要件について
定期的にAPI経由でデータを取得して、いい感じに整形して、RDSに保存したい。
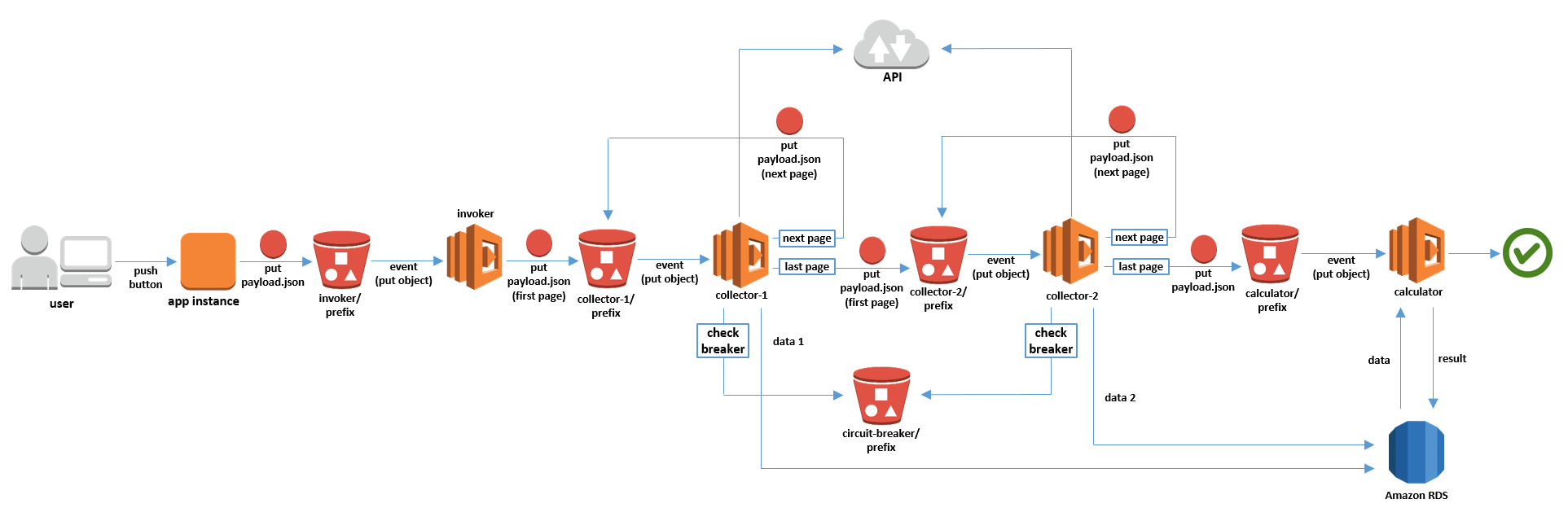
構成図
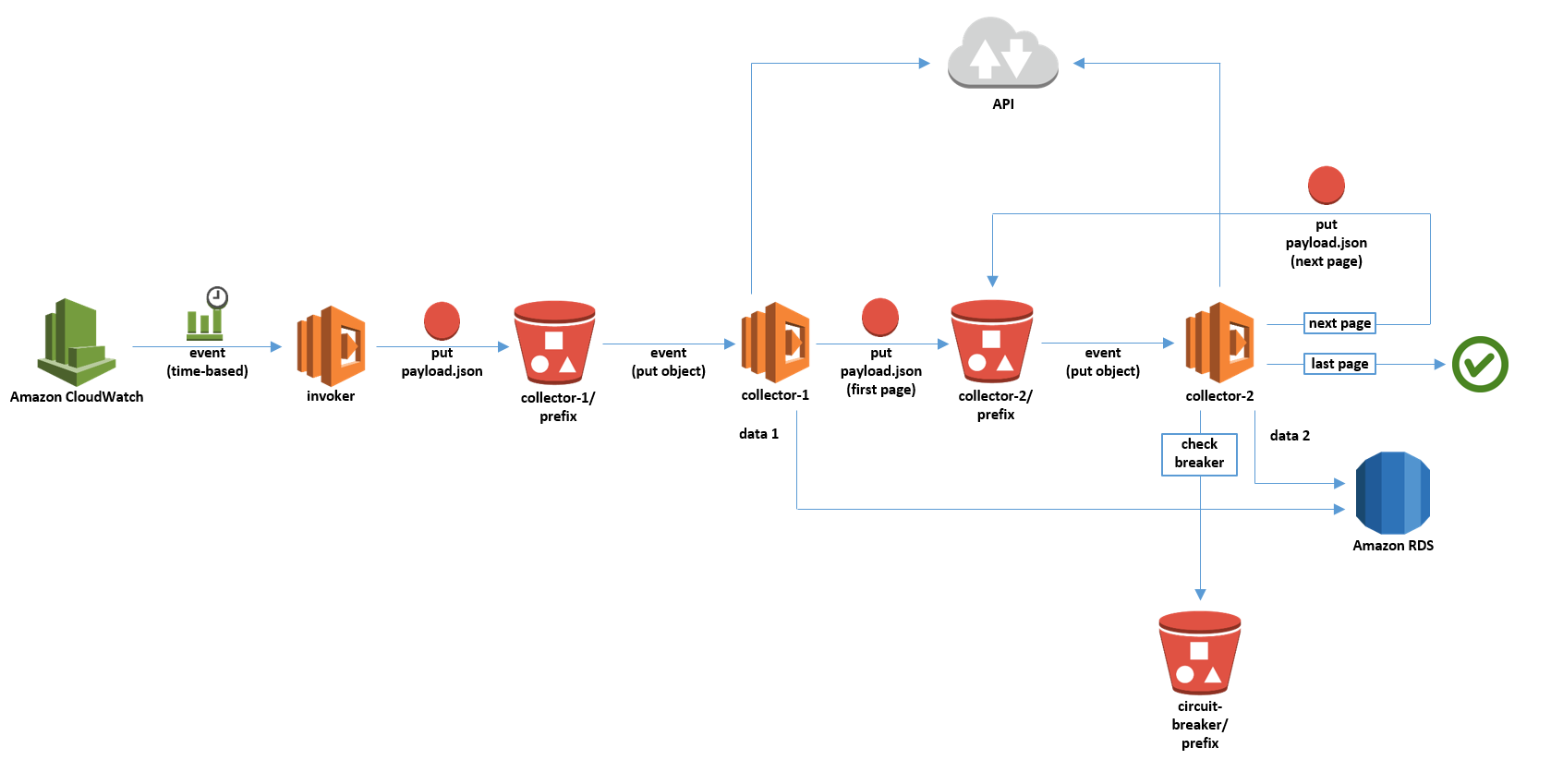
どうしてこうなった。
開発環境
Apex v0.13.0
Node.js v4.3.2
環境構築
Node.js
nvm使ってますが、anyenvとかでももちろんOKです。
nvm導入
$ git clone git://github.com/creationix/nvm.git ~/.nvm
.bash_profileに以下を書く
# nvm
if [[ -s ~/.nvm/nvm.sh ]] ; then source ~/.nvm/nvm.sh ; fi
sourceで読み込む
$ source ~/.bash_profile
node.jsインストール
Lambdaではv0.10.36かv4.3.2しか使えないので。
参考) https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/current-supported-versions.html
$ nvm install v4.3.2
$ node -v
v4.3.2
Apex導入
Apexインストール
$ curl https://raw.githubusercontent.com/apex/apex/master/install.sh | sh
認証情報のファイルを用意する
$ cat ~/.aws/config
[default]
output = json
region = ap-northeast-1
$ cat ~/.aws/credentials
[default]
aws_access_key_id = [AWS_ACCESS_KEY]
aws_secret_access_key = [AWS_SECRET_KEY]
ファイル構成
├── common
│ ├── index.js
│ ├── lib
│ └── package.json
├── functions
│ ├── function1
│ │ ├── driver.js
│ │ ├── index.js
│ │ └── package.json
│ ├── function2
│ │ ├── driver.js
│ │ ├── index.js
│ │ └── package.json
