Pythonによるデータ分析入門を読む中でひっかかったところのメモです。IPythonよりPycharmでの実行を好んで実施しています。読みながら追記していっています。プログラミング自体初心者で、いろんなところでひっかかりますので、後から同様に学ぶ人の参考と自分が忘れたときの参考になれば、と思って書いています。
環境
・Windows10(64bits)
・Python3.5(Anaconda)
・pandas0.18.1
・Pythonによるデータ分析 初版第2刷
参考
・英語版の正誤表※オライリー・ジャパンが翻訳して公開してくれればいいのですが、オライリー・ジャパンだから絶対やってくれないでしょうね。
・2016/06/11気付きましたが、https://github.com/wesm/pydata-book
利用するのが一番良いのでは?
第2章
P.22, 23 usa.govデータの出現上位タイムゾーン
IPythonで実行する場合も、統合開発環境などで実行する場合も、
import matplotlib.pyplot as plt
import pandas as pd
を実施。pltやpdは個人の自由ですが、慣習があって、それがplt, pdです。numpyは、npです。
統合開発環境でグラフを表示するときには、
var=tz_counts[:10].plot(kind="barh", rot=0)
plt.show(var)
と記述したところうまくいった。
別に、
tz_counts[:10].plot(kind="barh", rot=0)
plt.show()
でもよいみたい。複数のデータで、plotしてから、plt.show()すると、同時に複数のグラフが表示される。
複数グラフを並べて表示するときには、subplotsを利用する。本だと、P.45に登場する。matplotlibについては、ここが詳しい。
P.37 pivot_table
pivot_tableで、rowsとcolsが出てくるが、2016/05/28現在、エラー(TypeError: pivot_table() got an unexpected keyword argument 'rows')になる。
ここによれば、
・rowsを、indexに、
・colsを、columnsに、
変更することで回避できるとのこと。自分の環境でも実際それで解決。P.37以降もpivot_tableが出てくるところでは、同様の編集が必要になります(P.44やP.49)。
※ここの最後のほうの回答に、書かれているように昨年あたりに、indexとcolumnsを使用するように変更された様子。
p.39 get_top1000の記述
group.sort_indexを、group.sort_valuesにしろ、と2016/06/04現在Warningが出ますね。おとなしく、valuesに変更しました。
P.40 名前グラフ描画
IPythonではなく、Pycharmを利用しているが、本のとおりに、subsetを作って、プロットするところで、本に従って、
subset = total_births[['John', 'Harry', 'Mary', 'Marilyn']]
var = subset.plot(subplots=True, figsize=(12, 10), grid=False, title = "Number of births per year")
plt.show(var)
としたところ、ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()と表示される。なぜこういう表示になるか、しっかり理由はあるはずだが現状、理解できていない。
とりあえず、plt.show(var)をplt.show(var.all())に変更することで、本と同じに見えるグラフを描画できた。
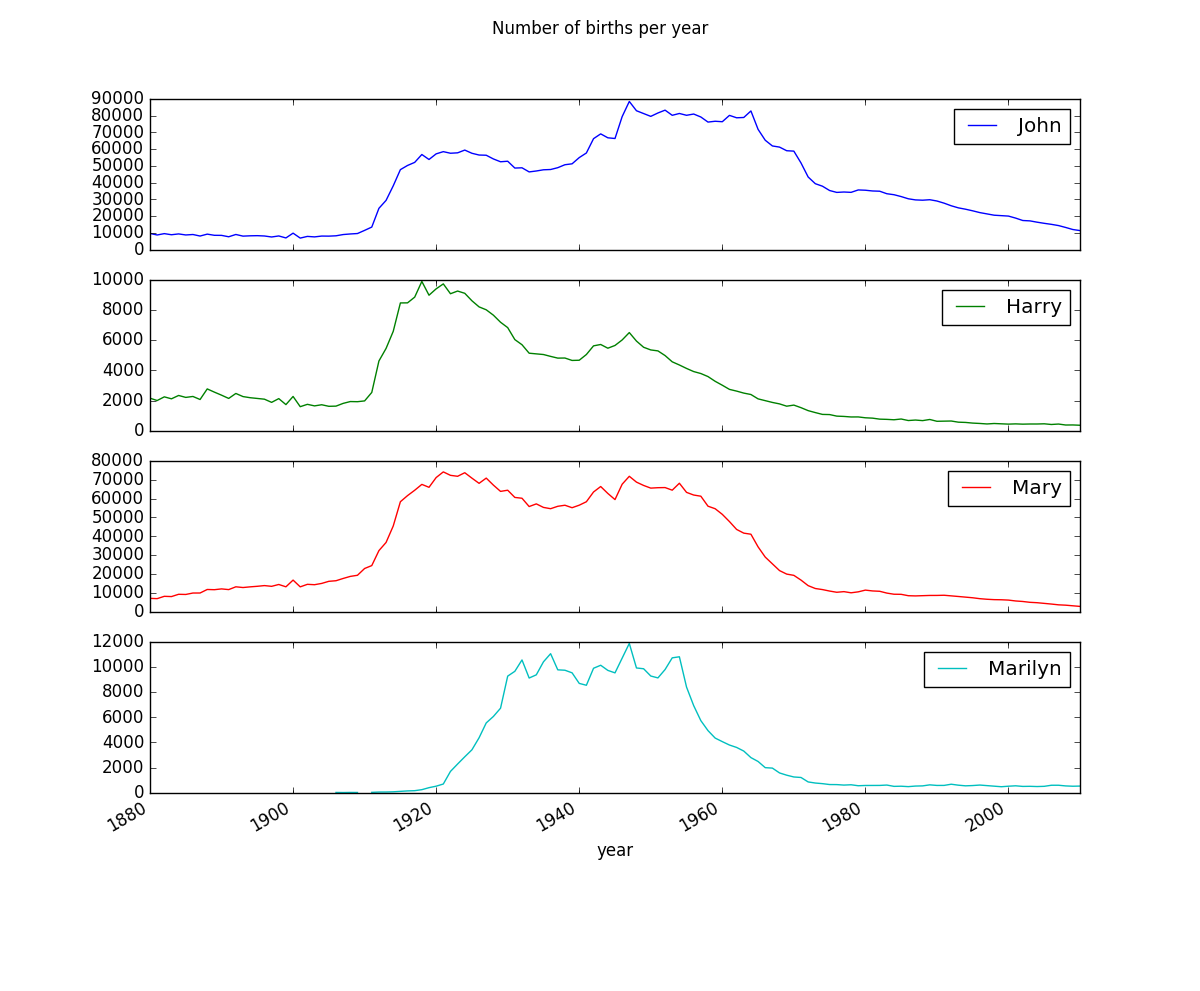
