物体検出ニューラルネットワークのSSDを調べていた。
勉強のために論文を訳することにした。
下記のページを参考にさせていただいた。
https://www.slideshare.net/takashiabe338/fast-rcnnfaster-rcnn
https://www.slideshare.net/takanoriogata1121/ssd-single-shot-multibox-detector-eccv2016
※訳には間違いがないよう注意を払いましたが、完全であることを保証できません。誤りがありましたらお教え願います。
原文:
Wei Liuら,(2016) SSD: Single Shot MultiBox Detector
概要:https://arxiv.org/abs/1512.02325
PDF:https://arxiv.org/pdf/1512.02325.pdf
SSD: Single Shot MultiBox Detector
概要
画像中の物体を単一のニューラルネットワークを使用して検出する手法を提案する.本手法はSSDと呼称するが,フィーチャマップの位置ごとに,アスペクト比とスケールに関係なくバウンディングボックスの出力空間をデフォルトボックスのセットへと離散化する.予測時においては,ネットワークは各デフォルトボックス中での各物体カテゴリの存在に関するスコアを生成し,ボックスに対してより物体の形にマッチするような調整を行う(produces adjustments).加えて,色々なサイズの物体を自然に扱うために,ネットワークは異なる解像度を持つ複数のフィーチャマップからの予測を組み合わせる.SSDは提案生成(proposal generation)とその後のピクセル又は特徴の再サンプリングを完全に廃しているため,物体提案(object proposals)を使用する手法に比べてシンプルであり,すべての計算を一つのネットワーク中にカプセル化する.このことはSSDを訓練しやすく,また物体検知コンポーネントを必要としているシステムに直接組み込みやすくする.PASCAL VOC, COCO, ILSVRCデータセットでの実験結果は,追加の物体提案ステップを利用する手法と互角の精度(accuracy)を持ち,かつずっと高速であることを示している.それでいてSSDは訓練と推定の両方を単一のフレームワークで実行可能である.300×300の入力に対して,VOC2007 testデータセットでSSDは74.3%のmAP1を達成した.ここではNvidia Titan Xを使用して59FPSであった.512×512の入力に対しては76.9%のmAPを達成し,競合する最先端のFaster R-CNNモデルを上回っている.他の単一ステージ手法と比較して,SSDはより小さい入力画像サイズでもずっと良いaccuracyを達成している.コードは https://github.com/weiliu89/caffe/tree/ssd から利用できる.
1後述する実験においてデータ拡張手法を改善してより良い結果を達成している:VOC2007において,300×300入力で77.2%mAP,AP512×512入力で79.8%mである.詳しくは3.6章を参照されたい.
**キーワード:**リアルタイム物体検出; 畳み込みニューラルネットワーク
1 導入
現在,最先端の物体検出システムは次に示す手法の変種となっている:バウンディングボックスを仮定(hypothesize)し,各ボックスそれぞれでピクセルや特徴を再サンプルし,高性能の分類器を適用する.このパイプラインはSelective Search[1]の研究から,[3]が示すようなよりディープな特徴を使ったFaster-RCNNに基づくPASCAL VOC, COCO, そしてILSVRCでの現在の最高結果にいたるまで,検出ベンチマークを打ち立ててきた.これらの手法は正確であるとはいえ,組込みシステムにおいてはあまりにも計算負荷が大きく,ハイエンドなハードウェアを使用してもリアルタイムでの応用には遅すぎる.これらの手法ではよく検出速度を1フレームに対する秒数(seconds per frame :SPF)で測定するが,最も高精度の検出器であるFaster R-CNNであっても,1秒間にたったの7フレーム(FPS)※訳者注1しか処理できない.高速な検出器を作るために検出パイプラインの各段階に対して多くの試みが行われているが(4章の関連研究を参照されたい),今までのところ,速度の大幅な改善は検出精度(detection accuracy)を大きく落とすという犠牲によってのみ実現するものとなっている.
本論文では,バウンディングボックス仮定時に特徴量やピクセルの再サンプルを行わなず,しかもその上それらを実施する手法と同等の精度を持つ最初のディープネットワークベースの物体検出器を提案する.このことは高精度検出(VOC2007 testにおいて,Faster R-CNNが73.2%mAPで7FPS,またはYOLOが63.4%mAPで45FPSなのに対して,74.3%mAPで59FPSを達成)での速度に大きな改善をもたらす.速度の改善は基本的にバウンディングボックス提案とそれに続くピクセルまたは特徴の再サンプル工程を取り除いたことによる.これを行ったのは私達が最初ではないが([4][5]を参照されたい),一連の改善を加えることで,従来の試みよりも精度を大幅に向上することに成功した.今回の改善には,小さな畳み込みフィルタを物体カテゴリの予測とバウンディングボックス位置の予測に使ったこと,異なるアスペクト比の検出に別々の予測器(フィルタ)を使ったこと,および検出を複数スケールで行うために,これらのフィルタをネットワークの後段からの複数のフィーチャマップへ適用したことが含まれる.これらの修正を行って,―特に,異なるスケールでの予測に複数レイヤを使って―比較的低い解像度の入力でも高い精度を達成することができ,さらに検出速度も向上した.これらの貢献は単独では小さく見えるかもしれないが,PASCAL VOCのリアルタイム検出においてYOLOでは63.4%mAPだったが,本提案のSSDでは74.3%mAPへと改善した.これは昨今,非常に注目を浴びているresidual networksの研究[3]での検出精度の改善よりも相対的に大きく改善している(This is a larger relative improvement).さらに,高精度の検出において速度を大きく改善することはコンピュータビジョンが有用となる領域の設定範囲を広めることにもなる.
本論文の貢献を以下のように要約した:
- 従来の最先端単発(single-shot)検出器(YOLO)よりも高速で大幅に精度が良い,複数カテゴリに対する単発の検出器であるSSDを導入した.実際には明示的な領域提案とプーリングを実施するより遅い技術(Faster R-CNNを含む)と同程度の正確さであった.
- SSDの核となるものは,フィーチャマップに対して小さな畳み込みフィルタを適用することで,デフォルトバウンディングボックスの固定セットに関してカテゴリスコアとボックスオフセットを予測することである.
- 高い検出精度を達成するために,異なるスケールのフィーチャマップから異なるスケールの予測を作り出し,アスペクト比によって明示的に予測を分割するようにした(explicitly separate predictions by aspect ratio).
- これらの設計の特徴は,たとえ低解像度の入力画像であっても,シンプルなエンドツーエンドの訓練と高いaccuracyにつながり,さらにスピードと精度のトレードオフを改善する.
- 実験は様々な入力サイズで,モデル時間と精度の解析を含めてPASCAL VOC, COCO, ILSVRCで検証し,近年の最先端手法と比較した.
※訳者注1 従来手法の測定単位「1フレームを何秒で処理するか(SPF)」に対し、それ以降では「1秒に何枚のフレームを処理できるか(FPS)」に着目している点に注意。
2 単発検出器(The Single Shot Detector:SSD)
本章では提案する検出フレームワークであるSSD(2.1章)と,関連するトレーニング手法(2.2章)を説明する.その後,3章ではデータセット特有のモデルの詳細と実験結果を述べる.
