畳み込みニューラルネットワークと機械学習分類器
畳み込みニューラルネットワーク(CNN)の分類層を他の機械学習分類器に置き換えることができます。
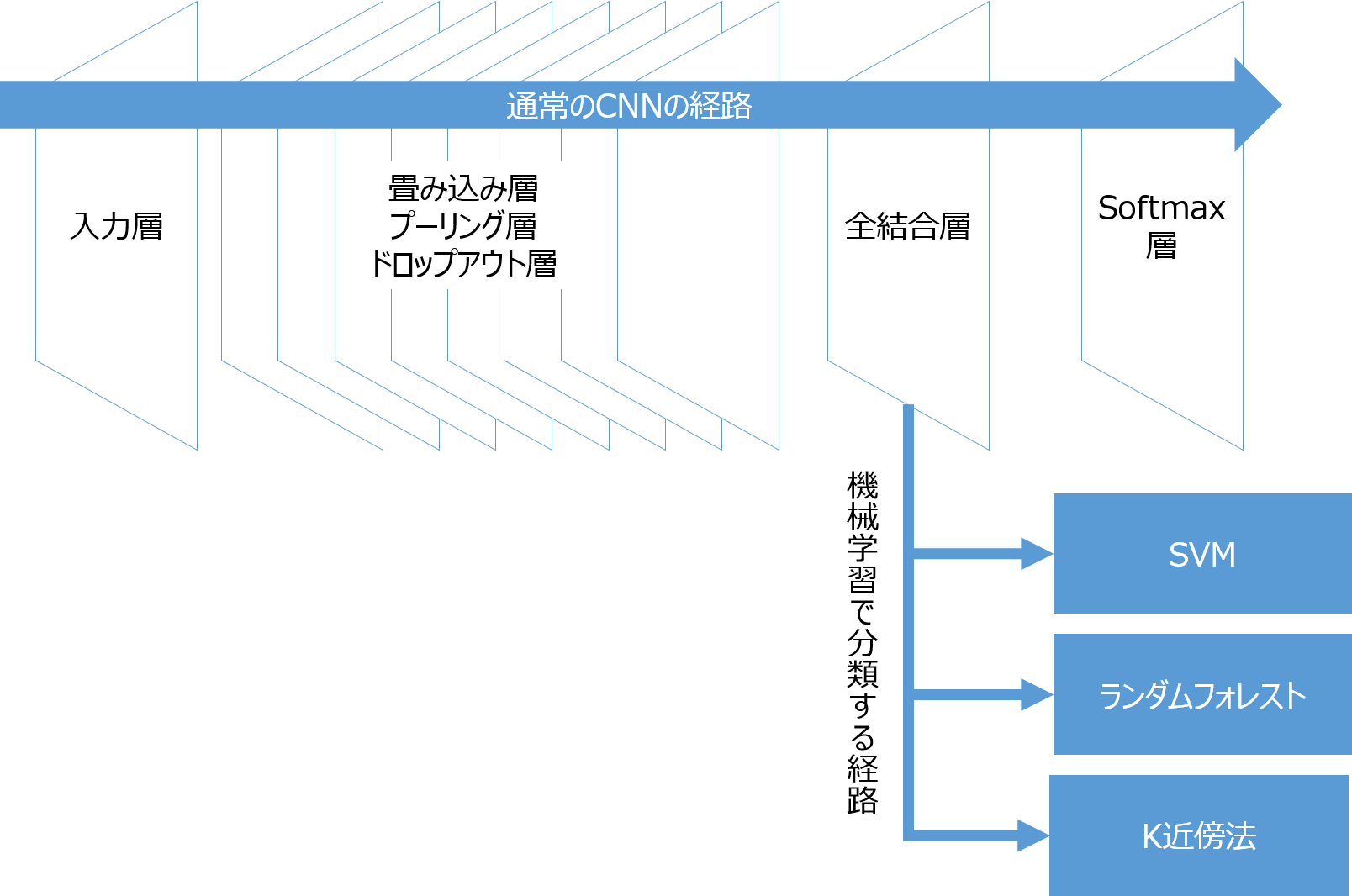
畳み込みニューラルネットワークは以下のような構造をしていますが、このうちSoftmaxより上位の層は特徴抽出を目的としています。
そこで、特徴抽出層の出力を使って他の機械学習で学習し分類器を作ることも可能です。
今回はCifar10をCNNで学習したのち、Softmax層を機械学習のSVM、ランダムフォレスト、K近傍法に置き換えて分類してみたいと思います。
ニューラルネットワークはKeras、機械学習にはscikit-learnを使って実装します。
なお、作ったプログラムはGithubにアップロードしましたので、全文はこちらをご参照ください。
https://github.com/shibuiwilliam/Keras_Sklearn
Cifar10のCNNモデル
CNNはVGGを模したものを使います。
構成は以下のとおりです。
Kerasのレイヤー定義です。
featureLayer1=[Conv2D(64, (3, 3), padding='same',input_shape=x_train.shape[1:]),
Activation('relu'),
Conv2D(64, (3, 3), padding='same'),
Activation('relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25)]
featureLayer2=[Conv2D(128, (3, 3), padding='same'),
Activation('relu'),
Conv2D(128, (3, 3), padding='same'),
Activation('relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25)]
featureLayer3=[Conv2D(256, (3, 3), padding='same'),
Activation('relu'),
Conv2D(256, (3, 3), padding='same'),
Activation('relu'),
Conv2D(256, (3, 3), padding='same'),
Activation('relu'),
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25)]
fullConnLayer=[Flatten(),
Dense(1024),
Activation('relu'),
Dropout(0.5),
Dense(1024),
Activation('relu'),
Dropout(0.5)]
classificationLayer=[Dense(num_classes),
Activation('softmax')]
model = Sequential(featureLayer1 + featureLayer2 + featureLayer3 + fullConnLayer + classificationLayer)
CNNでの分類能力は以下のとおりです。
テストデータに対するConfusion Matrix、精度(Precision)、再現率(Recall)、F1値、正答率を出力しています。

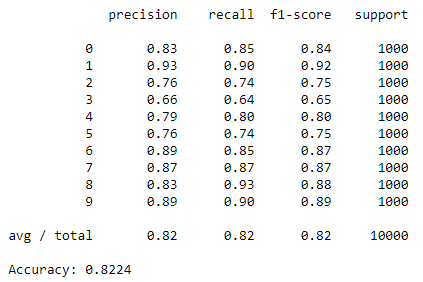
正答率82.24%で、まあまあです。
特徴抽出器をつくる
CNNモデルの層一覧は以下のとおりです。
# Layers definitions
from keras import backend as K
for l in range(len(model.layers)):
print(l, model.layers[l])
'''
0 <keras.layers.convolutional.Conv2D object at 0x7fbc0fa597f0>
1 <keras.layers.core.Activation object at 0x7fbc344a9ef0>
2 <keras.layers.convolutional.Conv2D object at 0x7fbc0fa59978>
3 <keras.layers.core.Activation object at 0x7fbc0fa59ac8>
4 <keras.layers.pooling.MaxPooling2D object at 0x7fbc0fa59b38>
