日付が変わり、さくらインターネットは20周年を迎えました。
これまでありがとうございました。これからもよろしくお願いします!!
と言うことで、さくらの聖夜から帰ってきて、日付が変わってしまい恐縮ですが、hadoopについて簡単に書こうと思います。
はじめに
なぜ今になってhadoopの構築を書いてるのか、というところから。
先日、大量のデータに共通の処理をしないといけない事情が発生したため、急遽hadoopのクラスタを構築しました。
以前セットアップして使ったのは4年前の学生時代の時で、当時の記憶が全く残っておらず、ドキュメントを読みながらセットアップしました。
定常的に使うことはないのですが、突発的に必要になることがあるので、せっかくなのでAnsibleのPlaybookにしましたのでご紹介します。
(構築したものの、悲しいことに今回は案件がなくなり不要になってしまいました...)
hadoopとは
簡単に言うと、複数のホストで、たくさんのデータを管理し、それらのデータに対し並列で処理を行うことができる大規模データ分散処理のフレームワークです。
データを管理するHDFS (hadoop File System) と、ジョブを管理するYARN (Yet Another Resource Negotiator) で構成されています。
並列で処理をする手法は色々ありますが、hadoopではMapReduceが使われることが多いです。
MapReduceは、一つ一つのファイルに対してある一定の処理を独立・分散して行い (Map) 、それらの結果を並べ替え (Shuffle) 、集計する (Reduce) というロジックになっています。
例えば、「大量のテキストファイルに対し、語彙ごとの発生数を数える」などに適しています。
この場合、Mapでは一つのファイルに対して、
- テキストファイルを形態素に分解