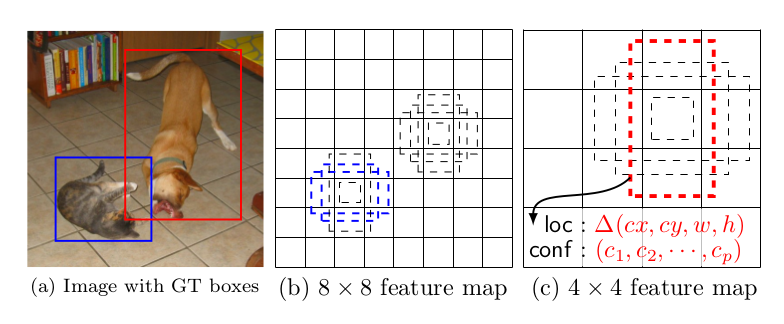
図1:SSDフレームワーク.(a)SSDが訓練中に必要とするのは入力画像と各物体それぞれの正解ボックスのみである.畳み込みのやり方(In a convolutional fashion)で,いくつかのフィーチャマップでの各位置において,異なるアスペクト比のデフォルトボックスの少数のセット(例えば4個)を,異なるスケールで評価する(例えば(b)と(c)の8×8と4×4).各デフォルトボックスそれぞれにつき,形のオフセットとすべての物体カテゴリ((c1,c2,...cp))に関する確信度(confidences)を予測(predict)する.訓練時には,最初にこれらのデフォルトボックスと正解(ground truth)のボックスのマッチを図る.例えば,2つのデフォルトボックスを1つは猫,1つは犬とマッチさせているが,これは正(positive)として扱われ,残りは負(negative)として扱われる.モデルの誤差は位置特定誤差(localization loss)(例えばSmooth L1[6])と確信度誤差(confidence loss)(例えばSoftmax)の間の重みつき和(weighted sum)である.
2.1 モデル
SSDの手法はフィードフォワード畳み込みネットワークに基づいているが,そこでは固定長サイズのバウンディングボックスの集まり(collection)を生成し,物体クラスの実体がそれらのボックスの中に存在することをスコア付けし,その後,最終的な検出を生成するためにnon-maximum suppression※訳者注2を行う.ネットワークの最初の方のレイヤは画像分類に使用される標準的なアーキテクチャに基づいており(分類レイヤの前で打ち切られるが),これをベースネットワーク2と呼ぶことにする.検出を生成するためにネットワークに補助的な構造を追加したが,主な特徴(key features)は以下の通りである:
2ベースにはVGG-16ネットワークを使用したが,ほかのネットワークでも良い結果が出るはずである.
※訳者注2 non-maximum suppression(NMS):
近隣ピクセルと注目しているピクセルの値を比較し、注目しているピクセルが最大値でないときは0にする処理
20170514追記:本論文においてこの意味で使用されているか未確認のため訂正
検出のためのマルチスケールフィーチャマップ
畳み込み特徴レイヤを打ち切られたベースネットワークの最後尾に追加した.これらのレイヤはサイズを大きく減少させ,マルチスケールでの検出の予測を可能にする.検出を予測するための畳み込みモデルは各特徴レイヤに関して異なっている(対照的に,Overfeat[4]やYOLO[5]は1つのスケールのフィーチャマップで操作を行う).
検出のための畳み込み予測器
追加された各特徴レイヤ(またはベースネットワークの既存の特徴レイヤとしてもよい)は畳み込みフィルタのセットを使って固定の検出予測のセットを生成可能である.これらは図2のSSDネットワーク構造のトップに示されている.pチャネルを持つサイズm×nの特徴レイヤに対して,潜在的な検出パラメータ予測のための基本要素は3×3×pの小さなカーネルであり,それはカテゴリのスコア,またはデフォルトボックスの座標に対しての形状オフセットを生成する.カーネルは,それが適用されるm×nの各位置において出力値を生成する.バウンディングボックスオフセットの出力値は,各フィーチャマップの位置に対するデフォルトボックスの位置に対して測定される(YOLO[5]のアーキテクチャがこのステップの畳み込みフィルタの代わりに中間の(intermediate)全結合レイヤを使用するのとは対照的である).
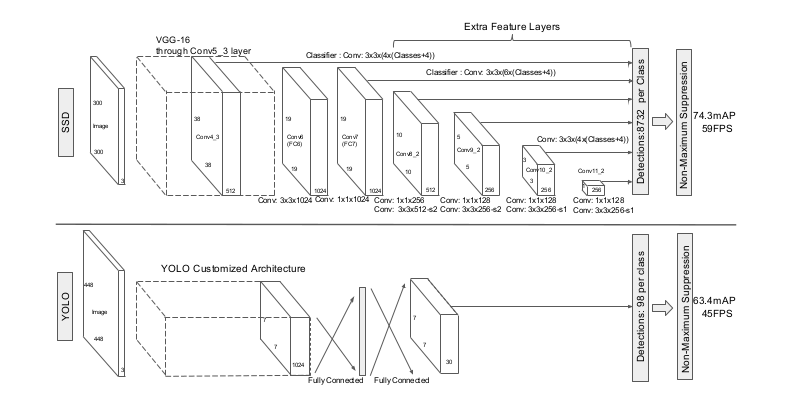
図2: 2つの単発(single shot)検出モデルの比較: SSDとYOLO[5].
SSDモデルはいくつかの特徴レイヤをベースネットワークの最後に追加するが,それは異なるスケールとアスペクト比のデフォルトボックスに対するオフセットとそれらに付随する確信度を予測する.accuracyに関して,300×300の入力サイズを持つSSDはVOC2007testにおいて448×448の対応するYOLOを大きく凌いでおり,スピードも向上している.
デフォルトボックスとアスペクト比
私たちは,ネットワークのトップで,複数フィーチャマップについて各フィーチャマップのセルとデフォルトバウンディングボックスのセットを関連付けている.その対応するセルに対して各デフォルトボックスの位置が固定されるように,デフォルトボックスは畳み込みのやり方でフィーチャマップを隙間なく敷き詰め(tile)ている.各フィーチャマップのセルにおいて,クラスのインスタンスがそれらの各ボックス中に存在することを示すクラスごとのスコアと同様に,セル中のデフォルトボックスの形状に対するオフセットを予測する.具体的には,ある位置でk個のボックスそれぞれについて(for each box out of k at a given location),c個のクラススコアと元のデフォルトボックスの形状に対するオフセット4つを計算する.この結果,フィーチャマップの各位置の周辺に適用されるフィルタは合計*(c+4)k個となり,m×nのフィーチャマップに関して(c+4)kmn個の出力を生成する.デフォルトボックスの説明は図1を参照されたい.本提案のデフォルトボックスはFaster R-CNN[2]で使用されているアンカーボックス*と類似しているが,本提案ではそれらを解像度の異なるいくつかのフィーチャマップに適用する.いくつかのフィーチャマップで異なるデフォルトボックスの形状を使用することは可能な出力されるボックスの形状を効率よく離散化(discretize)することを可能にする.