5 <keras.layers.core.Dropout object at 0x7fbc0fa59be0>
6 <keras.layers.convolutional.Conv2D object at 0x7fbc0fa597b8>
7 <keras.layers.core.Activation object at 0x7fbc0fa59d68>
8 <keras.layers.convolutional.Conv2D object at 0x7fbc0fa59dd8>
9 <keras.layers.core.Activation object at 0x7fbc0fa59f28>
10 <keras.layers.pooling.MaxPooling2D object at 0x7fbc0fa59f98>
11 <keras.layers.core.Dropout object at 0x7fbc0fa4e080>
12 <keras.layers.convolutional.Conv2D object at 0x7fbc0fa59780>
13 <keras.layers.core.Activation object at 0x7fbc0fa4e208>
14 <keras.layers.convolutional.Conv2D object at 0x7fbc0fa4e278>
15 <keras.layers.core.Activation object at 0x7fbc0fa4e3c8>
16 <keras.layers.convolutional.Conv2D object at 0x7fbc0fa4e438>
17 <keras.layers.core.Activation object at 0x7fbc0fa4e588>
18 <keras.layers.pooling.MaxPooling2D object at 0x7fbc0fa4e5f8>
19 <keras.layers.core.Dropout object at 0x7fbc0fa4e6a0>
20 <keras.layers.core.Flatten object at 0x7fbc0fa59c18>
21 <keras.layers.core.Dense object at 0x7fbc0fa4e748>
22 <keras.layers.core.Activation object at 0x7fbc0fa4e8d0>
23 <keras.layers.core.Dropout object at 0x7fbc0fa4e908>
24 <keras.layers.core.Dense object at 0x7fbc0fa4e940>
25 <keras.layers.core.Activation object at 0x7fbc0fa4eac8>
26 <keras.layers.core.Dropout object at 0x7fbc0fa4eb00>
27 <keras.layers.core.Dense object at 0x7fbc0fa4e0b8>
28 <keras.layers.core.Activation object at 0x7fbc0fa4ec88>
'''
上記のうち、0層目から26層目までを特徴抽出器にします。
なお、27層目が全結合層(出力10)、28層目がSoftmax Activationで、分類器になっています。
特徴抽出層と分類層を切り離し、特徴抽出器をつくるにはKeras Backendのfunctionを使います。
backend.functionを使うと、Keras tensorをつかって独自の入力・出力のファンクションを作ることができます。
https://keras.io/backend/
以下ではCNNモデルの入力をfunctionの入力、26層目の出力をfunctionの出力としています。
要はCNNモデルを26層目でぶった切っています。
# feature extraction layer
from keras import backend as K
getFeature = K.function([model.layers[0].input, K.learning_phase()],
[model.layers[26].output])
なお、上記のK.learning_phase()は判定フェーズとして使うか学習フェーズで使うかを意味しています。
0が判定、1が学習です。
このファンクションの使って入力(Cifar10の画像データ)から特徴抽出します。
