chainer CRF 検索
v.1.13.0 から存在が確認されている chainer.functions.crf1d を使うテスト
リンク
- CRFを作るぞというセルフ issue
- crf1d の実装
- crf1d を使う例
- pfnet/chainer の postagging ブランチにPOSタギングの例がありました:
CRF
CRF 自体は最近のものではありませんから、みなさんよくご存知だと思います.
crf1d の実装に当ってリファーされてる論文を私は読んでなく、chainer実装しか読んでないのですが、これCRFと等価なんですか?
表現力がかなり限定されてる気がするのですが...
使用例を読まずにいきなり crf1d の実装を読むとわけがわからない気がします.
x って書かれると層への入力と思ってしまいますし.
以下はchainer実装を読んでの私の解釈です.
系列ラベリング
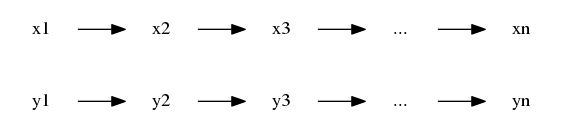
入力は何かしらの列:
$$x = x_1, x_2, x_3, \ldots, x_n$$
で、これから同じ長さの列
$$y_1, y_2, y_3, \ldots, y_n.$$
を予測したい.
(典型的なタスク例としては、POSタグ予測. $x$ が文すなわち語の列で、各語についてPOS (品詞) をラベリングする.)
ここで $y_i$ はラベル (離散値).
ラベル集合の大きさを $k$ として
$y_i \in {0,1,\ldots,k - 1} = \mathcal{Y}$
だとする.
すぐに思いつく方法としては $y_i$ を予測するのに $x_i$ 及びその周辺 ($x_{i-2} \ldots x_{i+2}$ くらい) を素性とすること.
次の絵は $y_2$ を $x_1, x_2, x_3$ から予測する感じの絵.
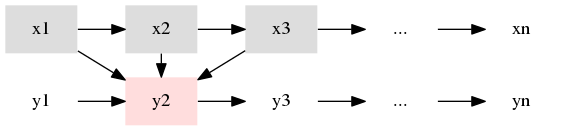
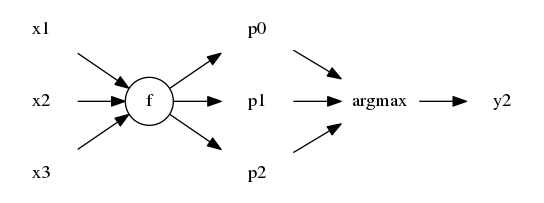
同様に $1 \leq i \leq n$ について $y_i$ を $f(x_{i-1}, x_i, x_{i+1})$ で予測する.
もちろん $y_i$ は離散値なので $f(..) \in \mathbb{R}^k$ として値が最大と成るインデックス (argmax) を予測ラベルとするわけ.
$f$ 自体はお好きな NNs を組めば実現できる.
また、列の両端 ($y_1$, $y_n$) を予測するために、仮想的な $x_0$ 及び $x_{n+1}$ を付け足す必要がある.
自然言語処理界隈では、入力が文の場合、よく bos (begin-of-sentence), eos (end-of-sentnece) とか、HTML風に <s> </s> という他と被らない特別なラベルを用いる.
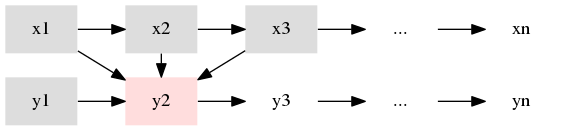
ところで、それが本当に一つの列なら、その順序に関して何かしらの傾向があっても良いはずである.
このラベルの次にこのラベルが来やすい、来にくい、みたいな.
chainer.links.CRF1d は __call__ が損失関数、 argmax が予測関数として設計されている.
損失関数では $f$ によって予測された列 $y' = y_1', y_2', \ldots, y_n'$ と、
正解の列 $y = y_1, y_2, \ldots, y_n$ とを比較するが、
それに加えて $y_{i-1}, y_i$ $(i=2,\ldots,n)$ を比較して、このラベルの次にこのラベルは来にくいハズ、という傾向をコストという形で損失に加える.
そのようなコストは学習時に逆伝播され、また予測では $f$ による予測にこのコストを加味する.
$y_i$ の予測に $x_i$ 及びその周辺のみならず、$y_{i-1}$ も実質的に素性に用いていることになる.
実装 (利用例)
使い方の心は分かったので実際に使ってみる.
文 (文字の列とみなします) から顔文字を検出することを目指します.
(顔文字検出を大昔にやってたことがあって、その痕跡を見つけたから思いついたのだけど、別に大量の訓練データがあるとかではない.)
これは系列ラベリングでも区間を検出するタスクなのでIOBタグを付けることにします.
IOBタグについては https://en.wikipedia.org/wiki/Inside_Outside_Beginning などを参照ください.
標準入力から訓練データを読みます.
一行一文 (200文字以下を仮定) で、<>と <> に囲まれた部分を顔文字だとして学習します.
コード
結果
test = '世界が平和でありますように( ;´Д`)'
# =>
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 2, 2, 2]
# 世界が平和でありますように<>( ;´Д`)<>
というわけで 世界が平和でありますように( ;´Д`) のうち ( ;´Д`) が顔文字と検出されました.
初め $y_i$ の予測に先に説明した例のように $x_{i-1},x_i,x_{i+1}$ (ウィンドウ幅 3) を素性に試したのですが、顔文字検出の場合、ちょっとこれは足りないようです. 例えば、この顔文字の括弧が本来の意味の括弧として使われてるかどうかなんて前後1文字だけではちょっとむずかしいです. ) なんて一つ前がただの半角空白で一つ次が文末なので. 上のうまく行った例はウィンドウ幅を5にして試した結果です。コードもそうなっています。