2.2 訓練
SSDと領域提案を使用する典型的な検出器の主な違いは,正解情報が検出器の出力の固定セット中の,特定の出力に対して割り当てられる必要があるということである.このことの一種はYOLO[5]やFaster R-CNN[2]とMultiBox[7]の領域提案工程の訓練でも必要とされている.この割当が一度決定されると,誤差関数とバックプロパゲーションがエンドツーエンドで適用される.訓練には,ハードネガティブマイニング(hard negative mining)とデータ拡張戦略,デフォルトボックスのセットおよび検出のスケールの選択も含まれる.
マッチング戦略
訓練中にはどのデフォルトボックスが正解の検出と対応するか決定する必要があり,ネットワークをそれに応じて訓練する.各正解ボックスについては,位置,アスペクト比,スケールが異なるデフォルトボックスから選択している.デフォルトボックスに対して,jaccard overlap(MultiBox[7]でも使用されている)※訳者注3の最良値で各正解ボックスのマッチを図ることから始める.MultiBoxとは異なり,本手法ではデフォルトボックスをjaccard overlapが閾値(0.5)よりも高い正解ボックスすべてとマッチさせる.このことはネットワークに複数の重なったデフォルトボックスについて高いをスコア予測させることを可能にし,最大の重複となる1つのデフォルトボックスだけを選択させる方法よりも学習問題をシンプルする.
※訳者注3 jaccard overlap:
類似度の指標Jaccard係数で、次の式で計算される。
|X ∩ Y| / |X ∪ Y|
訓練の目的
SSDの訓練の目的はMultiBoxでの目的[7][8]から派生しているが,複数の物体カテゴリを扱うために拡張されている.xpij = {1, 0}がカテゴリpでのi番目のデフォルトボックスとj番目の正解ボックスのマッチングを示すものとする.上記のマッチング戦略において,Σixpij ≥ 1を得ることができる.全体の目的誤差関数は位置特定誤差(loc)と確信度誤差(conf)の重み付き和である:
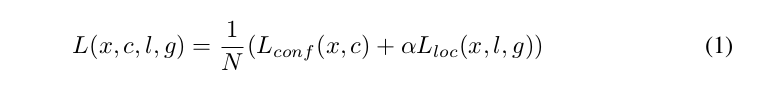
ここでNはマッチしたデフォルトボックスの数である.N = 0の場合は誤差を0とする.位置特定誤差は予測されたボックス(l)と正解ボックス(g)のパラメータ間でのSmooth L1誤差[6]である※訳者注4.Faster R-CNN[2]と同様,デフォルトバウンディングボックス(d)の中心(cx, cy)と,その幅(w)と高さ(h)についてオフセットを回帰する.※訳者注5

確信度誤差は複数クラスの確信度(c)に対するソフトマックス誤差である.
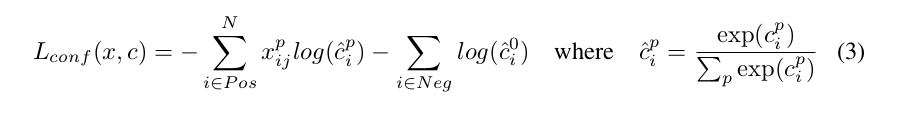
実験ではクロスバリデーションにより,重み項αは1にセットした.
※訳者注4 Smooth L1誤差:
次の式で計算される。Fast R-CNN[6]より引用。
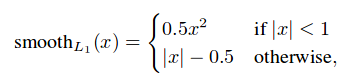
※訳者注5 位置特定誤差(式(2)):
- パラメータ(中心cx,cy,幅w,高さh)それぞれについて、正解ボックスとデフォルトボックスのオフセットを求め、予測したボックスとオフセットとのSmooth L1誤差を求める。
- マッチしたデフォルトボックス1つにつき、1.の結果(4つの誤差)を足し合わせる。
- マッチしたデフォルトボックスすべてについて2.を計算して足し合わせる。
デフォルトボックスのスケールとアスペクト比の選択
異なる物体スケールを扱うために,画像を異なるサイズで処理し,その結果を後で結合する手法を提案している研究がある[4][9].しかし,単一の予測ネットワーク中のいくつかの異なるレイヤからフィーチャマップを利用することで,すべての物体スケールについて同じパラメータを共有しながら,同様の効果を得ることが可能である.先行研究[10][11]は下位レイヤが入力物体の詳細をより良く捉えているため,下位レイヤからのフィーチャマップを使用することで意味分割(semantic segmentation)の品質を向上できることを示している.同様に[12]はフィーチャマップからプールされた全体の文脈(global context)を加えることで分割結果をスムーズにできることを示した.これらの手法を受けて,本手法では検出に下位と上位のフィーチャマップを使用する.図1はフレームワークで使用している2つの典型的なフィーチャマップ(8×8と4×4)を示している.実践的には,より多くのフィーチャマップを小さい計算コストオーバヘッドで使用できる.
1つのフレームワークの異なる階層からのフィーチャマップは異なる(経験的な)受容野サイズを持つことが知られている[13].幸運なことに,SSDフレームワークの中では,デフォルトボックスは実際の各レイヤの受容野と対応付ける必要はない.本手法では特定のフィーチャマップがある特定のスケールの物体を担当するように学習するよう,デフォルトボックスの敷き詰めを設計している.m個のフィーチャマップを予測に使用するものとする.各フィーチャマップについてのデフォルトボックスのスケールは次のように計算される:
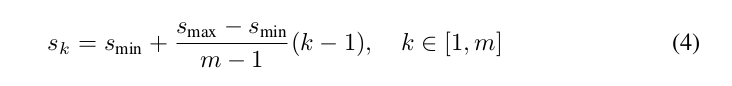
ここで*sminは0.2,smaxは0.9であり,最も下位のレイヤは0.2,最も上位のレイヤは0.9のスケールを持つこと意味する.その中間のすべてのレイヤは規則的に間隔を開けている.本手法ではデフォルトボックスに異なるアスペクト比を与えるが,それらをar ∈ {1, 2, 3, 1/2 , 1/3 }と記す.これにより各デフォルトボックスについて,幅(wak = sk √ar )と高さ(hak = sk / √ar )を計算できる.アスペクト比が1の場合は,スケールがs'k = √sksk+1 であるデフォルトボックスを追加し,フィーチャマップの位置ごとに6つのデフォルトボックスとなる.各デフォルトボックスの中央を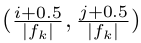 にセットするが,ここで| fk |*はk番目の正方フィーチャマップ(k-th square feature map)のサイズであり,*i, j ∈ [0, | fk |)*である.実践的には,デフォルトボックスの分布を特定データセットに最もフィットするように設計することも可能である.最適な敷き詰め(tiling)をどのように設計するもまたオープンクエスチョンである.
にセットするが,ここで| fk |*はk番目の正方フィーチャマップ(k-th square feature map)のサイズであり,*i, j ∈ [0, | fk |)*である.実践的には,デフォルトボックスの分布を特定データセットに最もフィットするように設計することも可能である.最適な敷き詰め(tiling)をどのように設計するもまたオープンクエスチョンである.
