YARNでMapReduceジョブが失敗したとき、往々にして各NodeManagerで実行されたタスクのログを確認する必要があります。数ノードクラスタであればそれほど苦になりませんが、数十、数百ノード以上のクラスタにおいてすべてのログを収集するのは困難です。トラブルシューティングする前に、必要なログを集めるために悩まなければなりません。
Clouderaのサポートチームでは、YARNアプリケーションが失敗した際の解析のために、YARNサービスのログの他に、Cloudera Manager(CM)が提供している「YARNアプリケーション診断データの収集」機能を使ってお客様から一括でログを提供頂いています。GUIから操作可能なので、簡単に必要なログを収集でき、お客様にとってもサポートチームにとっても非常に有用な機能です。これは、Cloudera Managerを使用していれば誰でも(Clouderaのサブスクリプションを未購入でも)取得可能なので、その方法を紹介します。
まず、CMのトップページからクラスタ >> アクティビティ:YARNアプリケーション を選択します。
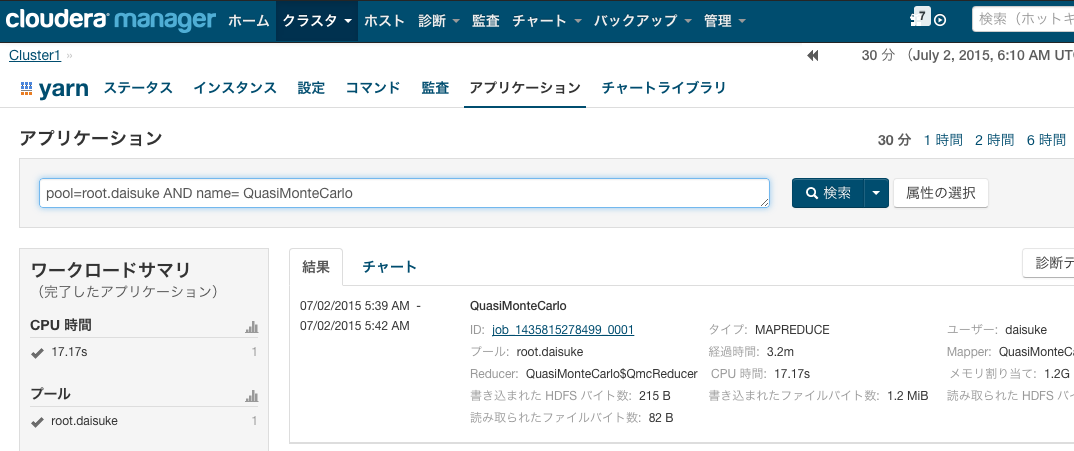
実行中、完了済みのYARNアプリケーションの一覧が表示されます。必要に応じて、調査対象のアプリケーションを特定します。下記例では、"root.daisuke"というプールに投入された"QuasiMonteCarlo"というジョブを抽出しています。
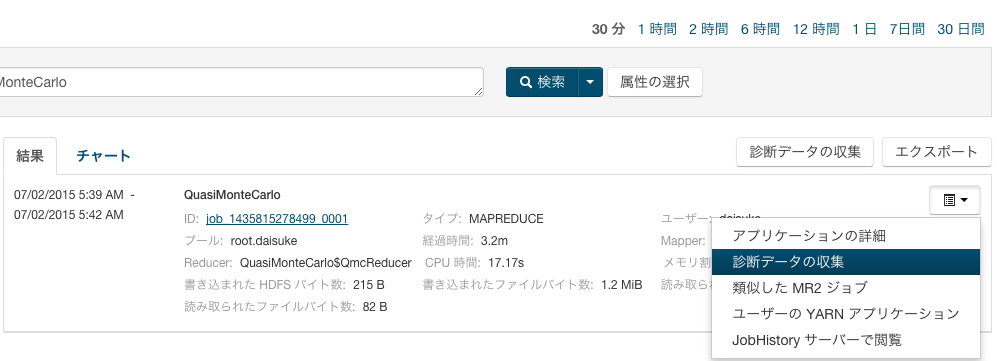
右のドロップダウンメニューから、「診断データの収集」をクリックします。
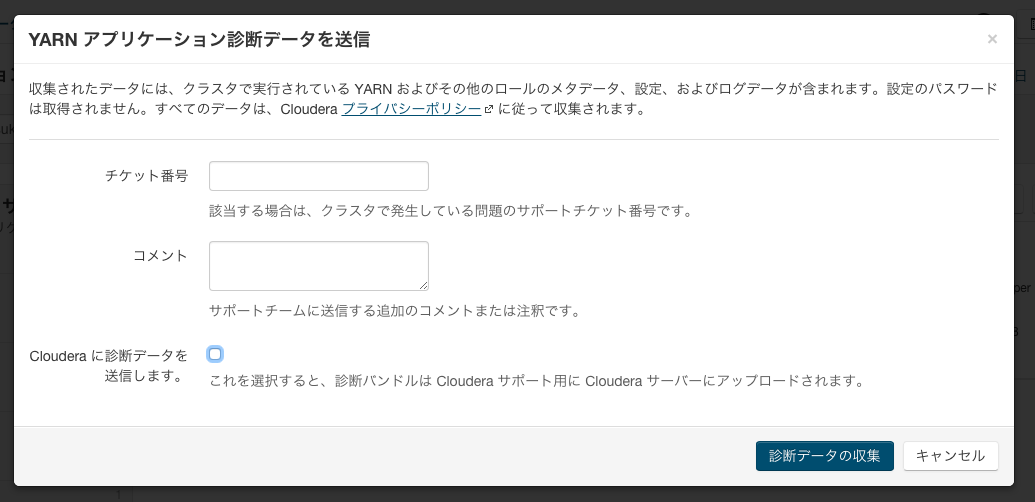
収集ウィザードではサポートチケット番号などを入力する項目がありますが、無視します。また、「Clouderaに診断データを送信します。」もチェックを外します。
実際の収集ステップです。大まかに何をやっているのかがわかります。タスクが実行されている全ホストからログを収集しているわけですね。
実行が完了しました。「結果データのダウンロード」から収集結果をダウンロードしましょう。"Stderr"というリンクをクリックすると、実際に内部で実行されているコマンドが確認可能です。