このグラフを表示するところを2016/06/03にパッケージを個別にアップデートし、再実行したらエラーになった。そこで、conda update --all実行時にダウングレードされるがまま
・hdf5 1.8.16 -> 1.8.15.1
・numexpr 2.6.0 -> 2.5.2
・numpy 1.11.0 -> 1.10.4
したところ、またグラフを表示できるようになった。どうも、numpyとnumexprを個別にアップデートしても問題でないが、numpyを1.11.0に、その後、numexprを2.6.0にするとSyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escapeと、エラーが出るので、何かこの組合せに問題があるっぽい。
P.41 図2-6 Sum of table1000.prop by year and sexの描画
np.linspace(0, 1.2, 13)を記述するので、import numpy as npしておく必要あり。
また、トップ1000より、トップ100を描画するほうが、比率の減少の傾向が顕著のように見える
とりあえず、importは、
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
しておけば良い感じですかね。
P.43 get_quantile_count()
APIの仕様変更により、以下のように記載する必要がある。
def get_quantile_count(group, q=0.5):
group = group.sort_values(by='prop', ascending=False)
return group.prop.cumsum().values.searchsorted(q) + 1
group.prop.cumsum().values.searchsorted(q)が変更箇所。
第3章
P.52 randn()のあたり
PycharmなどIPython以外で実行するとき、importが、
import numpy as np
import pandas as pb
import matplotlib.pyplot as plt
なら、randn()は、np.random.randn()と記載する。P.61だと、np.random.randn()が使われているから、ここは修正が必要なのかもしれない。英語サイトの正誤表にも記載あるし。
※githubからダウンロードできるJupyter notebookでは、importが、import numpy.random as randnになっていたしますね。ちょっと表記が統一されていないあたり混乱を誘いますけど、まあ、この本はPythonそのものを学ぶものじゃないからいいのかな。
P.58 IPython HTMLノートブック
いまは、Jupyterという名前です。
P.59 エディタ、IDEからのIPython利用
Pycharmでも、Jupyterノートブックを作成し実行することができます。.pyファイルと同様に作成ができます。Pycharmでやる意味がいまのところ、見いだせていないのですが。なにか便利な機能あるんですかね。%magicとか、%reset?とかは、2016/06/04現在、Pycharmからは実行しても結果を見ることができないですね。
処理速度を求めるのは、Pycharmの場合、有料版(Professional Edition)が必要になる。
第4章
P.90 data
data がいきなり登場するので、
data = np.random.randn(2, 3)
と解釈して、10倍にしたり、足し合わせたりする処理を確認した。書くまでもないが、Pycharmで実行しているので、
def main():
data = np.random.randn(2, 3)
print('data is\n', data)
print('data*10 is\n', data * 10)
print('data+data is\n', data + data)