多くのフィーチャマップのすべての位置から,異なるスケールとアスペクト比のすべてのデフォルトボックスに関する予測を結合することで,多様な予測のセットを得ることができ,様々な入力の物体サイズと形状をカバーできる.例えば,図1では犬は4×4フィーチャマップ中のデフォルトボックスの中にマッチしているが,8×8フィーチャマップ中のデフォルトボックスには全くマッチしていない.この理由はそれらのボックスが異なるスケールを持っているため犬のボックスとマッチせず,したがって訓練中には負(negatives)とみなされるからである.
ハードネガティブマイニング(hard negative mining)
マッチング工程の後,特に可能なデフォルトボックスの数が大きい場合,多くのデフォルトボックスは負(negatives)となる.このことは正と負の訓練例の間に重大な不均衡をもたらす.すべての負の訓練例を使う代わりに,それらを各デフォルトボックスに対して最も高い確信度誤差でソートして,負と正の比率が最大でも3:1になるようにトップ1つを選び出す.私達はこれにより,より速い最適化とより安定した訓練に繋がることを発見した.
データ拡張
モデルを様々な入力物体サイズと形状に対してロバストにするために,各訓練画像は次に示すオプションによってランダムにサンプルされる:
- 元の入力画像全体を使用する.
- 物体との最小のjaccard overlapが0.1,0.3,0.4,0.7または0.9となるようにパッチをサンプルする.
- ランダムにパッチをサンプルする.
各サンプルパッチのサイズは元の画像サイズの[0.1, 1]で,アスペクト比は1/2と2の間である.サンプルパッチのなかに正解ボックスの中心がある場合には,正解ボックスの重複部分は保持するものとする(We keep the overlapped part of the ground truth box if the center of it is in the sampled patch.).前述のサンプリングステップの後に,各サンプルパッチは,[14]で説明されているものに類似のフォトメトリックな歪みを適用することに加えて,固定サイズにリサイズされ,確率0.5で水平にフリップされる.
3 実験結果
ベースネットワーク
今回の実験はすべてVGG16[15]に基づいているが,これはILSVRC CLS-LOCデータセット[16]で事前に訓練されている.DeepLab-LargeFOV [17]と同様に,fc6とfc7を畳み込みレイヤに変換し,fc6とfc7からパラメータを間引き,pool5を2×2―s2から3×3―s1に変更し,à trousアルゴリズム[18]を"穴(holes)"を埋めるために使用した.dropoutレイヤとfc8レイヤは全て取り除いた.このモデルを初期学習率10-3,モメンタム0.9,重み減衰0.0005,バッチサイズ32でSGDを使用しファインチューニングした.学習率の減衰ポリシーは各データセットごとに僅かに異なっているが,これは後に詳述する.訓練とテストのコード全体はCaffe[19]で作成されており,https://github.com/weiliu89/caffe/tree/ssd においてオープンソースとなっている.
3.1 PASCAL VOC2007
本データセットでは,VOC2007 test (4952枚)でFast R-CNN[6]およびFaster R-CNN[2]に対して比較を行った.すべての手法は同じVGG16ネットワークで事前訓練された.
図2はSSD300モデルのアーキテクチャの詳細を示す.conv4_3,conv7 (fc7),conv8_2,conv9_2,conv10_2,そしてconv11_2を位置と確信度両方の予測に使用した.conv4_3でのデフォルトボックスのスケールを0.1にセットした3.新しく追加された畳込みレイヤのパラメータはすべて"xavier"法[20]で初期化した.conv4_3,conv10_2,conv11_2については4つのデフォルトボックスを各フィーチャマップ位置に関連付けるにとどめた ― 1/3と3のアスペクト比は省略した.その他のすべてのレイヤについては,セクション2.2で説明したように6個のデフォルトボックスを設置した.[12]で指摘されているように,conv4_3はその他のレイヤに比べて異なるフィーチャスケールを持っている.そのため,フィーチャーマップ中の各位置における特徴ノルム(feature norm)を20へとスケールし,バックプロパゲーション中にスケールを学習させる目的で,本実験でも[12]で導入されているL2正規化(L2 Normalization)※訳者注6の手法を用いた.学習率10-3で40K回,その後学習率10-4と10-5で10K回繰り返して学習を続けた.VOC2007 trainvalで訓練した時,低解像度のSSD300モデルはすでにFast R-CNNよりも精度が良いことが表1からわかる.より大きい512×512の入力画像で訓練した場合,SSDはさらに精度が良くなり,Faster R-CNNをmAPで1.7%凌ぐ結果となった.より多くのデータ(すなわち07+12)で訓練した場合にはSSD300がすでにFaster R-CNNよりも1.1%,SSD512が3.6%上回っていることがわかる.COCO trainval35kで訓練したモデルを選び,07+12データセットでファインチューンした場合は,3.4章で説明するが,SSD512では最高結果:81.6%のmAPを達成した.
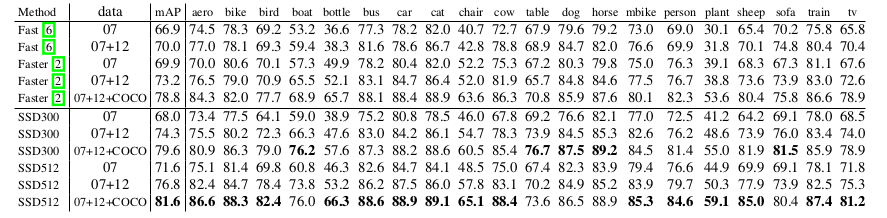
表1: **PASCAL VOC2007 test の検出結果.**FastとFaster R-CNNは最低次元数が600の入力画像を使用している.2つのSSDモデルはそれらが異なる入力サイズ(300×300と512×512)であることを覗いて全く同じ設定値である.より大きい入力サイズがより良い結果へ繋がることは明らかであり,より多くのデータは常に改善を助ける.データは次の通りである:”07”: VOC2007 trainval,”07+12”: VOC2007とVOC2012 trainvalを加えたもの.”07+12+COCO”: 最初にCOCO trainval35kで訓練し,その後07+12でファインチューニング.
3 SSD512モデルについては,さらにconv12_2を予測用に追加し,sminを0.15に設定,またconv4_3では0.07に設定した.
※訳者注6 L2 Normalization:
L2正規化(L2 Normalization)は対象のL2ノルムで対象自身を除す処理。L2正則化(L2 Reguralization)とは異なる。d次元ベクトルxのL2ノルムは次の式で計算される。ParseNet: Looking wider to see better.[12]より引用。
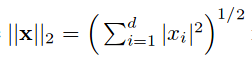
2つのSSDモデルの性能をより詳細に理解するため,[21]による検出解析ツールを使用した.図3はSSDが様々な物体カテゴリを高品質に検出できることを示している(大きい白い領域).その確信度の高い検出の大半は正解している.再現率(recall)は85―90%であり,”弱い”(jaccard overlapで0.1)基準よりもずっと高いものとなっている.
