はじめに
下記サイトには次のことが記載されている。
setsや辞書を使った要素の検証(O(1))は、配列の検索(O(n))よりも高速です。 a in b を調べるとき、bはリストやタプルではなくsetsや辞書であるべきです。
http://www.peignot.net/python-speed
本当なのかしらん?と思ったのと、本当だとしてどれくらい違うんじゃい?と気になったので実際に試してみた。
実行環境
python2.7
windows7
Intel Core i5 CPU 2.4GHz
メモリ 4.0 GB
実行条件
リスト、辞書、セット型で、1の倍数ごと、2の倍数ごと、3の倍数ごとの整数列(要素数100万個)を作り、1から1万までのinでの参照を行った。1の倍数ごと、2の倍数ごと、3の倍数ごとの整数列を作ったのはヒット率の処理速度への影響を調べるためである。
なお、各テスト回数は合計10回ずつである。
詳細は下記コード参照。
結果
死ぬほどリストの参照が遅い反面、辞書、セット型については超高速であった。リストにおいては、ヒット率が高い場合よりも、ヒット率が低い場合には処理速度が明らかに落ちることが見受けられた。なお、単位は秒であり、10回実行した時の合計時間である。
他方、辞書型、セット型に関してはそこまでの処理速度の低下は見受けられなかった。(3/5 8:08 範囲が誤っていたため図を修正)
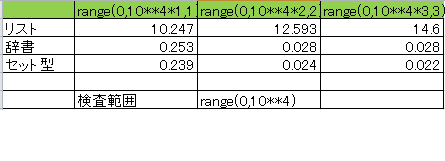
結論
要素数が多いリストで
要素 in リスト
的な文を書くのはできる限り避けるべきである。本当に死ぬほど遅い。
実験コードたち
def lists(q,h):
ls = [i for i in range(0,q*h,h)]
for i in range(q): i in ls
def dicts(q,h):
dc = {i:i for i in range(0,q*h,h)}
for i in range(q): i in dc
def setts(q,h):
st = set(i for i in range(0,q*h,h))
for i in range(q): i in st
def exe(func,num=100):
from timeit import timeit
setup = 'from __main__ import ' + func[:5]
print "%s: %s" % (func, timeit(func, setup, number=num))
if __name__=='__main__':
q = 10**4
funcs = ['lists','dicts','setts']
hits = [1,2,3]
for h in hits:
for f in funcs:
func = '%s(%s, %s)' % (f,q,h)
print func
exe(func,10)