if __name__ == '__main__':
main()
のように記載している。ここらへんは、素直に、IPythonを使う方が楽かもしれない。
P.95 numeric_stringsの定義
numeric_strings = np.array(['1.25','-9.6', '42'], dtype=np.string_)とあるが、numeric_strings = np.array(['1.25','-9.6', '42'])ではダメなんですかね。
なぜここであえて指定してるのか理由がよくわかりません。numeric_strings.dtypeの結果はかわってきますけど。
P.99 3次元配列
arr3d[0]が2×3行列であることにひっかかりました。x方向(行)y(列)z方向と考えると、
arr3d[z][x][y]=arr3d[z,x,y]ということなんだと思ったら理解できました。np.shape(arr3d)の結果も、(z,行,列)と解釈すれば理解できました。
x,y,zの順序じゃないってのは、あたり前なんでしょうか?他の言語やっているとあたり前?私は3次元配列を真剣に考えたのがPythonではじめてなので混乱しています。
P.101 namesの定義
本に記載しているように、
names = np.array(['Bob','Joe', 'Will', "Bob", "Will", "Joe", "Joe"], dtype='|S4')
とするとうまくいかないです。そもそも、何をしているのか、私には理解できないです。
とりあえず、
names = np.array(['Bob','Joe', 'Will', "Bob", "Will", "Joe", "Joe"])
で普通にうまくいくので、そうします。dataの定義には訳注がちゃんとありますね。なぜここにはあって、他に無いのかよくわかりませんが。
P.106 arr = np.arange(16).reshape((2,2,4))
2=z方向
2=x方向=行
4=y方向=列
と思えば理解できた。
arr.transpose((1,0,2)は、本来 0,1,2の順序であるものを、1,0,2とする、つまり、z軸とx軸の交換だと思えば、arr.transpose(1,0,2)のビューが、
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
であることは理解できました。
p.107 swapaxes
arr.swapaxes(1,2)は、z軸=0,x軸=1,y軸=2と考えて、x軸とy軸の入れ替えなんだと思えば、理解できました。
arr.swapaxes(2,1)も同じにならないとおかしいし、arrが2x2x3であることを考えると、例えば、arr.swapaxes(2,3)すればエラーだろうし、arr.swapaxes(2,2)は何も変わらないけどエラーにはならないであるべきだと思って試して見たら、実際そうだったので、どこかで確認できたわけではない自分の理解でよいように思いました。
P.108 randn
この前のページで遭遇しているし、訳注も前の登場箇所にはあったので、問題無いかとは思いますが、
import numpy as npしているなら、np.random.randn(8)と書かないとエラーになりますね。
P.111 関数sqrt(x^2+y^2)の取り得る値の図
最初はPycharmで実行する方針で進めていたのだけれど、だんだん面倒になって、IPython(Juypter Notebook)で進めていたためにひっかかりました。
本の通り入力しても、グラフが表示されないなあ、と思って悩んでいたのですが、単に
plt.show()すればよいだけでした。
しかし、mathematicaなどのように、インラインにグラフが表示されるものだと思っていたので、挙動が想定外でした(⇒%matplotlib inline と入力しておくと、インラインに表示されるんですね)。また、グラフのタイトルに、TeX形式で数式を挿入することができるのがちょっとした驚き。