R-CNN[22]との比較は,SSDの位置特定誤差が小さいが,SSDが物体をより良く位置特定できることを示している.これはSSDが2つの別々の工程を使う代わりに,物体形状を回帰して物体カテゴリを分類することを直接学習することが理由である.ところが,SSDは類似の物体カテゴリ(特に動物)についてはより多くの取り違えを示しており,これは複数カテゴリの場所を共有している(share locations for multiple categories)ことが部分的な原因である.図4はSSDがバウンディングボックスサイズに対して非常に敏感であることを示している.言い換えれば,大きい物体と比べて小さい物体でのパフォーマンスが非常に悪いということである.そのような小さい物体はレイヤの最上位においては何の情報も持っていないことすらありうるため,これは驚くべきことではない.入力サイズを増加させること(例えば300×300から512×512)は小さい物体の検出を改善しうるが,それでも多くの改善の余地がある.良い面としては,大きい物体ではSSDが非常に良い性能を発揮することが明らかであることが挙げられる.またSSDは,フィーチャーマップの位置ごとに様々なアスペクト比のデフォルトボックスを使用しているため,異なるアスペクト比の物体に対して非常に頑健である.
3.2 モデル解析
SSDをより良く理解する目的で,各構成要素がどのくらい性能に影響するかを検証すべく対照実験を行った.すべての実験に関して,特定の設定や構成要素への変更を除いて,同じ設定と入力サイズ(300×300)を使用した.

表2:様々な設計の選択と構成要素によるSSDの性能への効果.
データ拡張は重要である.
FastおよびFaster R-CNNは元の画像とその水平フリップを訓練に使用している.本研究ではYOLO[5]と類似した,より拡張的なサンプリング戦略を用いている.表2はこのサンプリング戦略で8.8%のmAPを改善できることを示している.このサンプリング戦略がFastおよびFaster R-CNNに対してどの程度利益があるかわからないが,FastおよびFaster R-CNNは,分類中にフィーチャープーリング工程を使用しており,その設計上物体の変形に対して比較的頑健であることから,少ない利益しか得られないものと考えられる.
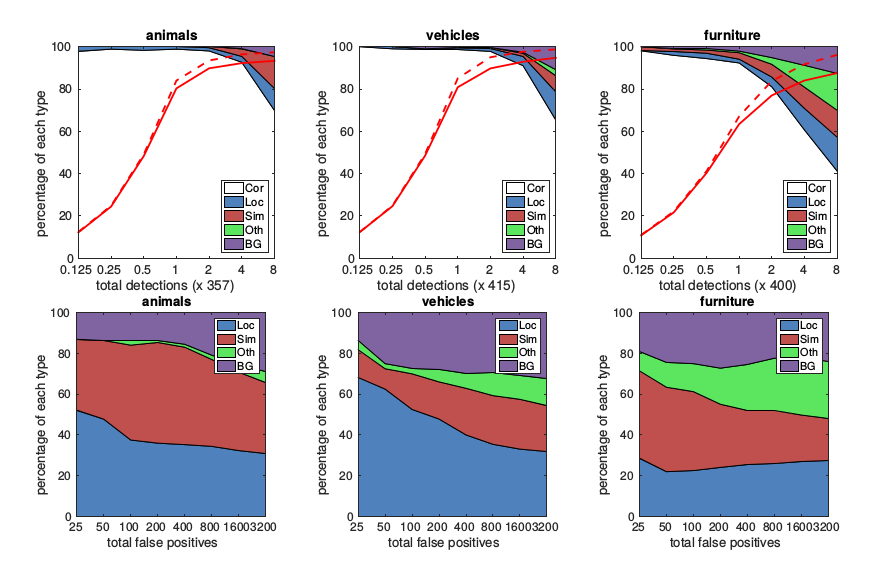
図3:**VOC2007 testでの動物,車,家具画像に対するSSD512の性能の可視化.**上段は,正解(Cor)または,位置特定に失敗(Loc),類似カテゴリとの取り違え(Sim),別の物体との取り違え(Oth),または背景との取り違え(BG)のいずれかによる偽陽性の検出結果の累積的な変動を示している.赤い実線は検出数の増加に伴う,強い基準(jaccard overlapが0.5)での再現率(recall)の変化を反映している.赤い破線は弱い基準(jaccard overlapが0.1)を使用している.下段はトップランクとなった偽陽性のタイプを示す.
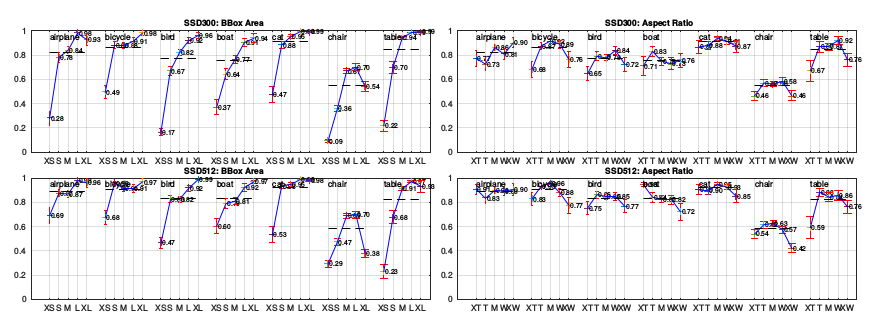
図4:**[21]を使用したVOC2007 testセットにおける異なる物体特性の影響と敏感さ.**左側のプロットはカテゴリごとのバウンディングボックス領域(BBox Area)の影響を示し,右はアスペクト比の影響を示す.キーは次の通り:
バウンディングボックス領域: XS=非常に小さい(extra-small); S=小さい(small); M=中間(medium); L=大きい(large); XL =非常に大きい(extra-large).
アスペクト比: XT=非常に縦長(extra-tall)/狭い(narrow); T=縦長(tall); M=中間(medium); W=横長(wide); XW=非常に横長(extra-wide).
デフォルトボックスの形状は多いほどよい.
2.2章で説明したように,デフォルトで場所ごとに6個のデフォルトボックスを使用している.1/3と3のアスペクト比のボックスを取り除いた場合,性能は0.6%低下する.さらに1/2と2のアスペクト比のボックスを除去すると,性能はさらに2.1%低下する.様々なデフォルトボックスの形状を使用するとボックスの予測タスクをネットワークにとってより簡単なものにできるようである.
Atrousはより高速である.
3章で説明したように,DeepLab-LargeFOV [17]に従って,サブサンプルされたVGG16のatrous版を使用した.完全なVGG16を使用した場合,2×2―s2のpool5を保持してfc6とfc7からパラメータを間引くことをせず,conv5_3を予測に追加することになるが,速度が約20%遅くなる一方で,結果は同じくらいである.
