Luigiとは
LuigiはPythonで書かれたデータフロー制御フレームワークです。
ストリーミング音楽配信大手のSpotifyが開発しています。ソニーと提携したことでも話題になりましたね。
- Luigi公式レポジトリ
- 本家のプレゼン資料がわかりやすいです。
一般的にビッグデータ解析では、統計・機械学習を行う前に、クレンジングやフィルタ処理をいくつも重ねる必要があります。その依存関係は複雑で、しかもデータの差し替えや失敗・中断時のやり直しなんてやりだすと、苦行の他のなにものでもありません。そんな時にLuigiは使えます。
名前のLuigiの由来は、データフローを配水管に例え、「世界で2番目に有名な緑色の服を身にまとった配管工」だとか…。赤じゃなくて緑なのは、Spotifyのコーポレートカラーと同じだからでしょうか(笑)。
Pythonではありますが、Pythonによる処理だけでなく、HadoopやTreasure Dataと組み合わせることも容易です。データ解析を行う上で欲しくなる機能がひと通り揃っていて超強力なツールです。なのに、日本での認知度はまだあまり高くないようです。
そこで、布教のためにも紹介したいと思います。
主な特徴
- オブジェクト指向でデータ処理のタスクを書ける
- 下流から上流へタスク同士の依存関係を解決する
- エラーが起こったらそこで止まってくれる
- 失敗したところからの再開が容易である
- 出力オブジェクトの有無でタスクの終了判定をすることによって冪等性を担保する
- 同じデータを参照するタスクが実行されたときにキャッシュ的な働きをしてくれる
- データ処理内のパラメタの外部化が容易である
- データベースエンジン、Hadoop(HDFS, MapReduce Streaming, Hive, Sparkも!)との連携もバッチリ
- データフローの依存関係・進捗をWebブラウザで可視化できる
- コマンドラインインターフェースを持つ(かなり充実)
- このままgitに放り込めばバージョン管理もしっかりできる
- Pythonのクラスそのものなのでテストを書きやすい
とにかく、いいことばかりです。
惜しいところは、ブラウザから処理を発動できないことくらいでしょうか。あと、Hadoop周りのマニュアルが未整備で、仕様理解のためにソースを読まなければなりません。
導入方法
sudo pip install luigi
これだけで入ります。
書き方
処理の最小単位は Task
Luigiの処理を最小単位はTaskと呼んで管理します。1Taskに対してluigi.Task()クラスを継承するクラスを記述します。
Task間依存の記述方法
Luigiでは、データフローのチェーンを下流から上流へとリンクを張ることで記述します。
luigi.Task()クラスには、お作法として下記のメソッドを持ちます。
-
requires(): 依存する上流のTask -
output(): 出力オブジェクト (ファイル名をluigi.Target()系クラスでラップしたもの) -
run(): Task内の処理
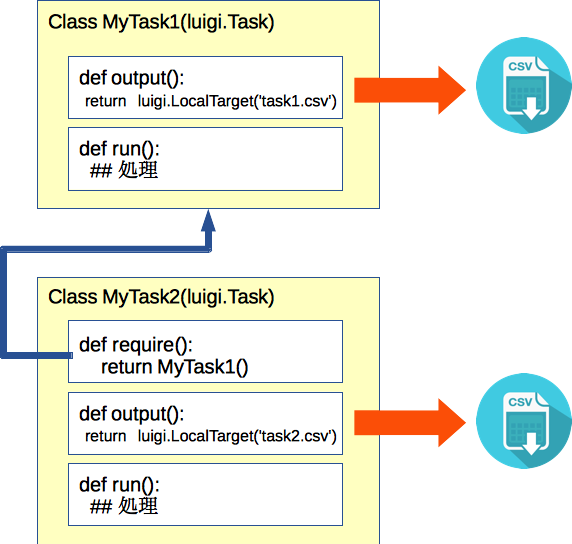