Jupyter Notebook上でうまく表示するには、結局こんな感じになりました。
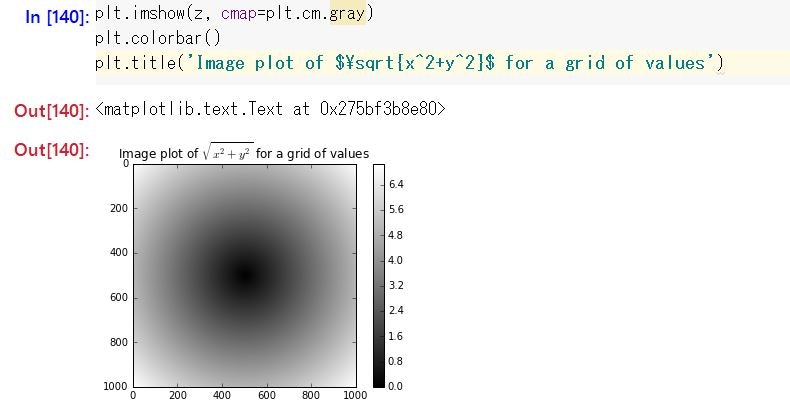
また、グレーのグラフではおもしろくないので、plt.imshow(z, cmap=plt.cm.magma)とかしてみたりもしました。受け付けられないカラー指定をインプットすると、受付可能な色指定の一覧が表示されるので、それを参考に、適当に入れてみました。
P.112 np.where
np.whareと誤植になっているところがある。
P.116 ソート
sort関数の軸の初期値は、-1。オフィシャルドキュメントより。
よって、2次元配列なら、何も指定しないとき、列方向がソートされる。
P.121 mat.dot(inv(mat))
mat.dot(inv(mat))の実行結果が本と合わない。
最初、NumPy配列のデータ型の変換として、mat.dot(inv(mat)).astype(np.float32)で対応できるかと思ったが、そういう話でもないみたいだったので、1000倍して整数に丸め(rint)、その後1000で除算した。正しい方法教えてください。
np.rint(mat.dot(inv(mat)) *1000) /1000
array([[ 1., 0., 0., 0., -0.],
[ 0., 1., 0., -0., -0.],
[ 0., 0., 1., 0., 0.],
[ 0., 0., -0., 1., 0.],
[-0., -0., 0., -0., 1.]])
P.121 行列の積
本のコメントに、np.dot以外の記法うんぬん、と記載がありますが、いまはこれがあって @ らしいです。
だから、X.T @ Xで計算ができるかと思います。
P.126 crossing_times = (np.abs(walks[hit30])>=30).argmax(1)
crossing_times = (np.abs(walks[hit30])>=30).argmax(1)を例えば、crossing_times = (np.abs(walks[hit30])).argmax(1)じゃだめなのか、とか、crossing_times = walks[hit30].argmax(1)じゃだめなのか、とかちょっと思ったんですが、
・絶対値が30以上
・あくまで、距離が最大のインデックスではなく、30以上の最初のインデックスがほしい
ということから、本の内容になっているのですね。
P.124の、「真偽値の配列の場合、一番最初にTrueとなるインデックスが戻る」というところが理解のポイントかと思います。
第5章
P.128 obj.indexの結果
書籍だと、Int64Index([0, 1, 2, 3])ですけど、手元で試すと、
RangeIndex(start=0, stop=4, step=1)
になります。
P.129 np.exp(obj2)
index=d の結果がおかしいような?54.6くらいですよね?
P.134 行の取り出し、列の取り出し
frame2.ix['three']が行の取り出しで、行の取り出しのときには、ix使うこと、
frame2['debt']のように、ix使っていない場合には、列の取り出しになること、
については、覚えておくべきところ。
P.141 ffill, bfill
ffill=前方に穴埋め
bfill=後方に穴埋め
と書かれていて、英語で、Fill values forward、Fill values backwardだから、そうなったんだろうけど、何か誤解しそう。
動詞+forwardで、「前方をみて(動詞)する」、という解釈が英語辞書みるとできそうなので、前方を使って穴埋め、bfillだったら、後方を使って穴埋め、くらいの表現のほうが覚えやすい。search forwardとかも、前方を見ながらsearchするって解釈ですよね?
