はじめに
サポートベクターマシンを使ってみたくなったので、手始めにFizzBuzzを書いてみることにした。
サポートベクタマシンとは
サポートベクターマシン(英: support vector machine、SVM)は、教師あり学習を用いるパターン認識モデルの一つである。識別や回帰分析へ適用できる。
サポートベクターマシンは、現在知られている手法の中でも認識性能が優れた学習モデルの一つである。サポートベクターマシンが優れた認識性能を発揮することができる理由は、未学習データに対して高い識別性能を得るための工夫があるためである。
俺の理解としては、サポートベクターマシンは「(基本的に2値?の)答え付学習用データ(基本的には複数次元パラメータ)をかませると、未学習のデータについても識別が可能になるパターン認識モデル」というところ。
サポートベクタマシンをpythonで使うには(一例)
-
LIBSVMをインストールする。
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
なお、READMEのwindowsの項目はメンテナンスされていない模様なので注意。基本的にダウンロードフォルダ配下のpythonサブフォルダにパスを通せば動く模様である。 -
プログラムの中でsvmのラッパーを使う。
具体的なモジュールの使い方については下記サイトを参考にさせていただきました。
http://tkoyama1988.hatenablog.com/entry/2013/12/09/125143
いったい何を学習用データとすればよく、何を未学習データとすればよいか?
サポートベクターマシンの大雑把な動き
- 学習データを基に学習しモデルを作成する。
- モデルを基に未学習データの判定を行う。
本来のインプット1~100までを未学習データとしたい。
↓
200以上の数を学習用データにすればよさそう。
データのパラメタライズ
単純に200以上の数を学習用データ、1~100までを未学習データとすると、共通点がないからうまく動かなそう
↓
それぞれの数を1~150までで割った時の余り(150次元)を夫々の数のパラメータとすればなんとなく動きそう?
ということで以下のような関数を作ってみた。
def parameterize(n):
RANGE = range(1,150)
return [n]+[n%i for i in RANGE]
期待値
俺は基本的に2値の判定しか知らない。
↓
FizzBuzzの出力は4種類(数自体、Fizz, Buzz, FizzBuzz)
↓
3回分のフィルターを作ろう。
イメージ
数 or 文字?→数
↓
Fizz or Buzz?→ Fizz
↓
FizzBuzz or Buzz?→Buzz
↓
FizzBuzz
ということで以下の関数を作ってみた。入力値nを期待値に変換する関数で、一方の期待値が1で他方の期待値が-1。
def string_or_number(n):
if (n % 3) == 0 or (n % 5) == 0:
return 1
else:
return -1
def fizz_or_buzz(n):
if (n % 5) == 0:
return 1
else:
return -1
def buzz_or_fizzbuzz(n):
if (n % 15) == 0:
return 1
else:
return -1
入力値nをパラメタ化し、期待値を求める関数も作った。
def create_train_data_and_label(n):
data = parameterize(n)
label1 = string_or_number(n)
label2 = fizz_or_buzz(n)
label3 = buzz_or_fizzbuzz(n)
return data, label1, label2, label3
こちらは出力値p1,p2,p3 を数字、Fizz, Buzz, FizzBuzzのいずれかに変換する関数。
def output(n, p1, p2, p3):
if p1 < 0:
return n, n
else:
pass
if p2 < 0:
return n, 'Fizz'
else:
pass
if p3 < 0:
return n, 'Buzz'
else:
return n, 'FizzBuzz'
svmのところはひとまとめとして、学習用データのパラメータと、期待値から学習を行い、モデルを返す関数を作った。
def study(data, label):
prob = svm_problem(label, data)
param = svm_parameter('-s 0 -t 0')
m = svm_train(prob, param)
return m
そしてmain()を以下のように作った。
def main():
START = 1
FINISH = 101
TEST_START = 101
TEST_FINISH = 3001
#学習用データの作成
data, label1, label2, label3 = create_trainers(TEST_START,TEST_FINISH)
#学習
m1 = study(data,label1)
m2 = study(data,label2)
m3 = study(data,label3)
#未学習データの作成
params, expected_label1, expected_label2, expected_label3 = create_trainers(START,FINISH)
#未学習データから出力の取得
p1_labels, p1_acc, p1_vals = svm_predict(expected_label1, params, m1)