こうすることで、依存をガチガチに書く必要がなくなります。また、ファイルを依存する側と依存される側で2度書く必要がありません。
実行する際には、最も下流のTaskを呼び出します。こうすることで、Luigiが勝手に上流まで依存を自動的に解決し、順に実行します。このとき、--workersオプションを複数にしておけば、並列可能な箇所を自動的に並列実行してくれます。
実例
ここからは、
Luigiの公式サンプル、top_artists.pyを例に書き方を見てみましょう。
これはアーティストの再生回数の日次集計を模したスクリプトです。
楽曲の再生ログを日次で集計し、Top10となるアーティストを抽出しています。
top_artists.pyでは Top10Artists()[ソートして先頭10件を出力] -> AggrigateArtists()[アーティストごとに再生回数集計]
-> Streams()[日次ログ] のようにデータフローを記述しています。
class Top10Artists(luigi.Task):
"""
This task runs over the target data returned by :py:meth:`~/.AggregateArtists.output` or
:py:meth:`~/.AggregateArtistsHadoop.output` in case :py:attr:`~/.Top10Artists.use_hadoop` is set and
writes the result into its :py:meth:`~.Top10Artists.output` target (a file in local filesystem).
"""
date_interval = luigi.DateIntervalParameter()
use_hadoop = luigi.BoolParameter()
def requires(self):
"""
This task's dependencies:
* :py:class:`~.AggregateArtists` or
* :py:class:`~.AggregateArtistsHadoop` if :py:attr:`~/.Top10Artists.use_hadoop` is set.
:return: object (:py:class:`luigi.task.Task`)
"""
if self.use_hadoop:
return AggregateArtistsHadoop(self.date_interval)
else:
return AggregateArtists(self.date_interval)
def output(self):
"""
Returns the target output for this task.
In this case, a successful execution of this task will create a file on the local filesystem.
:return: the target output for this task.