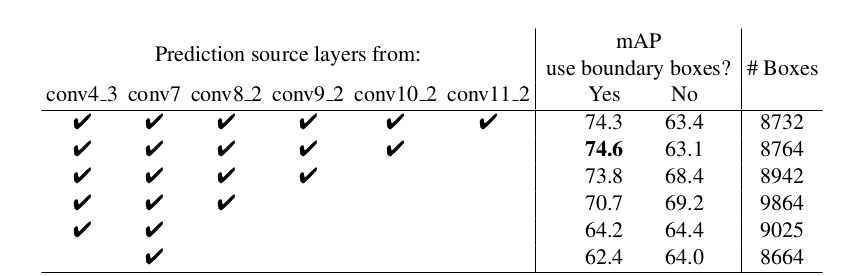
表3:複数出力レイヤを使用した効果.
異なる解像度において複数出力レイヤを使用すると良い.
SSDの主要な貢献は異なる出力レイヤで異なるスケールのデフォルトボックスを使用したことである.得られた利益を測定するために,徐々にレイヤを取り除いていき,結果を比較した.公平な比較のため,レイヤを取り除くときは常に,デフォルトボックスの敷き詰めをボックスの総数がオリジナル(8732)と類似し続けるように調整した.これは取り除かずに残ったレイヤで,オリジナルより多くのボックスのスケールを積み上げ(stacking),必要ならばボックスのスケールを調整することで実施された.表3はレイヤを少なくするとaccuracyが減少することを示しており,74.3から62.4へと単調に減少している.複数スケールのボックスを一つのレイヤに積み上げた場合,多くは画像の境界上に位置するため,注意深く扱わなければならない.境界上にあるボックスを無視するという,Faster R-CNN[2]で使用されている戦略を実施したところ,いくつかの興味深い傾向を観測できた.例えば,非常に粗いフィーチャマップ(例えばconv11_2(1×1)やconv10_2(3×3))を使用した場合に,大きなマージンによって性能が悪化する.この理由は,取り除いた(pruning)後に大きい物体をカバーするのに十分な大きさのボックスがないためと考えられる.元々良い解像度のマップを使用した場合,性能は再び向上し始めるが,これは取り除いた後でも十分な数の大きいボックスが残っているためと考えられる.予測にconv7のみを使用した場合,性能は最も悪くなり,このことは異なるレイヤに異なるスケールのボックスを広げる(spread)ことが重要というメッセージを強調している.加えて,本実験の予測が[6]におけるようなROI poolingに基づいていないため,低解像度のフィーチャマップでのcollapsing bins問題は発生しない.SSDのアーキテクチャは,低解像度の入力画像を使いながらも,Faster R-CNNと互角な精度を達成するために,様々な解像度のフィーチャマップからの予測を結合している.
3.3 PASCAL VOC2012
VOC2012trainval,VOC2007trainvalおよびtest(21503枚)を訓練に,またVOC2012test(10991枚)をテストに使用したこと以外は,上記の基本的なVOC2007での実験で使用したものと同じ設定を使用した.学習率10-3で60K回,その後10-4で20K回繰り返し学習させた.表4はSSD300とSSD5124モデルの結果を示す.VOC2007testで見た性能と同じ傾向が観察された.SSD300はFast/Faster R-CNNよりもaccuracyを向上させた.訓練とテストの画像サイズを512×512に増加させると,Faster R-CNNよりも4.5%精度が向上した.YOLOと比較して,SSDは大幅に正確であるが,これは複数フィーチャマップからの畳み込みデフォルトボックスの使用と,訓練中のマッチング戦略に起因するものと考えられる.COCOで訓練されたモデルからファインチューンした場合,SSD512は80.0%のmAPを達成し,これはFaster R-CNNよりも4.0%高い.

表4:**PASCAL VOC2012 testでの検出結果.**FastおよびFaster R-CNNは最小次元数600の画像を使用しており,YOLOの画像サイズは448×448である.dataは次の内容を示す:
”07++12”: VOC2007 trainval と test および VOC2012 trainvalを合わせたもの.”07++12+COCO”: 最初に COCO trainval35k で訓練し,その後07++12でファインチューニング.
4 http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?cls=mean&challengeid=11&compid=4
3.4 COCO
さらにSSDフレームワークを検証するため,SSD300とSSD512アーキテクチャをCOCOデータセットで訓練した.COCOの物体はPASCAL VOCよりも小さい傾向にあるため,すべてのレイヤでより小さいデフォルトボックスを使用した.2.2章で述べた戦略に従うが,今回は最も小さいデフォルトボックスのスケールを0.2の代わりに0.15とし,conv4_3のデフォルトボックスのスケールを0.07(例えば300×300画像に対しては21pxとなる)5とした.
trainval35k[24]を訓練に使用した.最初に10-3で160K回,その後10-4で40K回,10-5で40K回繰り返し学習を続けた.表5はtest-dev2015での結果を示す.PASCAL VOCデータセットで見たものと類似して,SSD300は0.5と[0.5:0.95]両方でFast R-CNNよりもmAPが高くなっている※訳者注7.SSD300は0.75でION[24]およびFaster R-CNN[25]と程度のmAPであるが,0.5では低いmAPとなっている.画像サイズを512×512に増加させると,SSD512モデルはどちらの基準でもFaster R-CNN[25]よりも良い結果である.興味深いことに,SSD512は0.75において5.3%良いmAPであるが,0.5ではたった1.2%高いのみである.また,大きい物体に対してAP(4.8%)とAR(4.6%)ではずっと良い結果であるのに,小さい物体に対してはAP(1.3%)およびAR(2.0%)と比較的改善が小さいことがわかる.
5 SSD512モデルについては,さらにconv12_2を予測用に追加し,sminを0.1に設定,またconv4_3では0.04に設定した.
※訳者注7 "0.5"や"[0.5:0.95]"は表5の"Avg.Precision,IoU:"列を指す。また、"AP"、"AR"はそれぞれ"Avg.Precision,Area:"、”Avg.Recall,Area:”列を指す。
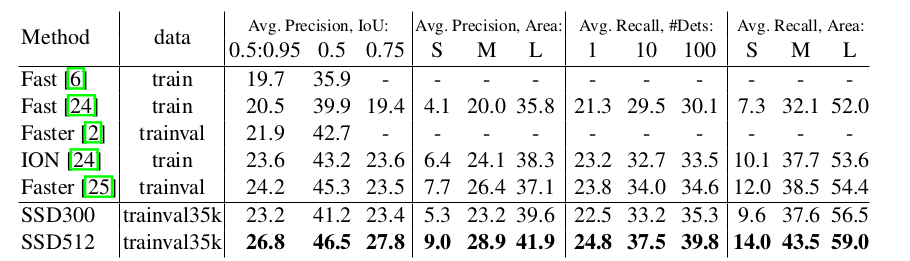
表5:COCO test-dev2015での検出結果.
IONと比較すると,大きい物体および小さい物体についてのARでの改善はより似通っている.小さい物体については,Faster R-CNNの方がSSDと競合すると考えているが,それはRPN部分とFast R-CNN部分の両方で,2回のボックス修正(refinement)工程を行うからである.図5にCOCO test-devでのSSD512モデルの検出例を示す.

図5:**COCO test-dev2015でのSSD512の検出例.**スコア0.6以上の検出を示している.各色は物体カテゴリに対応している.
