住所から緯度経度を割り出すことを「ジオコーディング」って言うんですね、という程度の地図系初心者ですが、表題のものを思いつきで作ってみました。名前は「tokoro」としました。適当ですみません。フロントエンドとNode/io.js上のどちらでも動くライブラリです。
使い方
まずは、tokoroをインストール。
$ npm install --save tokoro
※ npmを使わず、スクリプトとデータを直接ダウンロードすることもできます。
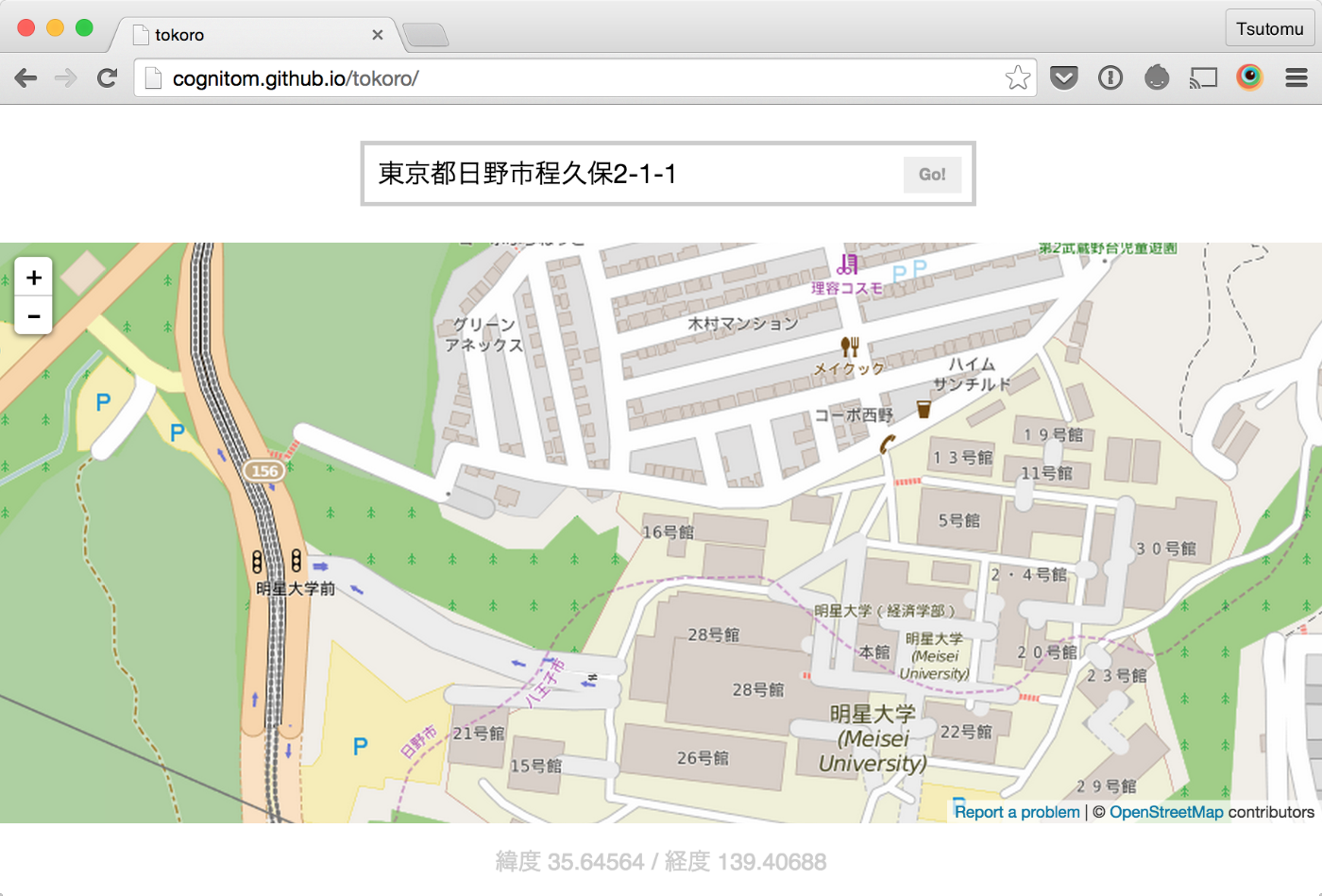
Nodeでの利用は、こんな感じ。OSCでよくお世話になる、明星大学のキャンパスの緯度経度を出してみます。
var tokoro = require('tokoro')
tokoro('東京都日野市程久保2-1-1', function(code) {
if (code) {
console.log('緯度', code[0]) // 35.64564
console.log('経度', code[1]) // 139.40688
} else {
console.log('見つからないよ!')
