少し前に、機械学習やデータ分析手法を使って脳波を分類してみたいと考えた。
kaggleのコンペティションに手の動きを検知する「Grasp-and-Lift EEG Detection」
(https://www.kaggle.com/c/grasp-and-lift-eeg-detection)
があったので、勉強のために翻訳を試みた。
当コンペは2015/8に締め切りを迎えており、2017/2/25現在のトップチーム「Cat & Dog」のAlexandre Barachant氏のGithubリポジトリに記載されている、「Signal Processing & Classification Pipeline」から「Code」までの区間、モデルの概要説明を翻訳したいと思った。
当方の脳および信号処理についての知識が乏しく、また、注として「(*〜*)」を挿入して読みづらくしてしまった箇所が多く、申し訳ないです。
間違い等、ご指摘下さい。
原文:
alexandrebarachant/Grasp-and-lift-EEG-challenge
https://github.com/alexandrebarachant/Grasp-and-lift-EEG-challenge
信号処理と分類のパイプライン
概要:
このチャレンジは、つかむ、物体を持ち上げる、等の最中の手の動きに関する6つの異なる事象(*=イベント*)を検出することがゴール。脳波(*=EEG(非侵襲)*)のみを使って。すべての時間サンプルにおける6イベントの確率を出力する必要がある。評価手法は6事象にまたがるAUC(AreaUnderROCcurve)。
脳波の観点では、手の動きの最中の脳のパターンは脳波信号の空間周波数の変化として特徴づけられる。
もっと具体的には、対側運動皮質MU12Hz周波数帯の信号強度の減少が見られるはずだ。同側運動皮質の信号強度が増えるとともに。
これらの変化は動きの実行後に起こる、また、あるイベントは動きの最初にラベルづけされ(例.動かし始める)、
他のいくつかは終了時点でラベルがつく(物体を置き換えるなど)ということを考慮すると、シングルモデルで6事象すべてをスコアづけすることは難しい。
言い換えれば分類するものに応じて予測なのか検知なのかが変わる。
6事象は一連の手の動きの異なる段階を表す(動き始める、持ち上げ始めるなど)。ひとつの挑戦は系列の一時的な構造を考慮に入れることだった。つまり、事象間の連続的な関係を。加えて、いくつかのイベントはオーバーラップしているし、あるものは相互排他的に起こったりする。結果として、マルチクラス手法とか、系列をデコードするのに有限状態機械(*オートマトン?*)を使うことは難しい。
最終的に、TrueラベルはEMG(*=筋電図*)シグナルから抽出されて、+-150msフレーム(事象の発生を中心として)が与えられる。この300msには心理学的(?)意味はない。(150と151に対して異なるラベルのついた150+151フレーム(*301フレーム*)の単なるサンプルと変わりない)したがって、別の困難は予測をシャープにすることだった、FalsePositive(=偽陽性)を最小にするために(フレームの端々において)。
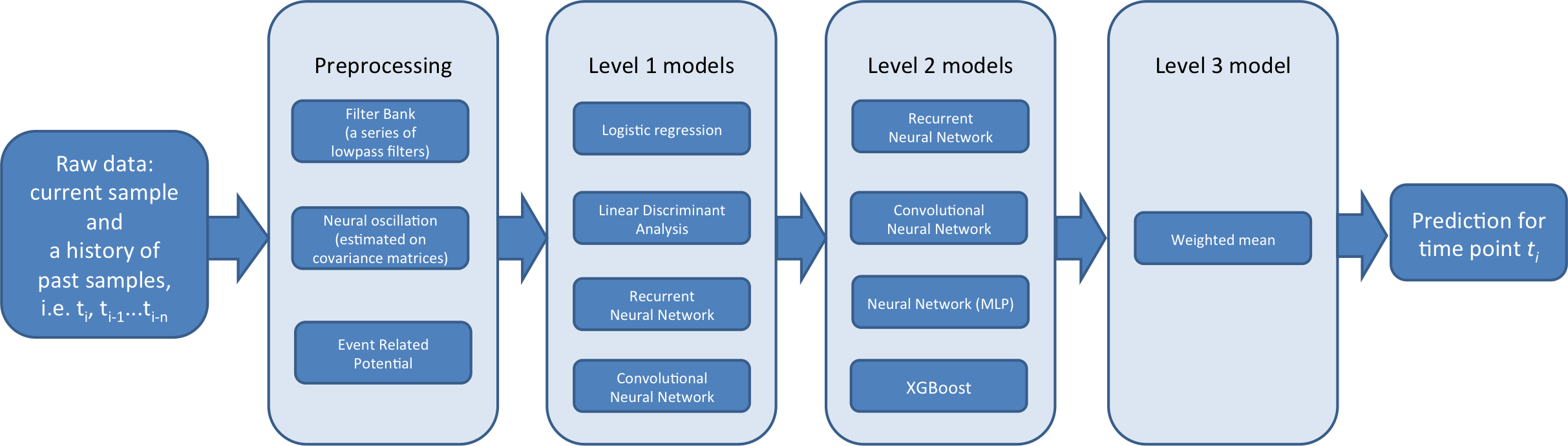
というような文脈において、3つのレベルの分類器パイプラインを作る:
Lvl1は被験者特有。つまり各被験者ごとに個別に訓練する。それらの多くはイベント特有でもある(*つまり、多くの被験者は同じ1動作しかしていないデータなのだと思われる*)。Lvl1のメインゴールはサポートと多様性をLvl2モジュールに対して提供すること。被験者とイベントを異なるタイプの特徴を使って埋め込むことで。
(*レベル1は特徴から新たな特徴を出力して後段のレベル2分類器に送る*)Lvl2はグローバルモデル(患者特有ではない)。レベル1予測(メタ特徴)の結果で訓練される。それらのメインゴールは事象間の一時的な構造を考慮すること。また、それらはグローバルに、大いに被験者の間の予測の補正を助けるという事実(*がある*)
Lvl3はLvl2の予測のアンサンブル。2の重みをAUCを最大にするように最適化するアルゴリズムを経由している。このステップは予測のシャープさを改善する、過学習を避けながら。
未来データなしルール
