サマリ
- ギター画像の分類モデルの学習データに対して意図的にノイズを加えることで、分類の安定性を改善した。
動作環境等については、前回投稿 機械学習によるギター画像の分類 その1 を参照ください。
2017/10/23追記:
本投稿の内容は、Cutout1 / Random Erasing2という手法と類似のものだそうです。
2018/02/25追記:
ノイズ付与による誤識別の誘発は、敵対的摂動と呼ばれ、活発に研究されているようです。
本記事のトピックは単に『汎化性能が低くて困ったな』的な話ですが、敵対的摂動の研究では、もっと巧みな騙し方や、それから守るための方法(ロバスト化)について、主にセキュリティ的な観点から議論されています。
敵対的摂動に関しては、大変良いまとめが公開されていたので、リンクしておきます。
課題
前回投稿のチャレンジでは、入力画像へのわずかな落書きで分類予測結果が全く変わってしまうという現象が見られました。これは即ち、識別対象の一部が少しでも何かに隠れると予測不可能な誤分類を起こす、ということを示しています。
人間の認識能力はもっとロバストで、多くの場合、対象の一部が見えなくても総合的な判断で物体を識別することができます。
機械学習モデルの判別能力に、もっとロバスト性を与えられないでしょうか。
入力画像へのノイズ付与
前回投稿のチャレンジで使用した学習データは、殆どがECサイトの商品画像などの「綺麗な」写真でした。認識対象が別の何かで部分的に隠れているような画像はほぼありません。こういった理想的な条件では、局所的な特徴だけを見ても(例えば、ピックアップやコントロールのレイアウトだけ)うまくクラスを判別できるので、「全体を見て複合的に特徴を捉える」というモデルは育たない気がします。(理想的な条件へオーバーフィットし、汎化性能を獲得できない)
ならば、「全体を見て複合的に特徴を捉えなければうまく判別ができない」という構図を作ってしまいましょう。
やることは単純で、学習データの一部をランダムに隠してしまいます。こうすれば、一部の局所的な特徴のみではクラス判別が困難となり、必然的に、より大域的・複合的な特徴を選択的に学習するようになるはずです。
今回は、下記のようなコードで学習データに複数の矩形を書き加えました。
def add_dust_to_batch_images(x):
batch_size, height, width, channels = x.shape
for i in range(0, batch_size):
num_of_dust = np.random.randint(32)
dusts = zip(
(np.clip(np.random.randn(num_of_dust) / 4. + 0.5, 0., 1.) * height).astype(int), # pos x
(np.clip(np.random.randn(num_of_dust) / 4. + 0.5, 0., 1.) * width).astype(int), # pos y
np.random.randint(1, 8, num_of_dust), # width
np.random.randint(1, 8, num_of_dust), # height
np.random.randint(0, 256, num_of_dust)) # brightness
for pos_y, pos_x, half_w, half_h, b in dusts:
top = np.clip(pos_y - half_h, 0, height - 1)
bottom = np.clip(pos_y + half_h, 0, height - 1)
left = np.clip(pos_x - half_w, 0, width - 1)
right = np.clip(pos_x + half_w, 0, width - 1)
x[i, top:bottom, left:right, :] = b
return x
# ...
noised_train_flow = ((add_dust_to_batch_images(x), y) for x, y in train_flow)
矩形の数・位置・サイズ・明るさはランダムです。被写体のギターは中央付近に映っていることが多いと思うので、矩形もなるべく中央付近に多く分布するようにしています。
実際に加工された画像がこれです。

ボディ外形やアセンブリの一部が、書き加えられた矩形によって隠されていることがわかります。
ノイズ付与という観点では、入力の直後にDropoutを入れることも検討しましたが、今回は前記のように「局所的な特徴を隠すこと」が狙いなので、全体にまんべんなくノイズが加わるDropoutは不適と判断しました。
学習結果
入力にノイズを加えた状態でモデルを学習してみます。
前回同様、ImageNet学習済のResNet-50を使用した転移学習です。
精度の推移はこんな感じになりました。
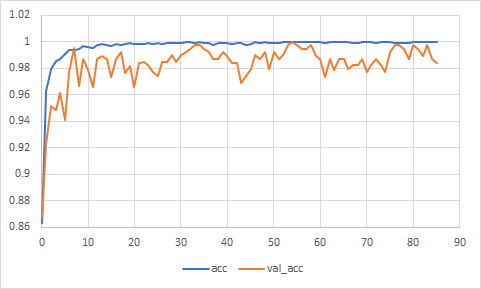
意外にも、ノイズ付与による学習スピードへの影響はほとんど見られません。
ベストスコアは54ステップ目で、学習精度99.95%、検証精度100%です。
この時点のスナップショットを使って、再び推論を実行してみます。
あれこれ推論させてみる
落書きなしのJazzmaster、Les Paul、アコギは、前回同様の良好な結果だったので省略します。
注目は、前回なぜか「フライングV」と判定されてしまった、落書き入りのJazzmasterの写真。今回はどうでしょうか。

うまく改善されました。
一方で、スコアに変化があったのがこちら、Duo Sonic。
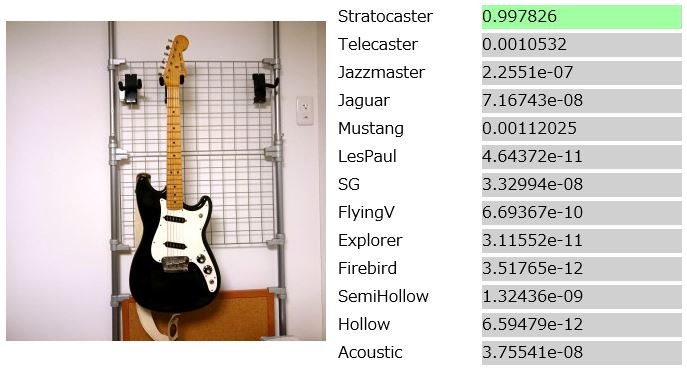
前回は「ムスタング」との判断でしたが、今回は「ストラトキャスター」です。
より大域的な特徴を捉えるようになった結果、ピックガードやブリッジの形状が考慮されるようになったのかも知れません。
感想
なんとなく狙いは達成できたような気がします。(適当)
今回試しているようなことは、アカデミックな分野では半ば常識的なテクニックなのだとは思いますが、身近な題材に適用してみると、理解が深まって面白いですね。