3.5 ILSVRCでの結果(予備)
COCOで使用したものと同じネットワークアーキテクチャをILSVRC DETデータセット[16]に適用した.SSD300モデルを[22]で使用されているようにILSVRC2014 DET trainおよびval1で訓練した.最初に10-3で320K回,その後10-4で80K回,10-5で40K回繰り返し学習を続けた.43.4mAPをval2セット[22]で達成した.この結果によりSSDが高品質リアルタイム検出のための汎用的なフレームワークであることが再び示された.
3.6 小さい物体のaccuracyのためのデータ拡張
Faster R-CNNに倣ったフィーチャリサンプリング工程なしでは,解析(図4を参照)で示されたように,小さい物体の分類タスクはSSDにとって比較的難しい.2.2章で説明したデータ拡張戦略は,特にPASCAL VOCのような小さいデータセットでは,性能を劇的に向上させる.本戦略によって生成されるランダムクロップは”ズームイン”の操作であると考えることができ,多くの大きい訓練例を生成できる.より多くの小さい訓練例を生成する”ズームアウト”操作を実装するため,最初に,ランダムクロップ操作をする前の平均値で埋められた,元画像サイズの16倍のキャンバス上にランダムに画像を配置する.この新しい”拡大”データ拡張トリックの導入により訓練画像が多くなるため,訓練回数を2倍にする必要がある.表6に示すように,複数データセットで一貫して2%-3%のmAPの増加が見られた.具体的には,図6は新しいデータ拡張トリックが小さい物体での性能を大幅に向上させることを示している.この結果は最終的なモデルのaccuracyのためのデータ拡張戦略の重要性を強調している.
SSDを改善する別の方法は,フィーチャマップ上の各受容野とデフォルトボックスの位置およびスケールがより良く揃うように,デフォルトボックスのより良い敷き詰めを設計することである.これは今後の課題である.
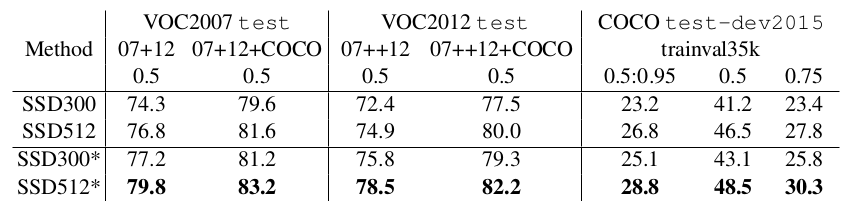
表6:**画像拡大データ拡張トリックを付加した場合の複数データセットでの結果.**SSD300とSSD512は新しいデータ拡張で訓練されたモデルである.
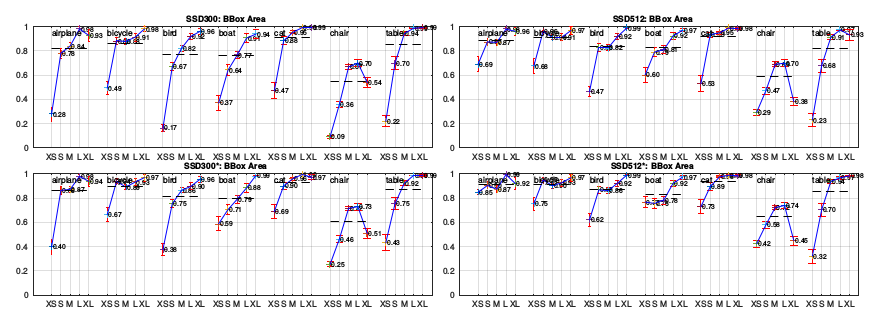
**[21]を使用したVOC2007 testセットでの新しいデータ拡張による物体サイズの影響と敏感さ.**上段は,元々のSSD300とSSD512モデルでのカテゴリごとのバウンディングボックス領域の影響を示しており,下段は新しいデータ拡張トリックで訓練されたSSD300およびSSD512モデルに対応する.新しいデータ拡張トリックが小さい物体の検出を大幅に助けることは明らかである.
3.7 推定時間
本手法で生成される大量のボックスを考えると,推定中にon-maximum suppression(nms)を効率的に実行することは必要不可欠である.確信度の閾値を0.01とすることで,殆どのボックスを取り除くことができる.その後nmsを1クラスごとにjaccard overlap 0.45で適用して,画像1枚ごとにトップ200個の検出を保持しておく.この工程はSSD300でVOCの20クラスの場合,画像1枚ごとに約1.7ミリ秒を要するが,これは新たに追加されたすべてのレイヤで費やされる合計時間(2.4ミリ秒)と近い.速度はバッチサイズ8でIntel Xeon E5-2667v3 @3.20GHzでTitan XとcuDNN v4を使用して計測した.
表7はSSD,Faster R-CNN[2],YOLO[5]の比較を示す.SSD300とSSD512の手法はFaster R-CNNを速度とaccuracyの両面で凌いでいる.Fast YOLO[5]は155FPSで実行できるが,これはaccuracyにおいて22%近く低い.私達の知る限り,SSD300は70%以上のmAPを達成する最初のリアルタイム手法である.計算時間の約80%はベースネットワーク(今回はVGG16)に費やされていることを注記しておく.したがって,より速いベースネットワークならばさらなる速度の改善も可能であり,SSD512モデルをリアルタイムにすることも可能である.
4 関連研究
画像中の物体検出手法には2つの確立されたクラスがあるが,1つはスライディングウィンドウに基づき,もう1つは領域提案分類に基づいている.畳み込みニューラルネットワークの出現前には,これら2つの手法の最先端― Deformable Part Model (DPM)[26]およびSelective Search[1] ―は互角の性能であった.しかしながら,selective searchの領域提案と畳込みネットワークベースの事後分類を組み合わせたR-CNN[22]によって劇的な改善がもたらされた後は,領域提案物体検出手法が流行することとなった.
オリジナルのR-CNN手法は様々な方法で改善されてきた.最初の手法セットは,大量の画像クロップの分類が必要であり計算コストと時間がかかったため,事後分類の速度と品質を改善した.SPPnet[9]はオリジナルR-CNN手法の速度を大幅に向上した.そこでは領域サイズとスケールに対してより頑健なspatial pyramid pooling層が導入され,いくつかの解像度で生成されたフィーチャマップ上で計算された特徴を再利用することを可能にした.Fast R-CNN[6]はSPPnetを拡張し,確信度とバウンディングボックス回帰の誤差を最小化することにより,すべてのレイヤをエンドツーエンドでファインチューニングできるようにした.これはMultiBox[7]でobjectnessを学習するために最初に導入されたものである.