│ ├── function2
(略)
├── project.development.json
├── project.json
├── project.local.json
└── project.staging.json
構成案については、
Apexで環境変数を切り替える話
に書いたenv毎に分離する&共通系を
サーバレスなアーキテクチャでのLambda Functionの分割単位について考える#共通処理
のようにまとめる感じでやってます。
あと、ローカル実行用に
AWS Lambdaファンクションを開発するときはNode.jsのバージョンにご注意を#ローカルでLambdaファンクションを実行したい。
を参考にしてdriver.js作ってやってますが、この辺はgulpなり使ってもう少し使いやすくしたいなと思っています。
ようやく本題: 構成についての話
当初は
定期実行で
- API叩いてデータ取ってくる
- 取ってきたデータをマージしてRDSに突っ込む
というLambdaを1個作ればよかろう、と。
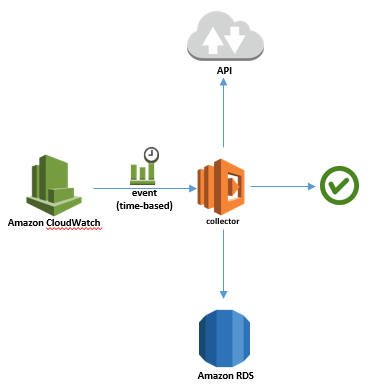
こんな感じで考えてたんですが。
想定より必要なリクエスト数が多く、普通に投げてたら実行時間が5分(Lambdaの上限)を余裕で超えてしまう悲しい事態に。
仕方ないので
- S3にjsonファイルをputして、それをトリガーにしてlambda起動
- 一定数のリクエストを処理したら、次のページの分をS3にput
- それをトリガーに同じlambdaが別途起動
- 以下2.と3.の繰り返し
といった方向に切り替えました。
いろいろ端折ってますが、こんな感じで実装。
exports.handler = (event, context, callback) => {
co(function *() {
let target = get_payload(event.Records[0].s3.object.key);
~~~(中略)~~~
if (target.page < total_page) {
target.page = target.page + 1;
result = yield put_payload(prefix, target);
}
});
});
function get_payload = (key) => {
let params = {
'Bucket': config.s3.bucket_name,
'Key': key
