この記事はAWS Advent Calendar 2014の最終日の記事です。メリークリスマス!!
WLMお使いですか?
WLM?
まずは、RedshiftのWLM(Work Load Management)について簡単に説明すると、Redshiftに投げ込まれるクエリに対して割り当てるRedshiftのリソースを指定するものです。事前にWLMとしてキューを用意しておき、キューに対して割り当てるメモリの割合や並列度、タイムアウトの時間を指定することでクエリに対してリソースの配分や長時間実行されるクエリを止めてクラスタリソースを無駄遣いしないようにすることが目的です。
キューに指定出来るものとしては
- 並列度
- メモリの割合
- タイムアウト
です。
キューに割り当てられたメモリは、キュー内で実行されているクエリで均等に分割して使用されます。
CPUやDisk IOまで指定出来ると嬉しいのですが現状では出来ないため将来の機能改善に期待です。
WLMの必要性
DWHでは往々にして、実行時間のかかるクエリからサクッと終わるもの、バッチがガリガリと長時間かけて実行するクエリまで様々なタイプのクエリが投げ込まれます。
クエリの用途によって、リソースをガッツリ割り当ててすぐに結果を返して欲しいものから、気長に実行をまてるものまで要件は様々です。WLMではクエリに対してクラスタリソースを管理することで1つのクラスタ内で様々な種類・用途のクエリを扱いやすくすることが出来ます。
Redshiftでは標準で1キュー・5並列とParameter Groupで設定されていて、この状態では実行時間が長くかかるクエリが5本実行されている状態で、数秒で終わるようなクエリが続いて実行された場合、早く終るはずのクエリは先行している5本のクエリのうち1本が終わるまで実行されないため、結果として数秒で終わるはずが数時間たたないと結果が返らないことになってしまいます。
WLMあれこれ
ドキュメントはImplementing Workload Management - Amazon Redshiftこちらです。
WLMはグループのまとめ方で分けると
- ユーザグループ: 接続アカウントに対して
- クエリグループ: 実行するSQLに対して
と2種類存在します。
利用例としては、ユーザグループは、特定のアプリケーション・BIツールなどアカウントで一括してキューを割り当ててしまう場合に使用し、クエリのグループはVACUUMやアドホックなクエリを実行する際にクエリ単位で指定すると便利かと思います。
このグループ毎にクエリが実行される際の並列度を制御することが可能です。最大で8つのキューを定義することが可能で、全てのキューの並列度の合計は50までとなっています。この8つのキューの1つはデフォルトキューに設定しないといけないため、グループを割り当てることが出来るのは7つとなります。
また、暗黙的に並列度1のSuperuserキュー(クエリグループ)というものが存在しますが、こちらはデバッグ用など管理用に使うために割り当てないことが推薦されます。
しかし、ドキュメントにも書かれていますが並列度は15以下にすることが指定されています。理由としてメモリの割当は同時並行処理されているクエリの数には関係ない(クエリが使えるメモリ量はクエリが実行しているクエリスロットに割り当てられたメモリの量)ため、同時実行数が仮に3の場合にメモリ内で実行可能だったクエリが、同時実行数を10に増加した場合にディスクに中間テーブルを作成する必要が出る可能性があり、ディスクI/Oが、パフォーマンスを低下させる可能性があるためです。