2つ目の手法セットはディープニューラルネットワークを用いて領域生成の品質を向上させる.MultiBox[7][8]のような最も最近の研究では,低レベルな画像特徴に基づいているSelective Searchの領域提案が,別々のディープニューラルネットワークによって直接生成された提案に置き換わっている.これは検出精度を更に改善するが,幾らか設定が複雑となり,互いに依存関係のある2つのニューラルネットワークを訓練する必要がある.Faster R-CNN[2]はselective search手法を領域提案ネットワーク(RPN)から学習したもので置き換えており,RPNをR-CNNと統合する手法を導入している.これはこれらの2つのネットワークでファインチューニング用の共有された畳込み層と予測層を交代することでなされる(by alternating between fine-tuning shared convolutional layers and prediction layers for these two networks).このように領域提案は中間レベルの特徴をプールするために使用され,最終的な分類工程はより低コストとなる.SSDはFaster R-CNNにおける領域提案ネットワーク(RPN)と非常に類似しており,固定セットの(デフォルト)ボックスを予測に使用しているが,これはRPNでのアンカーボックスに近い.しかし,これらを特徴をプールして別の分類器で評価する代わりに,本提案では各ボックス中での各カテゴリについてのスコアを同時に生成している.それ故に,本手法はFast R-CNNとRPNをマージする複雑さを回避しており,訓練しやすく,速く,他のタスクにも簡単に統合できる.
もうひとつの手法セットは,直接的に本手法に関連するが,提案工程を完全に廃して複数カテゴリの確信度とバウンディングボックスを直接予測するものである.OverFeat[4]はスライディングウィンドウ手法をディープにしたものであるが,根底にある(underlying)物体カテゴリの確信度を得た後に,最上位フィーチャマップの各位置からバウンディングボックスを直接予測する.YOLO[5]は最上位のフィーチャマップ全体を複数カテゴリの確信度とバウンディングボックス(ボックスはこれらのカテゴリで共有されている)の両方を予測するのに使用する.SSDは提案工程を持たず,デフォルトボックスを使用するためこのカテゴリに含まれる.しかしながら,異なるスケールの複数フィーチャマップから,各フィーチャ位置において,異なるアスペクト比のデフォルトボックスを使用できるため,本手法は既存の手法よりも柔軟である.もし最上位のフィーチャマップから,1つの位置に関して1つのボックスしか使用しなければ,SSDはOverFeat[4]と類似のアーキテクチャとなるだろう;もし最上位のフィーチャマップ全体を使用して,畳み込み予測器の代わりに予測のために全結合層を追加するなら,そして明示的に複数アスペクト比を考慮しないならば,YOLO[5]をほぼ再現できるだろう.
5 結論
本論文では,複数カテゴリのための高速な単発物体検出器であるSSDを導入した.本モデルの主要な特徴は複数スケールの畳込みバウンディングボックスを使用していることであり,その出力はネットワークの最上位で複数フィーチャマップと結合されている.この構造により,可能なボックスの形状空間を効率よくモデル化することができる.適切な訓練戦略を与えられれば,慎重に選択されたデフォルトバウンディングボックスは数が多いほど性能の改善につながることを実験的に検証した.私達は位置,スケール,そしてアスペクト比をサンプリングして,既存手法[5][7]よりもボックス予測が少なくとも1桁多くなる形でSSDモデルを構築した(We build SSD models with at least an order of magnitude more box predictions sampling location, scale, and aspect ratio, than existing methods [5,7]).同じVGG-16をベースアーキテクチャに使用しながら,SSDがその対応する最先端の物体検出器に比べて,速度と精度の両面で好ましい結果であることを示した.また,SSD512モデルは最先端のFaster R-CNNをPASCAL VOCおよびCOCOでのaccuracyにおいて大幅に上回っており,なお3倍も高速である.リアルタイムのSSD300モデルは59FPSで実行可能で,これは現在の別のリアルタイム手法であるYOLO[5]よりも高速であり,検出精度においても著しく優れた結果を出している.
その単独での実用性とは別であるが,画期的で比較的シンプルなSSDモデルは物体検出コンポーネントを採用するより大きなシステムに有用な構成要素を提供するものと考えられる.有望な今後の方向としては,動画中の物体検出および追跡を同時に行うために,リカレントニューラルネットワークを用いたシステムの一部としての利用を研究することが挙げられる.
6 謝辞
本研究はGoogleでのインターンシッププロジェクトとして開始され,UNCで継続している.助けになる議論をしてくれたAlex Toshevと,GoogleのImage UnderstandingチームおよびDistBeliefチームに感謝したい.役に立つコメントを頂いたPhilip AmmiratoおよびPatrick Poirsonにも感謝している.GPUの提供を頂いたNVIDIA,およびNSF 1452851,1446631,1526367,1533771からのサポートに感謝の意を表したい.
引用文献
- Uijlings, J.R., van de Sande, K.E., Gevers, T., Smeulders, A.W.: Selective search for object recognition. IJCV (2013)
- Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. In: NIPS. (2015)
- He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR.(2016)
- Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., LeCun, Y.: Overfeat: Integrated recognition, localization and detection using convolutional networks. In: ICLR. (2014)SSD: Single Shot MultiBox Detector 17
- Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: CVPR. (2016)
- Girshick, R.: Fast R-CNN. In: ICCV. (2015)
- Erhan, D., Szegedy, C., Toshev, A., Anguelov, D.: Scalable object detection using deep neural networks. In: CVPR. (2014)
- Szegedy, C., Reed, S., Erhan, D., Anguelov, D.: Scalable, high-quality object detection. arXiv preprint arXiv:1412.1441 v3 (2015)
- He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional networks for visual recognition. In: ECCV. (2014)
- Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR. (2015)
- Hariharan, B., Arbeláez, P., Girshick, R., Malik, J.: Hypercolumns for object segmentation and fine-grained localization. In: CVPR. (2015)
- Liu, W., Rabinovich, A., Berg, A.C.: ParseNet: Looking wider to see better. In: ILCR. (2016)
- Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Object detectors emerge in deep scene cnns. In: ICLR. (2015)
- Howard, A.G.: Some improvements on deep convolutional neural network based image classification. arXiv preprint arXiv:1312.5402 (2013)
- Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: NIPS. (2015)
- Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: Imagenet large scale visual recognition challenge. IJCV (2015)
- Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected crfs. In: ICLR. (2015)
- Holschneider, M., Kronland-Martinet, R., Morlet, J., Tchamitchian, P.: A real-time algorithm for signal analysis with the help of the wavelet transform. In: Wavelets. Springer (1990) 286–297
- Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., Darrell, T.: Caffe: Convolutional architecture for fast feature embedding. In: MM. (2014)
- Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: AISTATS. (2010)
- Hoiem, D., Chodpathumwan, Y., Dai, Q.: Diagnosing error in object detectors. In: ECCV 2012. (2012)
- Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR.(2014)
- Zhang, L., Lin, L., Liang, X., He, K.: Is faster r-cnn doing well for pedestrian detection. In:ECCV. (2016)
- Bell, S., Zitnick, C.L., Bala, K., Girshick, R.: Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In: CVPR. (2016)
- COCO: Common Objects in Context. http://mscoco.org/dataset/ #detections-leaderboard (2016) [Online; accessed 25-July-2016].
- Felzenszwalb, P., McAllester, D., Ramanan, D.: A discriminatively trained, multiscale, de-
formable part model. In: CVPR. (2008)