}
})
同じように、フロントエンドのJavaScriptからも使えます。Nodeの場合と違い、データの格納場所を変更できます。デフォルトは node_modules/tokoro/dataですが、任意の場所に置いて構いません。なお、tokoro()にオブジェクトを渡すとオプション設定になります。
<script src="dist/tokoro.js"></script>
<script>
tokoro({ data: 'data' }) // データの格納ディリクトリを指定
tokoro('東京都日野市程久保2-1-1', function(code) {
if (code) {
console.log('緯度', code[0]) // 35.64564
console.log('経度', code[1]) // 139.40688
} else {
console.log('見つからないよ!')
}
})
</script>
そのほか、使い方についてはREADMEにも書いてあるのでそちらをどうぞ。
何が嬉しいの?
「Google MapsのAPIでいいじゃん?」と言われそうですが、クエリー数のリミットがあったり、非公開のサービスで使うには、有償版の必要があったりと、気軽に使えるシーンは案外限られてきます。(業務系だと特に)
一方で、OpenStreetMapも徐々に充実してきて、いろいろな場面で使えそうです。国土交通省が公開している街区レベル位置参照データもあるので、これをデーベースに突っ込めば良さそうですね。
...なんですが、全国のデータをダウンロードすると1.4GB近くあり、ちょっと「気軽」じゃない感じになってきます。データベース必須だと、フロントエンドのプロジェクトだと一気にハードルが上がるし、npm installだけで使えないなんてめんどくさ過ぎます。
というわけで、郵便検索ライブラリくらいの気軽さで導入できるようにしたのが「tokoro」です。
ハッシュハッシュハッシュ
元データが1.4GBあるんですが、ここから不要なデータを除いて、ハッシュにしたりで、最終的には200MBを切るところまで小さくしました。まあ、このくらいならギリギリ許容できる...はず。
クライアントサイドからも使えると書きましたが、200MBを利用者にダウンロードさせるわけにはいかないので、2000ファイルに分割しています。
東京都日野市程久保二丁目1 35.64564 139.40688
みたいなデータが約1千万件あるのですが、このままだとかなり重たいです。住所部分を数値ハッシュ化してしまいましょう。
2843349453 35.64564 139.40688
さらにASCII文字をフルで使って94進数で置き換えます。
EH>MJ %<Gu 1jd3
だいぶ短くなりました。これなら5000件でもだいたい100KBに収まります。cf. 処理の詳細はこちら
追記・v0.2.0からは、32ビット整数としてバイナリ保存する形式に変更しました。結果、全体で200MB→137MBにダイエット成功。
住所ってめんどくさい...
元々のデータは、都道府県、市区町村で分かれていますが、地域によって名前付けルールはまちまちです。本来であれば、同一地域ごとにデータをまとめてキャッシュ性能を上げたいところですが、そのためには住所データベースを別途持つ必要が出てきそうです。しかし、それでは容量が1GBくらい必要になってしまいます...
そこで、単純に数値ハッシュの下3桁(正確には3.2桁)を使って、ファイルを分割する方法をとりました。実際、90KB〜104KBと、比較的分布も均等です。そのためハッシュの衝突も最小限に抑えられています。(現在のところまだ完璧ではないですが...)
追記・v0.2.0では、各ファイル63〜74KB程度に改善しています。
1検索ごとに、100KBダウンロード..?
この100KBのファイルをどうするかというと、
- フロントエンドからダウンロードして
- JavaScriptで検索
します。もう富豪プログラミングです。動的なサーバを用意するより、この方がコストが安いんだからいいんです。(開き直り)
10年前なら本気で悲鳴が聞こえそうですが、2015年の今ならありなんじゃないかな...と。実際やってみたら、かなり速いです。ダウンロード + フロントエンドでの検索でも「ほぼ一瞬」です。
まとめ
業務システムほか、地図がちょっと使いたいシーンで、ライセンス料が見合わず諦めていたケースは多いと思います。tokoroとOpenStreetMapを組み合わせると、コストかけずに実現できることが結構ありそう。いろいろ遊んでみてください。
表記揺れ、正規化、ハッシュ関数など、改善の余地ありなので、ツッコミ歓迎です。気軽にIssueやPRを上げてもらえたら嬉しいです。扱うデータが国内限定なので、日本語でどぞ。