因果関係に細心の注意を払った。すべての時間で一時的なフィルタが適用されるが、lFilter関数(Scipy)を使った。それは「direct form II causal filtering」を実装した関数だ。各時刻でスライドウィンドウが使われるが、我々は信号を左側でゼロ埋めした(we padded the signal with zeros on the left)。
同じアイデアは過去の予測の履歴が使われた時に適用される。( Same idea was applied when a history of past prediction was used)
最後に、シグナル又は予測を処理前の時系列をまたがって結合(concatenate)したので、前の系列の最後のサンプルは「漏れる」ことがありうる。
これはルール違反ではない。なぜならルールは特定の時系列のなかでのみ適用されるから。
モデル説明
ここでは3レベルのパイプラインの概要を述べる
Lvl1
モデルは以下のように説明される。バリデーションモード、テストモード(?)において、生データで訓練した。
前のモデルは系列1−6で訓練、予測は7−8(これらの予測はレベル2のトレーニングデータ(メタ特徴)となる。
後のモードは系列1−8上で訓練、そしてテスト系列9−10で予測。
(*9-10が提出すべき予測対象で、それに向けて1-6で学習し、7-8の予測を出力する。その後その予測を入力としてLvl2で9-10の予測を出力するという意味?*)
Cov
共分散行列は脳波から手の動きを検出するための選択の特徴量。
それらは空間的な情報(チャネルごとの共分散を通して)を含んでおり、頻度の情報を含んでいる(シグナルの分散を通して)。
共分散行列はスライドウィンドウ(普通500サンプル)で予測される。シグナルへバンドパスフィルタを使った後に。
共分散には2種類ある:
1.AlexCov:
事象のラベルは最初に再度ラベル付けされる。7つの状態の系列へと。
それぞれの脳の状態について、それぞれの共分散行列に対応する幾何平均(*後述*)が推定される。(LOGユークリッド計量が計算されることによって)
その後それぞれの重心へのリーマン距離が計算される、サイズ7の特徴ベクトルを作りながら。
この手順はリーマン計量を使った教師あり多様体組み込み(supervised manifold embedding with a Riemannian metric)とみなせる。(?)2.RafalCov:
上と同じアイデアだが、それぞれの事象ごとに別々に適用される。12要素の特徴ベクトルを作りながら
(それぞれのイベントについて、1と0の2クラスがある)
ERP
(*事象関連電位 (じしょうかんれんでんい、英: event-related potential, ERP)*)
このデータセットは視覚的な引き起こされた電位(potential)(実験パラダイムと関連する)を含む。非同期ERP検出のための特徴は基本的に前のBCIチャレンジでやったものに基づく(*著者は以前にERP検出チャレンジに取り組んでいる*)。トレーニング中に、シグナルは確立される(epoched)それぞれのイベント開始の1秒前に。ERPはXdawnアルゴリズムを使って平均されて削減された(確立された信号と結合される前に)。それから、共分散行列は推測されて、処理された。共分散特徴と同じように。
FBL
シグナルは多くの予測できる(predictive)情報を含んでいることがわかった。低周波において。なので、フィルタバンクの手法を導入する。それはいくつかの5次のバターワースのローパスフィルタ( 5th order Butterworth lowpass filters)を適用した結果を結合することからなる。(カットオフ周波数は0.5,1,2,3,4,5,、7,9、15,30Hz)
FBL_DELAY
FBLは、しかし、単一の生データ/観測は、また、5つの過去のサンプルで一緒に2秒(1000のサンプルが過去にあって、それぞれ200番めのサンプルだけを取ることで?)のインターバルへとつなげる(span)ことで拡張される。
これらの追加の特徴はモデルにイベントの一時的な構造を捉えさせることができる。
FBCL
フィルタバンクは共分散行列の特徴はいっしょにひとつの特徴セットへと結合される。
アルゴリズム
LogisticRegression, LDA(線形判別分析) 異なる標準化がテストと事前に学習に適用される)