- 形態素ごとに発生頻度を数える
と言う処理を行い、Reduceで、
- 各ファイルでの形態素ごとの発生頻度を合計する
という流れになります。
hadoopを使えば、MapとReduceの処理さえ自分で書けば、大量のテキストファイルの保管はHDFSが、MapReduceの並列実行はYARNが自動的に行ってくれます。
サーバの準備
今回はさくらのクラウドに6台のサーバを構築用意します。
インターネットに直接つながず、VPCルーターを使い、各サーバにはローカルIPアドレスを付与しました。
OSはちょっと古いですがUbuntu 14.04を使っています。
| IP Address | Hostname | Roles |
|---|---|---|
| 192.168.11.101 | hadoop-01 | namenode, datanode, yarn |
| 192.168.11.102 | hadoop-02 | datanode, yarn |
| 192.168.11.103 | hadoop-03 | datanode, yarn |
| 192.168.11.104 | hadoop-04 | datanode, yarn |
| 192.168.11.105 | hadoop-05 | datanode, yarn |
| 192.168.11.106 | hadoop-06 | datanode, yarn |
さくらのクラウドにサーバを用意するとこのようなマップになると思います。
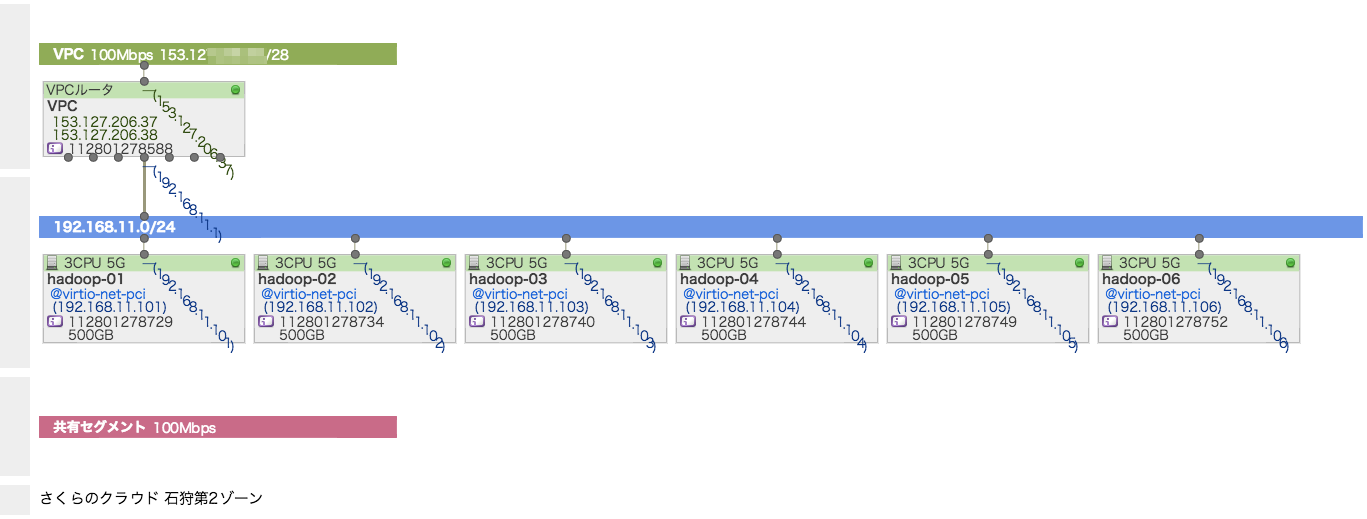
VPCルーターにはL2TP/IPSecを使ったリモートアクセスの機能がありますので、VPNを通してこれらのサーバーにアクセスすることとします。
