 | 7.149406 |
| 2013 | 14.229008 | 262 | 8.526331 |
| 2014 | 15.785942 | 313 | 8.566979 |
| 2015 | 17.914787 | 399 | 9.554801 |
| 2016 | 20.497608 | 418 | 10.642490 |
| 2017 | 24.169811 | 265 | 11.097256 |
2010年までのデータは件数が少なすぎるので、削ったほうが良さそうですね。
しかし、うーむ……もうこれで答え出たようなもんです。
どう見たってタイトルの長さは伸びてます。
それに、標準偏差が広がっていく傾向が見られますね。タイトルの多様化でしょうか。
しかし、このまま行くと、俳句から和歌になってしまうのでは?
折れ線グラフ
title_by_year.plot(x='year',y='mean')
と、ワンライナーで折れ線グラフが描けます。
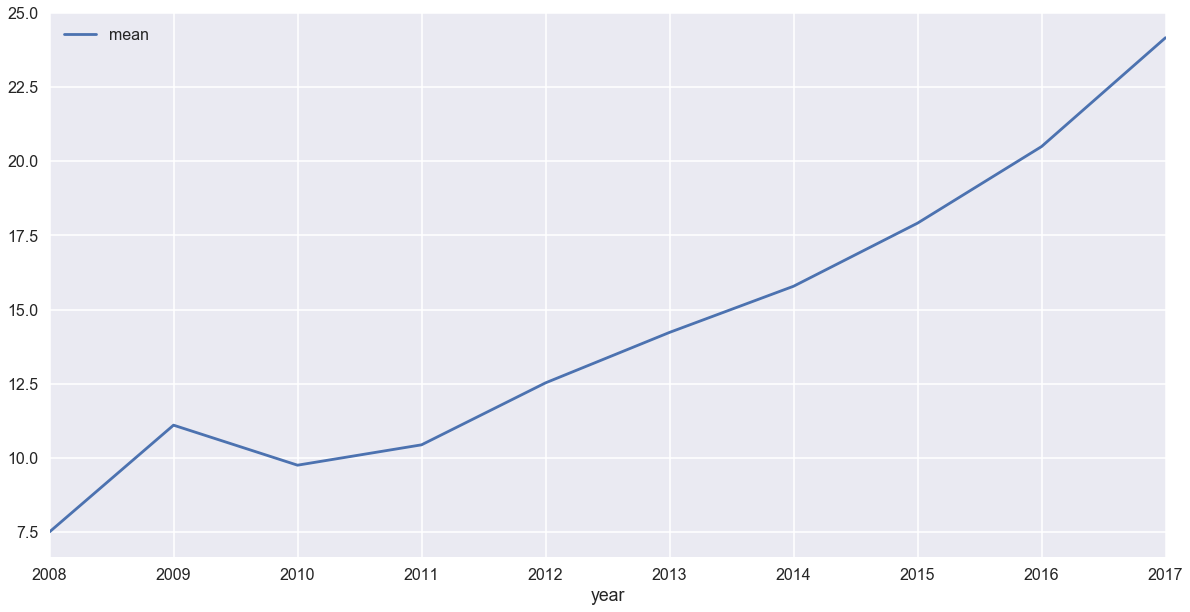
件数が少なすぎる初期は置いておいて、2011年から一貫して伸び続けてますね。
このまま行くと、どうなってしまうんでしょうか。
scipyの線形回帰メソッドで調べてみましょう。
stats.linregress([0,1,2,3,4,5,6], title_by_year[title_by_year['year'] > 2010]['mean'])
LinregressResult(slope=2.172335756048652, intercept=9.991738901311642, rvalue=0.98925248013523381, pvalue=2.2867537033141338e-05, stderr=0.1435932030138164)
結果を見ますと、傾き(slope)が2.17で、切片(intercept)がほぼ10です。
y = 2.17x + 10ですね。
えーと、この調子だと来年には25文字になります。2021年には、31文字になって和歌になります。
最初、データ取得にミスが有り、先頭500件のみで計算していたので、2019年には和歌になってしまうぞ!という結論を出しましたが、修正されました。
なろうのタイトルが和歌になるのは、東京オリンピックの後です!
2017/10/27追記
ちなみに元の回帰式はy = 3x + 13.1でした。先頭500件だけで分析すれば、この結果になりますが、サンプルが少なすぎますよね。
まとめ
ざっくり見てきましたが、「なろう」の小説タイトルが順調に伸び続けていることが確認できました。
pandasとpythonの各種ライブラリと組み合わせれば、簡単にデータ分析が行なえますね。
る、ループの使い方さえ間違えなければ……穴があったら入りたい……
追記
2017/10/26 23:50
人もすなるGitHubといふものを(略
えー、今回の内容をまとめてGistに上げました。
です。参考までにどうぞ。