上記の特徴の元で、事象特有の観点?がデータ上に提供される?
また、2つのLVL1NN手法が存在するが、それらはどちらもイベント特有ではない。(すべての事象が同時に学習される)
(*下記*)
Convolutional Neural Network
これはモデルのファミリー(family)である(TimHochvergのスクリプトとBluefool’stweaks に基づいてちょっと拡張した。Tim Hochberg's script with Bluefool's tweaks:ローパスフィルタとオプション2dCONV(すべての電極にまたがって行う、なのでそれぞれのフィルタはすべての電極の間の依存関係を同時に捉える。)
要約すると、これは小さな1D/2D畳み込みNNだ(入力→ドロップアウト→1d/2dConv→dense→dropout→dense→dropout→出力)
現在のサンプルと過去のサンプルの一部で学習されるような。それぞれのCNNはそれぞれの1実行ずつの間の、比較的高いバリアンス(*ばらつき*)を減少させるために100回baggedされる(*Bagging?、後述*)、
その1実行というのは、訓練データのランダムな部分(portion)でネットワークを訓練させた、効率の良い確立(epoch)戦略を利用するために生じさせる?ようなもの。
Recurrent Neural Network
ローパスフィルタを通した後の信号で訓練される小さいRNN(input -> dropout -> GRU -> dense -> dropout -> output))
(ローパスフィルタのフィルタバンクと、1,5,10,30hzのカットオフ周波数)
8秒の短い、スパースな時系列変化で訓練される(それぞれの100thサンプルを過去4000サンプルまで取る)。RNNはこのタスクにパーフェクトに適用できると思われそうだが(明確に定義されたイベントの一時的構造とその中間依存関係(*interdependencies、共起性?*))、実際には良い予測を得るのが大変だった。それで、計算コスト高かったので思ったほど突っ込んで追求しなかった。
Level2
これらのモデルはレベル1モデルの出力でトレーニングする。
それらはValidationとTestモードで訓練する。Validationは行われるクロスバリデーションのやり方で、系列ごとに分割して(2フォールド(*グループ*))。各foldからの予測はそれからメタフィーチャー(モデルを使って変換された新たな特徴のことをこう呼ぶ)される、Lvl3モデルのために。
このテストモードモデルは系列7,8で訓練されて、予測はテスト系列9,10のために出力する。
アルゴリズム
XGBoost
勾配ブーストマシン(Gradient boosting machine)はデータに対して特有の視点をもたらし、とても良いスコアを達成し、かつ次の段のモデルに対して多様性をもたらす。各イベントごとに個別に訓練しているのはLvl2だけであって、被験者IDが特徴として追加されている。それは被験者間の予測を補正するのに役立つ(被験者IDのワンホットエンコーディングを追加してもNNベースのモデルでは性能が改善しない)。
XGBoostが正しく特定のイベントを予測する、この精度は対応する事象だけでなく、すべてのイベントのメタ特徴で、何秒かの時系列の信号で訓練した場合に非常に良い。なぜならそれらはイベントとか関係する一時的構造の間の中間依存性に含まれる予測に使用できる(Predictive)情報を抽出するからだ。
さらに、入力のサブサンプルを頑張ると、標準化できて、さらに過学習も防げる。
Recurrent Neural Network
クリアに定義されたイベントの一時構造とレベル2のメタフィーチャーの多様性で、とても高いAUCを達成することができる。Adamで訓練すると計算コストが低い(多くのケースで収束するのに1エポックしか必要としない)。大量のレベル2モデルはシンプルなRNNアーキテクチャに小さい修正を加えたもので(input -> dropout -> GRU -> dense -> dropout -> output)それはサブサンプルされた8秒の短いタイムコース(*timecourse、時系列変化、入力データ長さのこと?*)で訓練される。
Neural Network