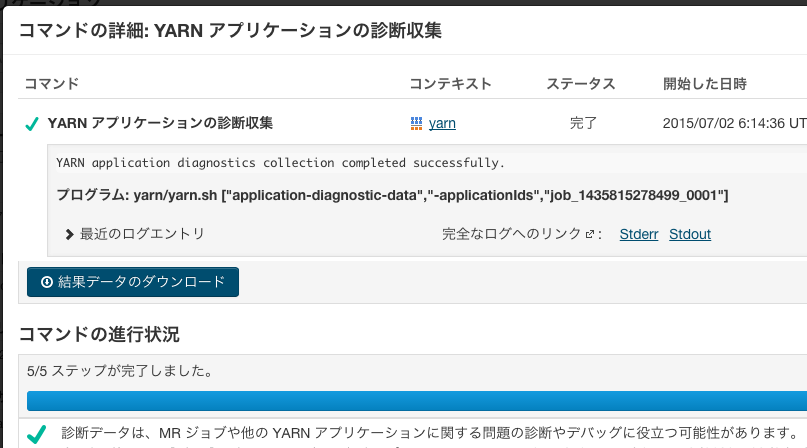
ダウンロードしたファイルを解凍し、展開後のディレクトリ内にあるYarnApplicationDiagnosticsCollection-XXX.tgzというファイルを解凍します
ディレクトリ構造は以下のようになっています。ジョブのConfigurationやCounterがJSON形式で収集されています。また、タスクのログはaggregated_logs配下に収められています。
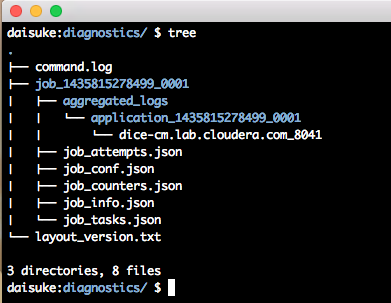
JSONファイル名と中身の対応は以下のとおりです。改行が省かれているので、適宜整形ツールを使って表示するとよいでしょう。
- job_info.json: ジョブのメタデータ。起動/完了時刻や、mapper/reducerの数など
- job_tasks.json: ジョブの各タスクのステータス
- job_counters.json: ジョブのCounter
- job_conf.json: ジョブのConfiguration
- job_attempts.json: ジョブの試行に関する情報。起動/完了時刻や、ログをJobHistoryServerから参照するためのリンクなど
もちろん、YARNモードで実行したSparkのアプリケーションログも収集可能で、以下のような構造でログやアプリケーションのメタデータが格納されています。
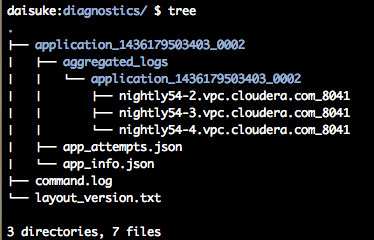
以上です。Cloudera Managerの仕組みについては以下の記事も参考になると思います。
Cloudera Managerの仕組み その1
Cloudera Managerの仕組み その2
基本的な使い方を知る上では下記ドキュメントもご覧ください。
Cloudera Manager 日本語ドキュメント 5.0.0 ドキュメント
また、Clouderaでは月次でCloudera Manager勉強会を開催し、機能紹介やデモを中心に弊社のエンジニアが講師を務めています。次回の開催日時はニュースレターで案内しているので、購読希望の方は info-jp@cloudera.com に件名: ML_SUBSCRIBE でメールをお送りください