:rtype: object (:py:class:`luigi.target.Target`)
"""
return luigi.LocalTarget("data/top_artists_%s.tsv" % self.date_interval)
def run(self):
top_10 = nlargest(10, self._input_iterator())
with self.output().open('w') as out_file:
for streams, artist in top_10:
out_line = '\t'.join([
str(self.date_interval.date_a),
str(self.date_interval.date_b),
artist,
str(streams)
])
out_file.write((out_line + '\n'))
def _input_iterator(self):
with self.input().open('r') as in_file:
for line in in_file:
artist, streams = line.strip().split()
yield int(streams), artist
各メソッド内部は普通のPythonで記述できます。そのため外部から与えられたパラメタに応じて依存を切り替えたり、リストや辞書等によって複数のTaskへの依存を記述できます。
top_artitsts.pyの例では、AggrigateArtists()のTaskが日次ログを返すStreams()のTaskをリストで複数参照することによって、日次データを1ヶ月分集計しています。
実行するには下記のようにコマンドを入力します。
python top_artists.py Top10Artists --date-interval 2015-03 --local-scheduler
Luigi Scheduler
luigidコマンドでスケジューラが立ち上がります。複数のクライアントから大量のTaskを受け取った場合にも順に実行してくれます。
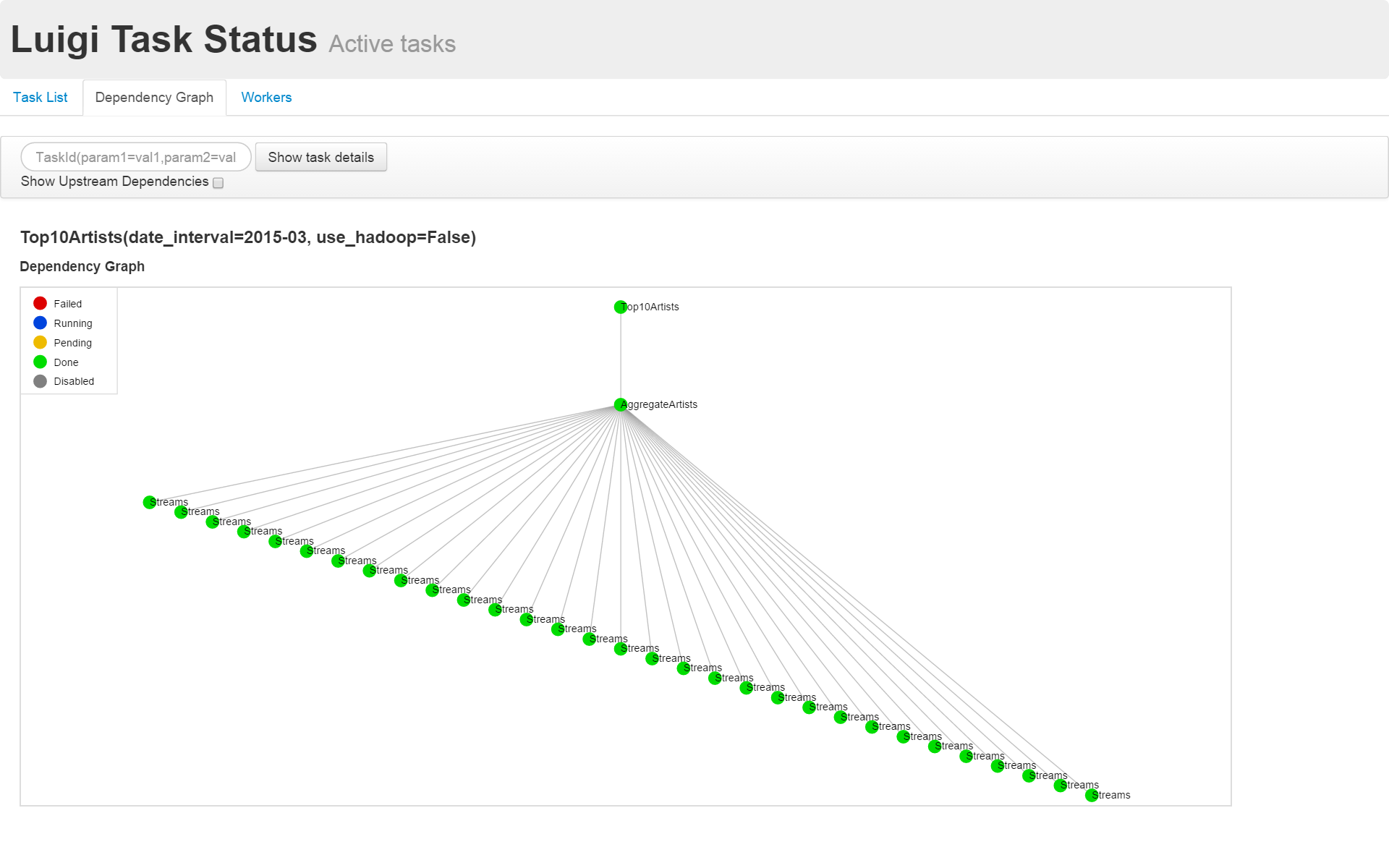
また、ブラウザからlocalhost:8082にアクセスすれば処理の進捗や依存関係を可視化してくれます。
スケジューラにTaskを投げるには--local-schedulerオプションを外して実行します。
python top_artists.py Top10Artists --date-interval 2015-03
依存関係を可視化した例を下記に示します。
活用例
拙作の常用漢字分析スクリプトにLuigiを使ってみました。Rubyで記述したフィルタコマンドをUNIXパイプラインでつなぐところを、あえてLuigiでつないでいます。若干過剰な実装ですが、中間ファイルが確実に残るので動作確認がしやすくなりました。また、ファイル名を依存する側とされる側で2回書かなくて良いのですっきりしました。
…すいません、上記はどれもビッグデータじゃありませんでした。