};
return new Promise((resolve) => {
s3.getObject(params, (err, data) => {
if (err) {
console.error(err);
reject(err);
} else {
resolve(JSON.parse(data.Body.toString());
}
});
});
};
function put_payload = (prefix, target) => {
let body = JSON.stringify(target);
let filename = 'payload.' + target.key + '.' + target.page + '.json';
let params = {
'Bucket': config.s3.bucket_name,
'Key': prefix + filename,
'Body': body.toString('base64'),
};
return new Promise((resolve, reject) => {
s3.putObject(params, (err) => {
if(err) {
console.log(err);
reject(false);
} else {
resolve(true);
}
});
});
};
あとはトリガーを設定。
※ management consoleのスクリーンショット貼ってますが、terraformで設定するほうがよいかと。

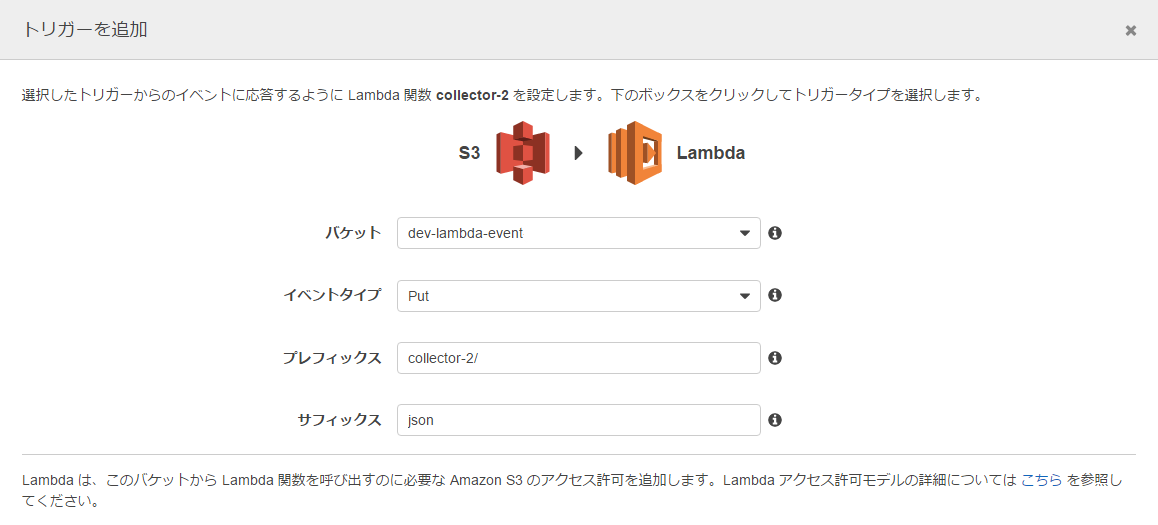

てなことをやって
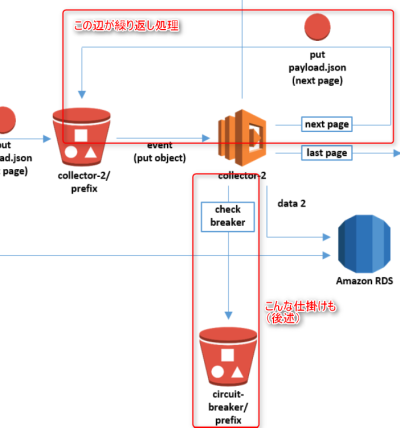
こんな構成が出来上がった、というわけです。
おそらくS3ではなくDynamoDB使うほうが適切なんですが、それにしてもやることはあまり変わらないと思います。
あるいはStep Functions使うとかなんでしょうけど、同じタスクの繰り返しってできましたっけ。。。?
ブレーカー(後述の部分)の仕掛けについて
これ、何か間違ったら延々ループが続くことになる恐ろしい仕組みでして。
その回避策として
- 処理開始の最初にブレーカー用のファイルがS3に置いてあるかをチェック
- 対象のファイルがあったら、その時点で処理終了
とすることで、暴走しても止められるようにしています。
チェックするところの実装はこんな感じで。
