rep の存在をすっかり忘れるほどRから遠ざかっていたのでメモ。
以下のような度数分布的なCSVをもらった。
中身がこんな感じのファイルからヒストグラムを得たいらしい。
$ head freqency.csv
var,freq
0,22516
1,199
2,178
3,453
4,175
5,261
6,177
7,196
8,199
変数ごとの頻度がもうすでにあるのでそのまま plot してあげればいいと思いきや、
$ tail freqency.csv
7790,1
7779,1
3834194,1
7688,1
15450,1
38837,1
7726,1
7720,1
30848,1
23264,1
全然ソートされてない上に割と要素数も多い。
ソートぐらいだったら前処理としてやってあげてもよいのだけれどせっかくなので生データをそのまま使う方向で書いてみた。
freq.vec <- function(csv, xs = 0, xe = 0) {
# 与えられた度数分布のCSVからhist関数に与えるベクトルを取得する
# 引数:
# csv: 1カラム目が変数、2カラム目が頻度となるCSVファイル
# xs, xe: それぞれ変数の下限と上限(与えなかった場合は変数の最小値と最大値を利用する)
# 返り値:
# 変数値が頻度の数だけ繰り返されたベクトル
d <- read.csv(csv)
vars <- d[[1]]
xs <- ifelse(xs == 0, min(vars), xs)
xe <- ifelse(xe == 0, max(vars), xe)
d.ext <- d[vars >= xs & vars <= xe, ]
rep(d.ext[[1]], d.ext[[2]])
}
今回は外れ値がとてつもなく多かったため変数の幅を狭めるようなことしたけどそうでもなければ
ぶっちゃけこんな関数書くほどでもなく普通に rep すればよいだけ。
実際使うとこんな感じ。
> freq1 <- freq.vec("frequency.csv", xs = 1, xe = 1000)
> hist(freq1, col = "#0000ff40", border = "#0000ff", labels = T, breaks = 20)
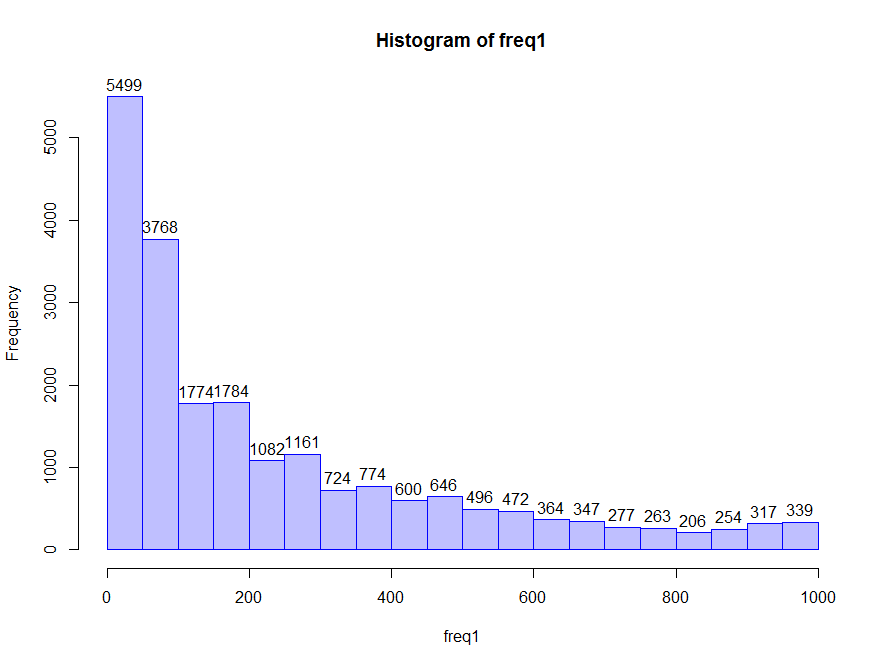
hist で引数 breaks を調節することでいい感じに出力してくれるのはホントありがたいですね。