Kerasで重回帰分析
ディープラーニング(というかKeras)で簡単な重回帰分析をやってみました。
ディープラーニングというと分類問題や強化学習のイメージがありますが、別に回帰分析ができないわけではありません。
ニューラルネットワークは回帰分析にも使われるものなので、ディープラーニングでも回帰分析をしてみよう、という試みです。
作ったコードはここにあります。
https://github.com/shibuiwilliam/keras_regression_sample
今回やること
KerasのKerasRegressorというAPIを使って重回帰分析を行います。
データはscikit-learnが提供している糖尿病患者のサンプルデータです。
回帰分析ではよく使われるもので、小さくて便利なデータになっています。
今回の目的はディープラーニングやニューラルネットワークで回帰分析を実行する手順を書くことです。
ただし、ディープラーニングで回帰分析モデルを作れば精度が向上する、というわけではありません。
あと、今回は回帰分析といってもRNNやLSTMによる時系列数値データ予測ではありませんので、ご注意ください。
補足:機械学習について
機械学習やディープラーニングのモデルをすごくざっくり位置づけるとこんな感じになると思います。
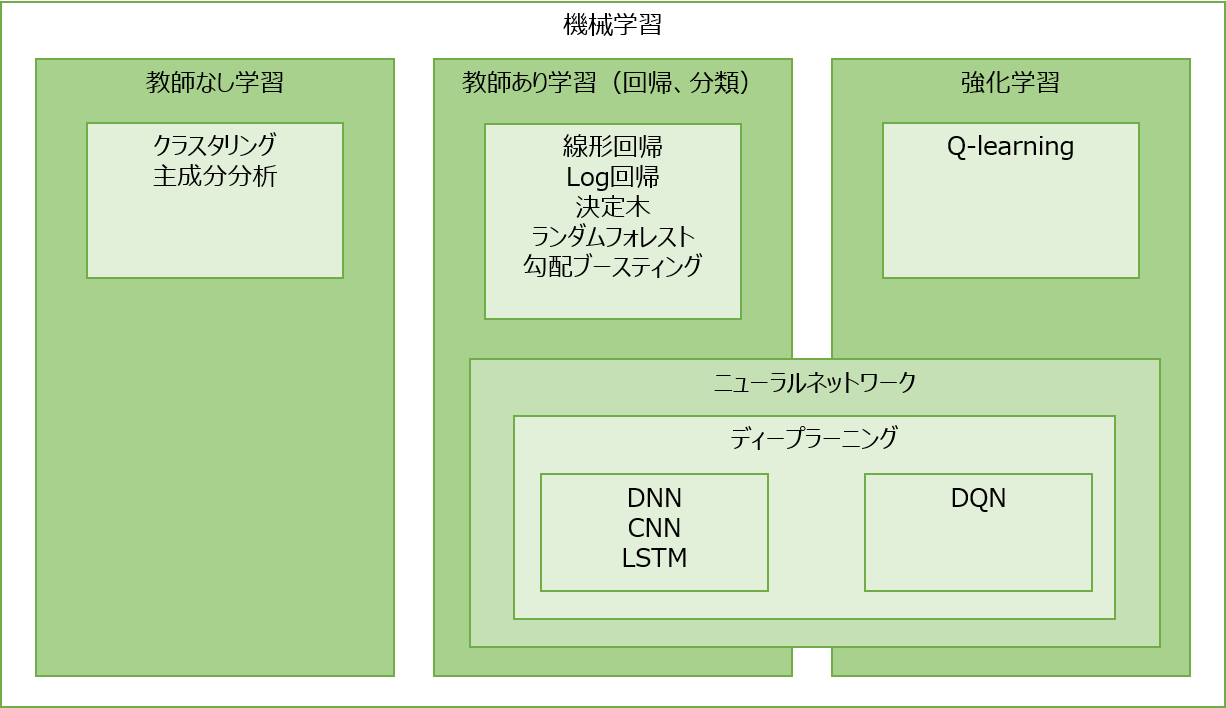
毎日のような新たな論文やモデルが提案されているので、これが全てではないと思いますが、おおまかなイメージです。
今回はやることはこの中のDNNです。
事前準備
事前準備としてデータをロードします。
# import libraries
import numpy as np
import pandas as pds
from keras.models import Sequential
from keras.layers import Input, Dense, Dropout, BatchNormalization
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_diabetes
# use diabetes sample data from sklearn
diabetes = load_diabetes()
# load them to X and Y
X = diabetes.data
Y = diabetes.target
こんな感じのデータがロードされます。
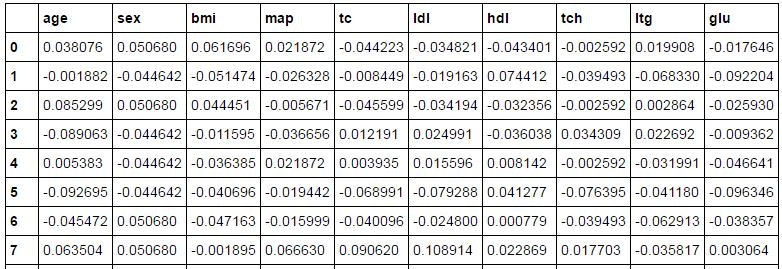
すでに正規化済みのようですね。
行数442、入力変数10という小さいサンプルデータです。
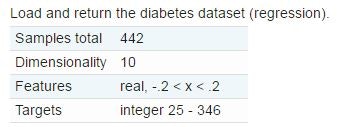
データの詳細はここをご参照ください。
http://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf
KerasRegressor
KerasではKerasRegressorという回帰分析用のAPIを提供しています。
https://keras.io/ja/scikit-learn-api/
Keras自体は大して詳しい説明を書いていませんが、要はscikit-learnの回帰モデルのラッパーらしいです。
おそらくKerasRegressorはscikit-learnの回帰分析向けの便利なメトリック系API(cross_val_scoreとかmean_squared_errorとか)と一緒に使えるように作られたものだと思います。
ニューラルネットワークモデルの書き方自体はKerasそのものです。
まずはシンプルなモデル(入力層、中間層、出力層が各1層)を作ってみます。
# create regression model
def reg_model():