exTrain3000 = getFeature([x_train[:3000], 0])[0]
exTest1000 = getFeature([x_test[:1000], 0])[0]
入力値としてトレーニングデータの最初の3000画像を判定フェーズで使います。
同様にテストデータの最初の1000画像を判定しています。
特徴抽出器の出力は1024のテンソルになります。そのため、1画像が1024のテンソルとして出力されます。
ここで学習データを3000画像に絞っているのは、全データを指定すると拡張されすぎてJupyterのカーネルが死ぬからです。私の環境では3000行くらいが限界でした。
(どなたか回避方法をご存知のかた、教えてください)
さて、今回はScikit-learnの機械学習を分類器にします。
ターゲット変数もScikit-learnで使えるように変形します。
y_train3000 = y_train[:3000].reshape(y_train[:3000].shape[0],)
y_test1000 = y_test[:1000]
print(exTrain3000.shape, exTest1000.shape, y_train3000.shape, y_test1000.shape)
'''
(3000, 1024) (1000, 1024) (3000,) (1000, 1)
'''
以降ではScikit-learnのSVM、ランダムフォレスト、K近傍法を分類器に使ってみます。
各分類手法の比較は以下をご参照ください。
http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
SVM
SVMで分類してみます。
トレーニングデータは説明変数がexTrain3000、ターゲット変数がy_train3000、テストデータは説明変数がexTest1000、ターゲット変数がy_train1000になります。
CNNのトレーニングデータが5万画像なのに対し、SVMの画像数が3000なのは心もとないですが、ひとまずやってみましょう。
SVMのパラメータ・チューニングはGridSearchCVを採用し、最も良かったモデルをテストデータで評価します。
# import SVC and GridSearchCV
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
# parameters for GridSearchCV
parameters = {'kernel':['rbf'],
'C':[1, 10, 100, 1000],
'gamma':[1e-3, 1e-4]}
# GridSearchCV
clf = GridSearchCV(SVC(), parameters)
clf.fit(exTrain3000, y_train3000)
# train SVC with searched paramters
svmclf = clf.best_estimator_
svmclf.fit(exTrain3000, y_train3000)
# predict test data
y_testSVM = svmclf.predict(exTest1000)
# get metrics
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
print_cmx(y_test1000.T[0], y_testSVM)
print(classification_report(y_test1000, y_testSVM))
print("Accuracy: {0}".format(accuracy_score(y_test1000, y_testSVM)))
結果は以下のとおりで、Softmaxよりも良い正答率を出しています。
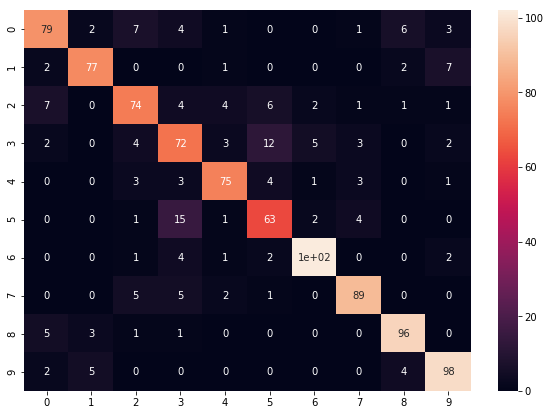
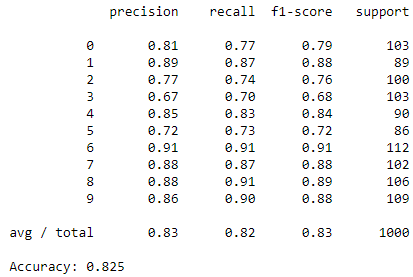
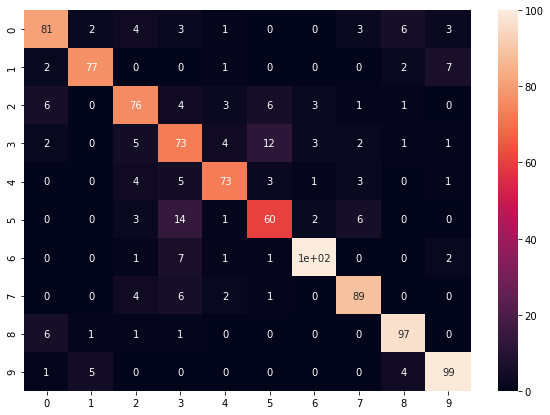
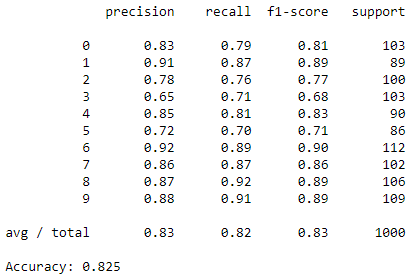
ランダムフォレスト
続いてランダムフォレストです。
方針はSVMと同じです。
# import RandomForestClassifier and GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# parameters for GridSearchCV
parameters = {"max_depth": [3, None],