小さいマルチレイヤの(1つしか隠れ層がない)サブサンプルされた3秒の履歴時系列で訓練される。これはRNNsやXGBoostよりダメだった。でもLvl3モデルへの多様性は提供してくれた。
Convolutional Neural Network
小さいLvl2のCNNs(畳み込みレイヤが1つ、プーリングなし、その後に1つのdenseレイヤ)は3秒のサブサンプル済み履歴時系列(history timecourse)で訓練される。
1つの時間サンプルに対するすべての予測とストライドにまたがるフィルタがタイムサンプルの間で作られる。マルチレイヤNNの場合、このCNNsのメイン目的はLvl3モデルへの多様性を提供すること。
Lvl2モデルの多様性は拡張される、下記の修正をして、上記のアルゴリズムを実行することによって:
- メタ特徴を違ったサブセットにする
- タイムコース履歴の長さを変える
- logのサンプル履歴(*時系列のサンプルをlogにする?*)(最近の時間の点は偶数?(even)インターバルのサンプリングよりももっと密にサンプルされる)
- baggingする(下記参照)
また、NNs,CNNs,RNNsに対しては:
- denseレイヤの活性化関数にReluの代わりにパラメトリックReLuをつかう
- マルチレイヤにする
- オプティマイザーを変える(SGDかADAM)
朱鷺の杜Wikiより引用
http://ibisforest.org/index.php?%E3%83%90%E3%82%AE%E3%83%B3%E3%82%B0
バギング (bagging) †
ブートストラップサンプリングを繰り返して生成した判別器を合成して,より判別精度の高い判別器を生成する方法.
名称は Bootstrap AGGregatING に由来
ニューラルネットの分野では コミッティマシン (committee machine) ともいう.
ブートストラップサンプリング †
サンプル集合 X={xi}N から,重複を許してサンプリングして新たなサンプル集合 X' を作る方法
Bagging
いくつかのモデルが追加でBaggedされる。その堅牢性を高めるために。2種類のバギングが使われる:
- ランダムサブセットをトレーニング対象から選ぶ。各Bagのために(モデルはその名前の中にBagを複数含む)(*著者のリポジトリに記載のファイル名*)
- ランダムサブセットを選ぶメタ特徴から、各バッグのために(bags_modelと名前が付いているもの)(*著者のリポジトリに記載のファイル名*)
すべてのケースで15Bagをfoundした(*実行?*)、満足いく結果を得るために。
それ以上増やしてもAUCは大して増えない。
Level3
Lvl2予測はアンサンブルされる。AUCを最大化するためのアンサンブル重みを最適化するアルゴリズムを通して。このステップは予測のシャープさ(精度?)を上げる、そして、とてもシンプルなアンサンブル手法を使うことは過学習を防ぐ。(それは(*=過学習は*)実際に高度な(*Lvlが高い、=段数が多い?*)アンサンブルにとっては脅威だった。)さらなるAUCの増加のために、また、頑健性を上げるために3つの加重平均を使った:
- 算術平均(*普通の平均*)
- 幾何平均(*それぞれを掛けて、冪根を取る*)
- 指数平均: f $\bar x_p = S(\sum x_i^{w_i})$, where $w_i=[0..3]$ and $S$ is a logistic function that is used to force output into [0..1]
Lvl3モデルは上記3つの加重平均の平均である。
提出
| Submission name | CV AUC | SD | Public LB | Private LB |
|---|---|---|---|---|
| "Safe1" | 0.97831 | 0.000014 | 0.98108 | 0.98095 |
| "Safe2" | 0.97846 | 0.000011 | 0.98117 | 0.98111 |
| "YOLO" | 0.97881 | 0.000143 | 0.98128 | 0.98109 |
Safe1
クロスバリデーションで比較的AUC高く、安定しているものを最終提出物(lvl3)モデルとした。
lvl2の堅牢なメタフィーチャー(lvl2のモデルの7/8がBagされている)?