設定してみる
Redshiftでは、Management ConsoleのRedshift Parammeter Groupで設定を行います。設定項目名はwlm_json_configurationです。こちらにjson形式で設定します。設定自体は、隣のWLMタブで行います。
設定方針
まずはどのようにクエリのグループを分割するかを指定します。
例えば
- 最優先
- アプリケーションから発行されるクエリ
- 並列度高め
- 優先度低
- バッチなどから発行されある程度時間がかかっていいもの
- 最低
- 開発用
の様な形で大枠でもいいので決めて、クエリやツール・用途がある程度固定されている場合はそれぞれどれにクエリが当てはまるか決めます。
既に起動しているクラスタにParameter Groupの変更を適用するとクラスタのrebootが必要になるので、運用中の場合は注意が必要です。
設定画面
例えば、このような形でdefaultキューを含めて6個のWLMキューを作成してみます。
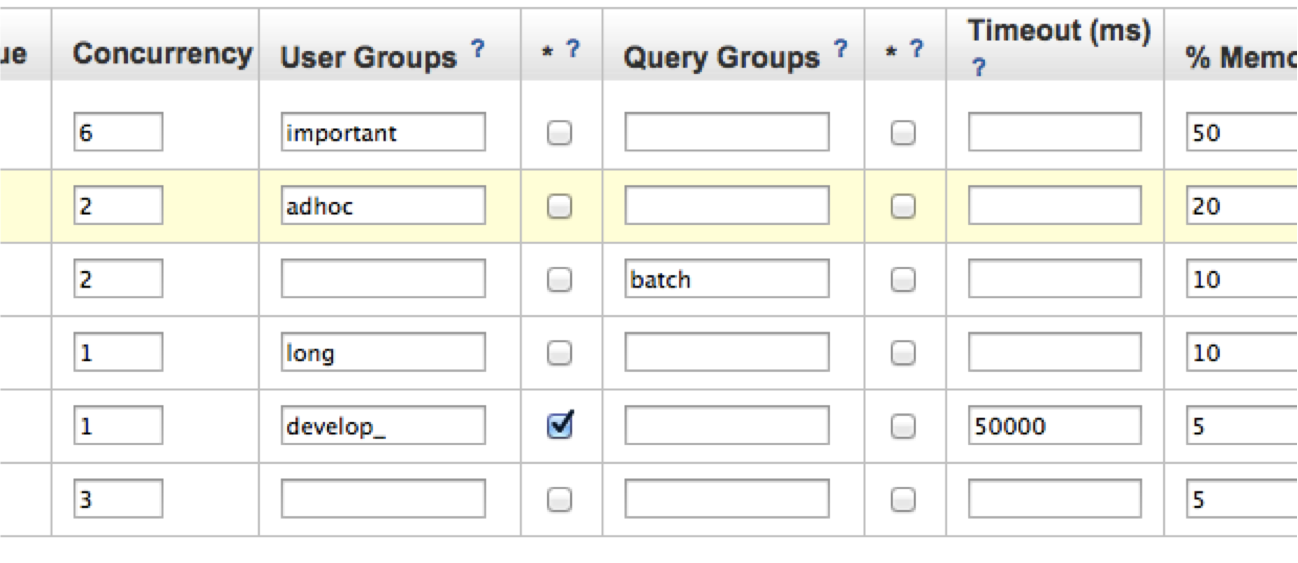
*?という項目でwildcardをONにすると、この例ではdeveloper_をprefixにしたユーザグループは全てこのキューに入ります。例えば、「developer_hoge」「developer_fuga」などユーザ名やシステム名が後に続く様な命名規則の場合などに便利かと思います。
全体を見ると、こんな感じで指定できます。メモリやタイムアウトも設定しています。defaultが最後に来るようにして、Up,DownでWLM適用の優先度を指定します。
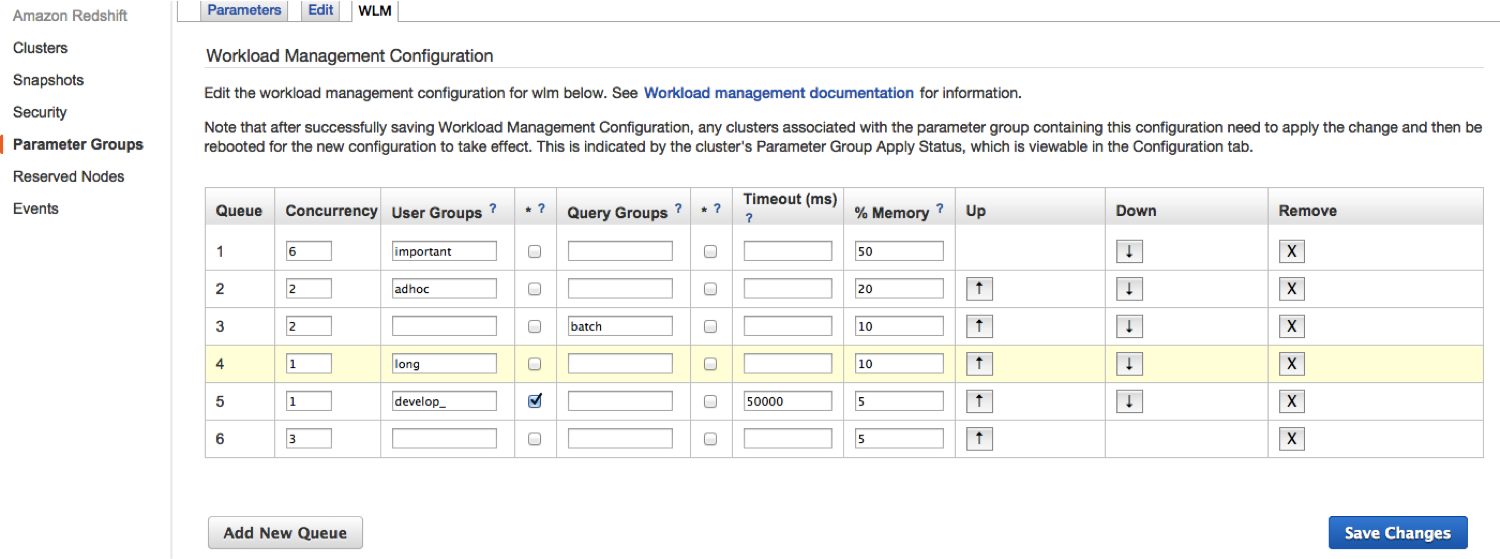
Timeoutについては、Parameter Groupでクラスタ自体にも設定することも可能です。WLMとクラスタ両方にTimeoutを指定した場合はTimeoutが短い方が優先されます。
WLMの適用
キューの適用方法
以下のクエリでユーザをグループに追加することが可能です。
- グループ作成と同時にユーザ追加 (with以下はオプション)
- ユーザ作成時にグループに指定 (既に存在するグループに対して)
- 既存のグループにユーザ追加
ユーザグループ
1# create group fast with user user1, user2;
2# create user user3 in fast,middle password 'hoge';
3# alter group fast add user user3, user4, user5;
クエリグループ
こちらは、クエリを発行するタイミングで、set query_groupとreset query_groupで囲まれている間、指定したクエリグループが使用されます。もし、存在しないクエリグループを指定した場合は影響を及ぼしません。
set query_group to 'batch';
select count(*) from big_table;
select user_name, city, age from hoge_table order by age desc limit 100;
reset query_group;
キューの適用規則
先ほどWLMの設定画面で設定したキューの優先度ですが、適用規則が存在します。