"max_features": [1, 3, 10],
"min_samples_split": [1.0, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
"n_estimators": [10, 20, 50]}
# GridSearchCV
rclf = RandomForestClassifier()
rgclf = GridSearchCV(rclf, param_grid=parameters)
rgclf.fit(exTrain3000, y_train3000)
# train RandomForestClassifier with the searched parameter
rclf = rgclf.best_estimator_
rclf.fit(exTrain3000, y_train3000)
# predict test data
y_testRF = rclf.predict(exTest1000)
# get metrics
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
print_cmx(y_test1000.T[0], y_testRF)
print(classification_report(y_test1000, y_testRF))
print("Accuracy: {0}".format(accuracy_score(y_test1000, y_testRF)))
結果は以下です。
Softmaxより良い結果になりました。
K近傍法
最後にK近傍法です。
# import KNeighborsClassifier and GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# parameters for GridSearchCV
parameters = {"n_neighbors": [1, 5, 10, 30],
"weights": ['uniform', 'distance'],
"metric": ['minkowski','euclidean','manhattan'],
"algorithm": ['auto', 'ball_tree', 'kd_tree', 'brute']}
# GridSearchCV
kclf = KNeighborsClassifier()
kgclf = GridSearchCV(kclf, param_grid=parameters)
kgclf.fit(exTrain3000, y_train3000)
# train KNeighborsClassifier with the searched parameter
kclf = kgclf.best_estimator_
kclf.fit(exTrain3000, y_train3000)
# predict test data
y_testKNN = kclf.predict(exTest1000)
# get metrics
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
print_cmx(y_test1000.T[0], y_testKNN)
print(classification_report(y_test1000, y_testKNN))
print("Accuracy: {0}".format(accuracy_score(y_test1000, y_testKNN)))
結果は以下です。
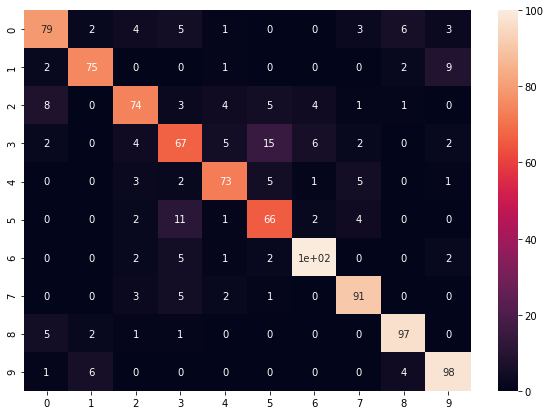
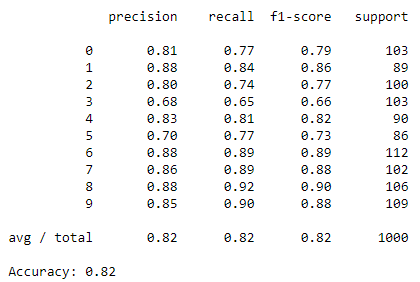
Softmax分類にわずか及ばず。
おわりに
Cifar10のデータに対して、CNNを特徴抽出器にしてSVM、ランダムフォレスト、K近傍法で分類してみました。
CNNの分類器はSoftmaxがデフォルトになっていますが、これはSoftmaxが実装、チューニングともに容易だからだと思います。
他の機械学習を使おうとすると、そのチューニングが必要になります。
今回の実験では、分類器としての能力はSoftmaxよりもSVM、ランダムフォレスト、K近傍法のほうが優れていることが結果になりました。
目的やデータ次第だと思いますが、CNNの分類器を機械学習に取り替えてみると便利だと思います。
今回の反省は機械学習のトレーニングでCifar10の全トレーニングデータを使えなかったことです。カーネル死の回避方法は別途検討します。