p2_labels, p2_acc, p2_vals = svm_predict(expected_label2, params, m2)
p3_labels, p3_acc, p3_vals = svm_predict(expected_label3, params, m3)
#結果の表示
for n in range(START,FINISH): print output(n, p1_vals[n-1][0], p2_vals[n-1][0], p3_vals[n-1][0]),
main()
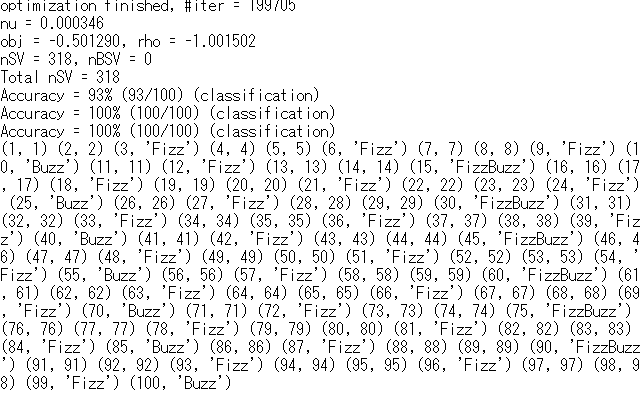
結果
(入力値、(変換済み)出力値)
学習データを200~3000としたところ、一部の5や20等でうまく動いていないところはあるけれども、おおむねうまく動いている。
なお、学習データを200~300のように少なくしたりしたところ、全然動かなかった。
作成したコードの全体像
# coding: utf-8
import sys
sys.path.append('./libsvm-3.20/python')
from svm import *
from svmutil import *
def parameterize(n):
RANGE = range(1,150)
return [n]+[n%i for i in RANGE]
def create_train_data_and_label(n):
data = parameterize(n)
label1 = string_or_number(n)
label2 = fizz_or_buzz(n)
label3 = buzz_or_fizzbuzz(n)
return data, label1, label2, label3
def create_trainers(start,finish):
data_list, label1_list, label2_list, label3_list = [], [], [], []
for n in range(start,finish):
data, label1, label2, label3 = create_train_data_and_label(n)
data_list.append(data)
label1_list.append(label1)
label2_list.append(label2)
label3_list.append(label3)
return data_list, label1_list, label2_list, label3_list
def string_or_number(n):
if (n % 3) == 0 or (n % 5) == 0:
return 1
else:
return -1
def fizz_or_buzz(n):
if (n % 5) == 0:
return 1
else:
return -1
def buzz_or_fizzbuzz(n):
if (n % 15) == 0:
return 1
else:
return -1
def study(data, label):
prob = svm_problem(label, data)
param = svm_parameter('-s 0 -t 0')
m = svm_train(prob, param)
return m
def output(n, p1, p2, p3):
if p1 < 0:
return n, n
else:
pass
if p2 < 0:
return n, 'Fizz'
else:
pass
if p3 < 0:
return n, 'Buzz'
else:
return n, 'FizzBuzz'
def main():
START = 1
FINISH = 101
TEST_START = 101
TEST_FINISH = 3001
#学習用データの作成
data, label1, label2, label3 = create_trainers(TEST_START,TEST_FINISH)
#学習
m1 = study(data,label1)
m2 = study(data,label2)
m3 = study(data,label3)
#未学習データの作成
params, expected_label1, expected_label2, expected_label3 = create_trainers(START,FINISH)
#出力の取得
p1_labels, p1_acc, p1_vals = svm_predict(expected_label1, params, m1)
p2_labels, p2_acc, p2_vals = svm_predict(expected_label2, params, m2)
p3_labels, p3_acc, p3_vals = svm_predict(expected_label3, params, m3)
#結果の表示
for n in range(START,FINISH): print output(n, p1_vals[n-1][0], p2_vals[n-1][0], p3_vals[n-1][0]),
main()
参考サイト
Libsvm配布元
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
libsvmのpythonでの使い方を教えてくれたサイト
http://tkoyama1988.hatenablog.com/entry/2013/12/09/125143