model = Sequential()
model.add(Dense(10, input_dim=10, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1))
# compile model
model.compile(loss='mean_squared_error', optimizer='adam')
return model
サマリーを取るとこんな感じです。
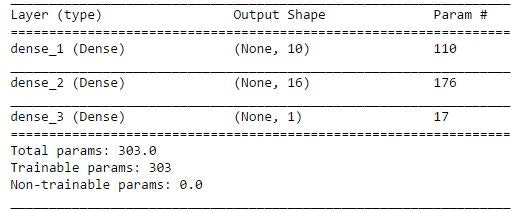
ここまでは従来のKerasそのままです。
従来との違いは学習する際のfitの書き方です。
学習する方法は概ね2通りあります。
1.トレーニングデータとテストデータを分けて学習
2.交差検証で学習
回帰分析で一般的な方法が使えるようです。
例1 トレーニングデータとテストデータを分けて学習
上記のシンプルなモデルについて、トレーニングデータとテストデータを分けて学習してみましょう。
# use data split and fit to run the model
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.1, random_state=0)
estimator = KerasRegressor(build_fn=reg_model, epochs=100, batch_size=10, verbose=0)
estimator.fit(x_train, y_train)
y_pred = estimator.predict(x_test)
# show its root mean square error
mse = mean_squared_error(y_test, y_pred)
print("KERAS REG RMSE : %.2f" % (mse ** 0.5))
最後に標準出力で平均二乗誤差の平方根(root mean squared erro)を出しています。
書き方はscikit-learnぽいです(が、そもそもKerasがscikit-learnぽい)。
例2 交差検証で学習
続けて交差検証で学習してみましょう。
# use Kfold and cross validation to run the model
seed = 7
np.random.seed(seed)
estimator = KerasRegressor(build_fn=reg_model, epochs=100, batch_size=10, verbose=0)
kfold = KFold(n_splits=10, random_state=seed)
# show its root mean square error
results = cross_val_score(estimator, X, Y, scoring='neg_mean_squared_error', cv=kfold)
mse = -results.mean()
print("KERAS REG RMSE : %.2f" % (mse ** 0.5))
ここでも最後に平均二乗誤差の平方根を出しています。
それぞれの結果を並べてみましょう。
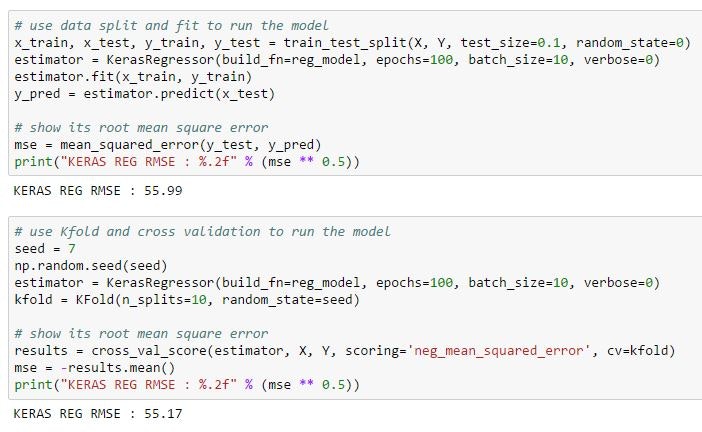
まあ大差ないですね。
試しにネットワークレイヤーを深くしてみましょう
ここまでシンプルなニューラルネットワークで重回帰分析をしました。
今度は試しにネットワークレイヤーを深くてしてみましょう。
# create deep learning like regression model
def deep_reg_model():
model = Sequential()