(7 out of 8 level2 models were bagged.)
Safe2
非常に安定したCV(*クロスバリデーション?*) AUCである別の提出物。このLvl2のメタフィーチャー(6/16だけバッグしている)?(only 6 level2 models out of 16 were bagged)はsafe1よりももっと安全ではないLvl2の選択であると(まちがって(?))考察され、実際に最終提出では選択しなかった。ここにおいたのはただの興味。
YOLO
(*YOLO,「人生は一度きり」の意?*)
2番めの最終提出物は18個のLvl3モデルの平均。
それらを一緒に平均することは堅牢性の増加をもたらす。クロスバリデーションにおいてCVと公開LBスコアの。この提出はちょっと過学習していて、Safe1,2どちらかを実行することでその高い計算コストを避けることが可能だ。どちらも似たようなAUCをプライベートリーダーボードでは出力している。
議論
実際に脳の活動をデコードしてるのか?
広い範囲の特徴を元にしているので、これらのモデルが実際に手の動きに関連した脳の活動をデコードしてるのかどうかは解答がない。複雑な前処理を使うことで(共分散特徴のために)または、ブラックボックスアルゴリズム(CNN)は追加の困難をもたらす。結果を解析するときに。
(*NNの結果を、なぜそうなったか説明できない、という問題の話かと。*)
低頻度の特徴に基づくモデルの良い性能は更に疑いをもたらす。これらの特徴は特に手の動きをデコードするのに有用であると知られていない。
さらに具体的には、周波数1Hz以下の300msのイベントの検出で良い結果を出すのは非常に難しい。胴体の動きによるベースライン(*基本の波形データ?*)の変化、または被験者が物体に触ったことで接地した場合には説明が変わる。
(*そういう場合には検出できる、という意味だと理解しています*)
また、比較的良い性能を観測できる、70-150hz周波数帯で予測する共分散モデルでは。この周波数帯はとてもEEG(*=脳波*)をよく含んでいて、タスクに関連するEMGの活動が潜在している
*筋電図(きんでんず)(electromyography - EMG)*
でも、データセットはとてもクリーンで、事象に関連する強いパターンを含んでいる、それはこのスクリプトで見れる。別の活動(VEP*,EMG*など)は全体の性能に寄与しているかもしれない、より難しいケースで予測を強制することによって(re-enforcing predictions for harder case)、でも、実際に私達が手の動きに関する脳の活動をデコードしていることは間違いない。
*視覚誘発電位(しかくゆうはつでんい、英:Visual evoked potentials, VEP)とは、視覚刺激を与えることで大脳皮質視覚野に生じる電位である(Wikipediaより)*
これらのモデルは全部必要なのか?
この挑戦で私はアンサンブルを非常に利用した。この方法の問題は(すべてのサンプルの予測)この種の解法にのめり込んだ。(?)(The way the problem was defined (prediction of every sample) was playing in favor of this kind of solution)、このような状況ではモデルを増やすことはいつでも性能を改善し、予測精度を上げる。
実際の応用では、すべてのタイムサンプルを分類する必要はない、そしてひとつのタイムフレーム手法を使う、たとえば250msおきに出力するとか。もっと最適な解法を使えば、等しいデコード性能を得ることが可能であると信じている、アンサンブルをLvl2で止めて、いくつかのレベル1のモデルのサブセットだけを使うことで。(それぞれの種類の特徴に対して1つ)。