はじめに
筆者は音声信号処理・音声認識周辺の知識は皆無です。
その道のプロフェッショナルな方には本記事はおすすめいたしません(;´・ω・)
ちなみに初級、中級、上級と進んでいくつもりです。
動機
お仕事で「楽曲レコメンドしよーぜ!」的な話が出てきたので。
楽曲レコメンドは音声認識に分類される?
答えは否です。音声認識とは、人間が喋った声を機械が文字に直すことなので、楽曲レコメンドは音声認識とは呼ばないんですね。(こちらのサイトがとても分かりやすかった。)
楽曲レコメンドはMIRと呼ばれる研究分野のようで、音声信号処理が核になるようです。
MIRとは
MusicInformatioRetrieval(音楽情報検索)の略。
普段から使っている、アーティスト名や曲名での楽曲検索はテキストデータをInputとするが、MIRでは音声波形そのものを入力とする。
以下MIRの具体例
- 聴く人に合った音楽をレコメンド
- 楽器の分離や楽器認識
- 自動採譜(耳コピが不要になる?)
- 自動分類(ジャンルのラベリングなど)
- 音楽生成 etc...
音声信号処理に便利なツール、ライブラリ
- SPTK
- リサンプリング、フーリエ変換など音声分析のためのコマンドが提供されている。音声信号処理、音声認識界隈ではかなり有名らしい。
- librosa
- 音楽分析のためのPythonパッケージ。2015年リリース。
- SOX
- 音声ファイルの形式変換ソフト
- lame
- 音声ファイルの形式変換ソフト
上3つを触ってみましたが、音声信号処理初心者の私にとってはSPTKよりlibrosaの方が良かったです。(SPTKは環境構築がめんどくさかった・・・)
あと、Pythonで機械学習の勉強しながら音声信号処理も勉強したい、みたいな人にはお勧めです。(SPTKもPythonから書くことはもちろん可能ですが)
ということで前置きが長くなりましたが今回紹介するのはlibrosaです。
(ちなみに、SPTKを使った類似楽曲システム構築の記事が秀逸すぎました。。http://aidiary.hatenablog.com/entry/20121014/1350211413 )
librosaのインストール
環境構築の途中で"jupyter notebook"が通らなくなって結構焦ったので手順をまとめておきます。
※筆者はWindowsユーザーです。あと、Anaconda環境でやりたいので生Pythonの人は2.からでいいと思います。
※pip installは通用しませんでした(おそらくC++のコンパイラがないせい)
手順
1.Anacondaの再インストール(MacやLinuxならおそらく不要。WindowsでもAnacondaとPythonのバージョンが最新版であれば不要だと思う)
2.resampyのDL
3.librosaのDL
4.Microsoft Visual C++ Compiler for Python 2.7のインストール
5.Visual C++ 2008 64-bit Command Promptを開き、reampy,librosaの各ディレクトリで以下のコマンドを実行
python setup.py build
python setup.py install
Pythonで
library(librosa)
が通ればok
旧環境:Python2.7.11:Anaconda2-4.0.7
新環境:Python2.7.12:Anaconda2-4.2.0
librosaに触れてみる前に
音声信号処理を始めるにあたり調べたことをまとめておきます
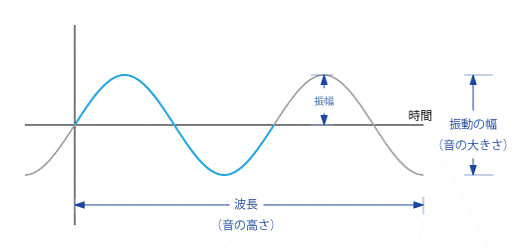
- 音の三要素
- 音の大きさ : 波の振幅に相当。大きい音ほど振幅が大きい。
- 音の高さ : 波の周波数、周期に相当。高い音ほど周波数が高く、周期が短い。
- 音色 : 波の形に相当。
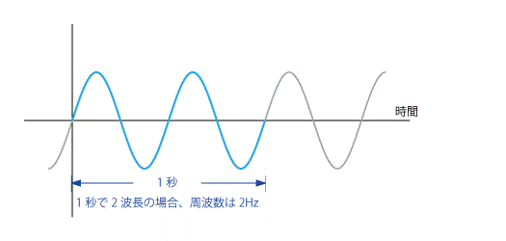
- サンプリング周波数(単位Hz)
- 単位時間あたりにサンプルをとる頻度
- 音楽CDで使用されるサンプリング周波数は44.1kHz
- フレーム数(≒データ量)
- チャンネル数:異なるデータを同時に出力する場合の音情報の数。モノラルなら1、ステレオなら2。
- 量子化bit数
- アナログデータを1回あたり何bitでデジタルデータ化するか
- 数字が大きくなればデータ量が増える
- オーディオでは16bit以上、電話音声なら8bit、ビデオ信号では8~10bitがよく使われるらしい
やっと本題
librosaは音楽分析のためのPythonパッケージです。
MIRのためのモジュールが提供されています。
librosaチュートリアルを参照しながらやったこと
- 波形を可視化
- 注:librosaでもやってみましたが、最終的にPython標準ライブラリwaveをつかっています。。
- ビートトラッカー
- 音声の再生
- 打楽器・高音域/和音に元音声を分割
※あとでipynbあげる
今後
- 「出来るだけ偏りのない学習データ(楽曲)」を収集する。
- 音声分析まわりをもう少し勉強する(フーリエ変換や窓変換、プリエンファシスフィルタなど)
- 中級編の予定:楽曲特徴量についての知識や抽出方法を習得
- コード進行、HVL、BPM、MBL、MSL、ASL、mfcc、局所特徴量(所謂サビ)など・・・
- 上級編の予定:類似楽曲を探す上での特徴量に最適なものを探す
- 特徴量を組み合わせたりして学習させてみる
- 類似楽曲システムの構築・評価。(評価方法も考えないといけない。。)
感想
- 機械学習という武器を使うつもりで音声信号処理の世界に首を突っ込んでみたが、知識が足りないのでもっと勉強します
- 個人的には、機械学習のInputデータを音声にするとなると勉強のモチベーションがかなり上がることが判明。実は今回1番大きな発見だった。
参考URLまとめ
- http://recognition.web.fc2.com/
- http://hhsprings.pinoko.jp/site-hhs/2015/02/microsoft-visual-c-compiler-for-python-2-7%E3%81%AF%E3%81%B2%E3%81%A8%E3%81%AE%E3%81%9F%E3%82%81%E3%81%AA%E3%82%89%E3%81%9A/
- http://np2lkoo.hatenablog.com/entry/2016/09/22/052354
ありがとうございました。次回にご期待ください!