ドキュメントのフローチャートは以下のようになっています。
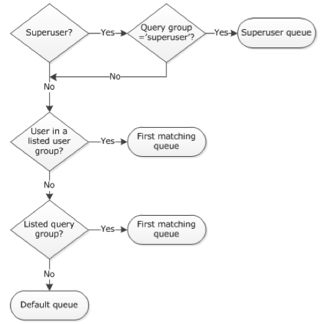
- Superuserでログインしていて、クエリグループでSuperuserを指定している場合はSuperuserキューで実行
- ログインユーザがユーザグループに含まれている場合は、一番最初にマッチするユーザグループで指定されているキューで実行
- ユーザグループに存在しておらず、クエリグループが指定されている場合は、最初にマッチしたクエリグループのキューで実行
- どれにも当てはまらない場合はデフォルトキューで実行
この様な順序で適用が行われていきます。ユーザグループがクエリグループよりも優先されます。
例えば、user1 が fastユーザグループに入っていて、クエリパラメータとして batchを指定した場合はfastユーザグループで指定されているキューで実行されます。
どのキューでクエリが実行されているかなどの情報をwlm system tableから取得することが可能です。詳細はMonitoring Workload Management - Amazon Redshiftのドキュメントに書かれています。service_classがWLM設定画面で指定した際のQueue番号です。
キューの適用順序の詳細は WLM Queue Assignment Rules - Amazon Redshiftに詳しく記載されています。
SuperユーザキューはSuperユーザに指定されているユーザでこちらのキューを指定することで、メンテナンス作業や、万が一キューが満杯で作業が出来ない場合などに便利です。
set query_group to 'superuser';
analyze;
vacuum;
reset query_group;
その他
WLMではキュー毎にmemory slotと呼ばれるslotが割り当てられています。このslot数は各キューのConcurrencyと同数です。一時的にキュー内のslotを多く使用してメモリリソースを多く使用するクエリを実行する場合は
set wlm_query_slot_count to 8;
vacuum;
set wlm_query_slot_count to 1;
このようにwlm_query_slot_countで使用するslotを変更することでリソースを専有することが出来ます。しかし、この指定できるslot数はキューに割り当てられたslot(Concurrency)を超えることが出来ません。もし指定するとエラーが返されます。また、例えばキューのConcurrencyが10だとしてwlm_query_slot_countで8を割り当ててしまうと、残り2slotしか、そのキューには空いていないため同時に3クエリのみしか実行することができなくなります。
まとめ
キューの並列度の設定については、運用しながらクラスタリソースの使用状況を見ながら変えていくのが最初はいいですが、変更にはクラスタのrebootが必要なため、運用前にある程度想定クエリで様子をみて調整しておくと後で困らないと思います。
また、RedshiftのWLMは現在のところ簡易的なものなのと、とにかく、まずはクエリやテーブル設計をしっかりとすることがリソースを効率的に使う前提だと思うので、そちらも是非考えてみてはいかがでしょうか。
それでは、良いお年を〜。
こちらは個人の意見で会社とは関係ありません。お約束です。