P.144, 145 DataFrameにスライシングを使う場合
obj['b':'c']のように、スライシングを使った場合には、行に適用される。インデックス値参照data[:2]などでも同じ。
単にdata['two']とかする場合には、列(columns)に作用する。スライシングになると、行(index)に作用する。ちょっと混乱する。
他、JupyterNotebookを触りながら確認したこと。
・data[:3]は、data.ix[:3]と等しい。
・columns方向でスライシング使いたい場合は、data.ix[:,:3]などとする。これは表5-6に記載のあるように、列を取り出すobj.ix[:, val]の表現方法の1つと考えられる。
P.154 obj.order()
orderは現在では、非推奨のようです。sort_values()を利用するように、メッセージが表示されました。将来的にはエラーになるのかな?
P.155 frame.sort_index(by='b')
これも、現在は非推奨のようです。確かにわかりにくい。pythonからは、
frame.sort_values(by='b')が推奨されています。
p.155 frame.sort_index(by=['a', 'b'])
ここも、sort_valuesにするように言われますね。
ここは、a列でソートしたあとに、同じ値のところは、b列でソートする、ということなんですね。もう少し本に説明がほしいです。
P.158 df.sum(axis=1)
np.nanだけの足し算は、np.nanになるように本ではかかれているけど、2016/06/07現在試す限りでは、0.0になる。skipna=Falseのときの挙動は同じ。足すものが無い時には0になるのか。しかし、pandasの最新のマニュアルを確認すると、"Exclude NA/null values. If an entire row/column is NA, the result will be NA"と書かれているから、バグか?
P.159 df.describe()の結果
本では、すべての項目に数値が入っていますが、手元で試すと、
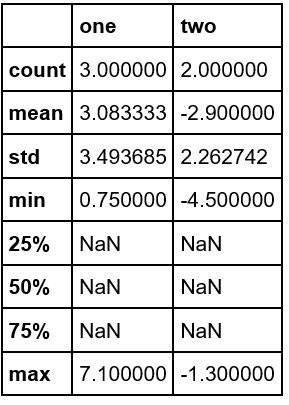
です。どこかのタイミングで仕様が変わったのでしょうか。マニュアルみても、よくわかりません。
pp.160 import pandas.io.data as web
これを実行すると、
The pandas.io.data module is moved to a separate package (pandas-datareader) and will be removed from pandas in a future version.
と表示されます。そこで、とりあえず、conda install pandas-datareaderしました。
importは、
import pandas.io.data as web
を
import pandas_datareader.data as web
として、うまくいきました。マニュアルだと、import pandas_datareader as pdrして、pdr.get_data_yahooしてもうまく行くように書いてたのですが、違うみたいですね。
all_data.iteritems()
ここの記述は、Python2系が前提のようです。Python3では、(dict).itemsの仕様が変更されているため、ここのあたりの記載は、
price = DataFrame({tic : data['Adj Close']
for tic, data in all_data.items()})
volume = DataFrame({tic: data['Volume']
for tic, data in all_data.items()})
で良いみたい。たぶん回答は、ここhttp://stackoverflow.com/questions/13998492/iteritems-in-python
に含まれてそうだけど、いまいち英語わからない。
P.162 objの定義
まねして入力するときに面倒だから、
obj=Series(list('cadaabbcc'))
と書いてもらいたいところ。
P.163 pd.value_counts(obj.values)
valueのカウントするんだから、単に、pd.value_counts(obj)と書いちゃだめなのかな。エラーにもならないし。
P.167 .dropna(thresh=3)
閾値の考え方で少し混乱したのですが、値がNaNじゃない数を設定している、ということなんですね。よくP.166を読んでみるとたしかに、そう書いています。逆にNaNの数だと思ってちょっと混乱してしまいました。
ところで、df.dropna(thresh=3)は、2とかにしたほうが、動作がわかってよいのではないでしょうか。
P.167 df.fillna({1:0.5, 3:-1})
これ、列3ってないんですけど、何してるんですかね。2の間違い?