model.add(Dense(10, input_dim=10, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(256, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(1))
# compile model
model.compile(loss='mean_squared_error', optimizer='adam')
return model
せっかくなのでBatchnormalizationとDropoutを入れてみました。

それでは学習してみます。
# use data split and fit to run the model
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.1, random_state=0)
estimator = KerasRegressor(build_fn=deep_reg_model, epochs=100, batch_size=10, verbose=0)
estimator.fit(x_train, y_train)
y_pred = estimator.predict(x_test)
# show its root mean square error
mse = mean_squared_error(y_test, y_pred)
print("KERAS REG RMSE : %.2f" % (mse ** 0.5))
# use Kfold and cross validation to run the model
seed = 7
np.random.seed(seed)
estimator = KerasRegressor(build_fn=deep_reg_model, epochs=100, batch_size=10, verbose=0)
kfold = KFold(n_splits=10, random_state=seed)
# show its root mean square error
results = cross_val_score(estimator, X, Y, scoring='neg_mean_squared_error', cv=kfold)
mse = -results.mean()
print("KERAS REG RMSE : %.2f" % (mse ** 0.5))
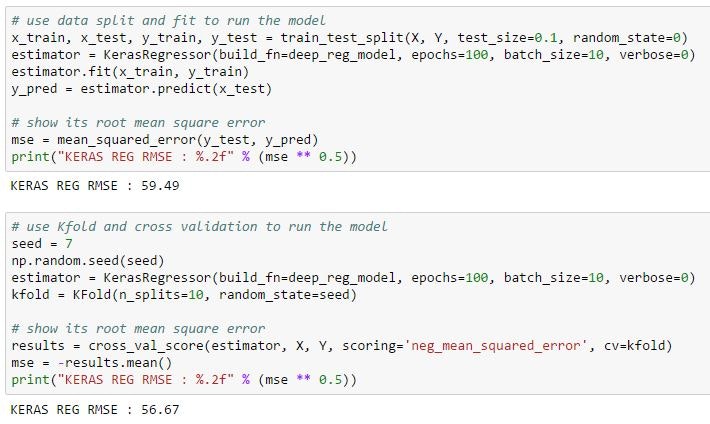
シンプルなネットワークと比較しても大差ないですね。
計算時間を考えると、深くする意味は見出だせません。
最後に
KerasRegressorで重回帰分析をやってみました。
たぶん同じことをやってみた人はごまんといるのでしょうが、ググってもあまり例がないのは、たぶん精度が飛躍的に良くなるものでもなかったからでしょう(なげやり)。
まあ、もっと大きくて複雑なデータで試せば、なにか違うことが言えるのかもしれませんので、良さそうなデータを見つけたら、また試してみます。
参考
https://keras.io/ja/scikit-learn-api/
http://machinelearningmastery.com/regression-tutorial-keras-deep-learning-library-python/
http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html
http://qiita.com/TomokIshii/items/f355d8e87d23ee8e0c7a
http://s0sem0y.hatenablog.com/entry/2016/05/22/215529