exports.handler = (event, context, callback) => {
co(function *() {
let breaker_key = 'collector-2';
let breaker = yield get_breaker(breaker_key);
if (breaker && breaker.status) {
console.log('Close breaker, stopped.');
callback(null, true);
}
console.log('check breaker finished, OK.');
(以下処理が続く)
失敗と判断して再走しないように、成功時のcallback返してます。
S3から取ってくるところは
function get_breaker = (target) => {
let prefix = config.breaker_prefix;
let filename = 'payload.' + target + '.json';
let params = {
'Bucket': config.s3.bucket_name,
'Key': prefix + filename,
};
return new Promise((resolve) => {
s3.getObject(params, (err, data) => {
if (err) {
resolve({'target': target, 'status': false});
} else {
let objectBody = data.Body.toString();
resolve(JSON.parse(objectBody));
}
});
});
};
ファイルがなければ「ブレーカーは発動していない」とみなすようにしています。
ブレーカー用のファイル置く処理もLambdaで作っているので、
$ echo -n '{"target": "collector-1", "status": "break"}' | apex invoke -e development circuit-breaker
とか手元で実行すれば、ブレーカー発動。
解除する時も似たような感じ。
なおこの辺もgulpなりで以下略。
ちなみに
応用で更にキワいのも作っていたり。
数珠連パターンと勝手に命名しています。
まとめ
PHP書くって当初聞いていたんですが、なぜかNode.jsを書いていて、今はPythonで書き直せと言われています。