P.168 df.fillna(0,inplace=True)
_ = df.fillna(0,inplace=True)って書いてあるのですが、_ =は編集ミスとかですかね?要らないですよね。
P.169 dataの定義
'a', 'a' ...と入力するのはめんどうだから、
data = Series(np.random.randn(10),index=[list('aaabbbccdd'),[1,2,3,1,2,3,1,2,2,3]])
をサンプルにしてほしい。
P.170 data.indexの結果
手元では、
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],
labels=[[0, 0, 0, 1, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 1, 2]])
になりました。ちょっとした仕様変更ですかね。
P.172 MultiIndex
importによりますが、この本の記載のようにimportしていたら、
pd.MultiIndex.from_arrays([['Ohio','Ohio','Colorado'],['Green','Red','Green']],
names=['state','color'])
というように、pd書かないと、だめですね。これ、翻訳するときに、中身確認してないのかな。
P.176 pdata.swapaxes('items', 'minor')
この直前での結果が、
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 868 (major_axis) x 6 (minor_axis)
Items axis: AAPL to MSMT
Major_axis axis: 2009-01-02 00:00:00 to 2012-06-01 00:00:00
Minor_axis axis: Open to Adj Close
だったので、pdata = pdata.swapaxes('items', 'minor_axis')としてみましたが、_axisはあってもなくてもどちらでもいいみたいですね。どちらであっても、エラー出ないです。
この前の部分でも、importは、
import pandas_datareader.data as web
です。
第6章
read_csv(), read_table()
read_csv()と、read_table()を区別して書かれているが、read_csvも、read_tableも同じように、sep=を指定して、ファイルを読み込むことが可能です。
P.186 tot.order()
tot.sort_values()が推奨になります。
P.186 tot.add(piece['key'].value_counts(), fill_value=0)
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
のあたりですが、Seriesのaddのマニュアルをよむと少し理解が深まります。
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.add.html
fill_values=0と、NA値の処理をしないと、NAを含むSeriesの足し算の結果が、NAになり、集計結果がNAだらけになることを防ぐ目的で、.addが利用されています。
P.187 sys.stdout
事前に、
import sys
しておかないと、通りません。ここらへんは、Python言語には習熟している前提で記載されていないんですかね。
P.188 data.to_csv(sys.stdout, index=False, cols=['a','b','c'])
マニュアル
http://pandas.pydata.org/pandas-docs/version/0.18.1/generated/pandas.DataFrame.to_csv.html
にあるように、
data.to_csv(sys.stdout, index=False, columns=['a','b','c'])
にしないと動作しないです。
ひとつ気になるのが、cols、としたときには、エラーにならず、単に所望の列以外もピックアップして書き出されることです。エラー出るべきでは?バグ?
P.188 tseries.csvの中身
手元の環境では、本の結果とは異なり、時刻情報は無く、
2000-01-01,0
2000-01-02,1
2000-01-03,2
2000-01-04,3
2000-01-05,4
2000-01-06,5
2000-01-07,6
となりました。
P.189 print line
Python3では、print(line)です。
P.192 to_json, from_json
to_jsonと、from_jsonを実装する試みがある、という記載があります。
to_jsonは、2016/06/08現在、マニュアルによると、実装されているみたいですね。from_jsonのほうは、マニュアルに記載がないので、まだ実装されていないのでしょう。
P.192 urlib2
Python3ではパッケージが統合されて、urllibのみになっているらしい。
また、from urllib import urlopenに修正するだけではだめで、from urllib.request import urlopenとしなければならない。これも、Python2から3への変更が影響している。
参考:http://diveintopython3-ja.rdy.jp/porting-code-to-python-3-with-2to3.html
※ここらへんのPython2と3の差分の影響は、自動でソース変換するプログラムを使った後に、差分を評価して正誤表として公開してくれればいいのに。
P.198 バイナリデータ(Pickleデータ?)の読み込み
pd.load()
とあるが、最新のpandasでは、
pd.read_pickle('ch06/frame_pickle')
になっている。
参考:http://pandas.pydata.org/pandas-docs/stable/io.html#io-pickle
第7章
P.206 Pd.merge(df1, df2)
手元で試すと、本の記載とは少し結果の順序が異なっています。
本では、keyでソートされているような順序ですが、手元では、df1(data1)でソートされているような結果です。
P.208 デカルト積
直積集合というみたい。はじめて聞いたなあ。
参考:https://ja.wikipedia.org/wiki/%E7%9B%B4%E7%A9%8D%E9%9B%86%E5%90%88