パスワードは、この後のPlaybookと合わせるために、kotamagoH@doop としておいてください。
(あるいはPlaybookの実行前に、 group_vars/all に記載のパスワードを変更してください)
AnsibleのPlaybook
今回利用するPlaybookを github.com/chibiegg/hadoop-ansible においておきました。
以下のようにすることで、AnsibleのPlaybookを適用することができると思います。
git clone https://github.com/chibiegg/hadoop-ansible.git
cd hadoop-ansible
ansible-playbook -i hosts -KkS -u ubuntu site.yml
HDFSの確認
ブラウザから http://192.168.11.101:50070/ にアクセスすることで、HDFSのステータスを確認することができます。
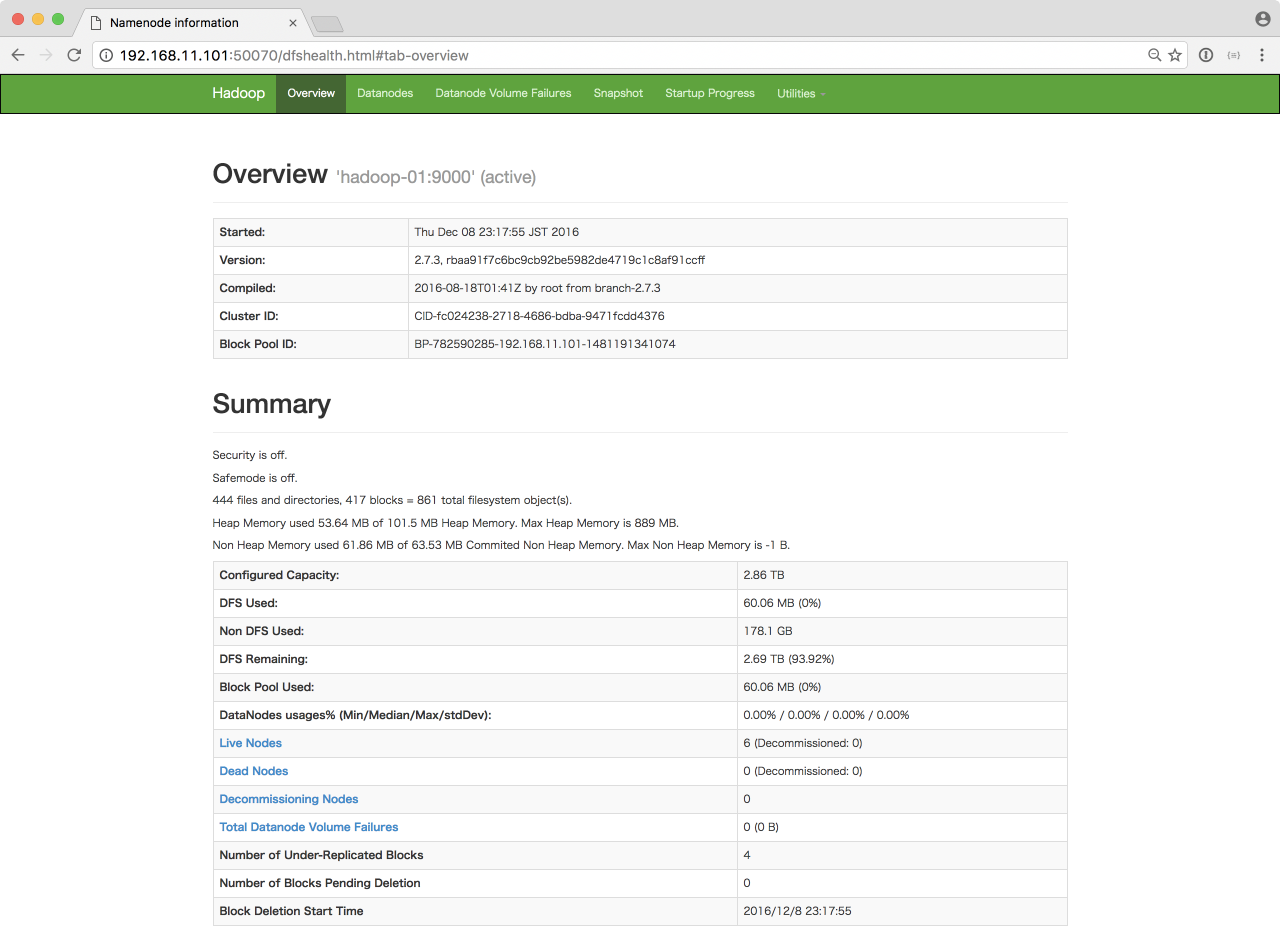
http://192.168.11.101:50070/dfshealth.html#tab-datanode では、各データノードの状態を確認することができます。
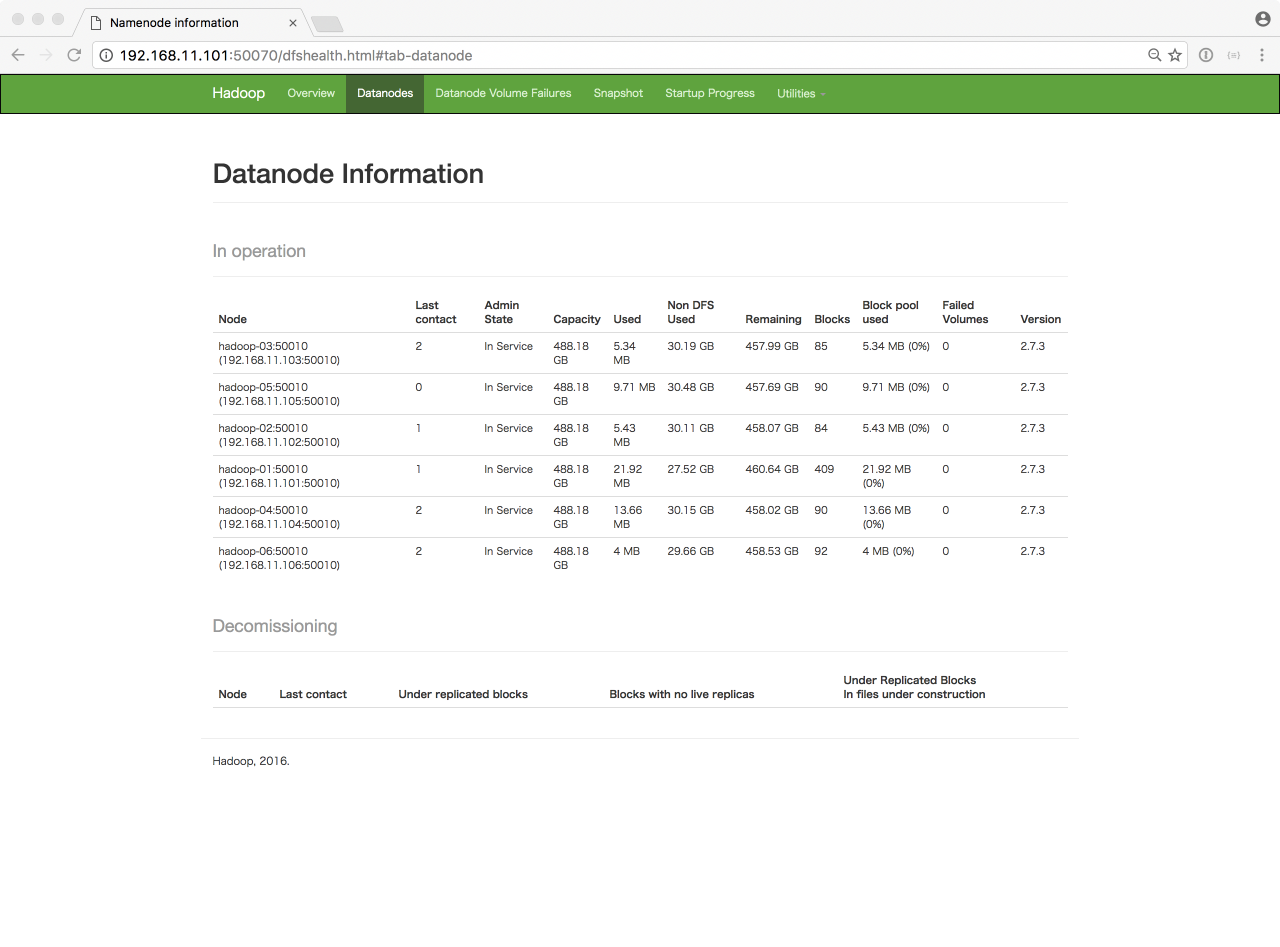
正常に、6台のデータノードが稼働していることがわかります。
HDFSへのファイルの追加は、hadoopユーザーで以下のコマンドを実行することにより行います。
/usr/src/hadoop-2.7.3/bin/hadoop fs -put [source] [destination]
YARNの確認
YARNのステータスや、実行しているアプリケーションの情報は http://192.168.11.101:8088/ から参照することができます。
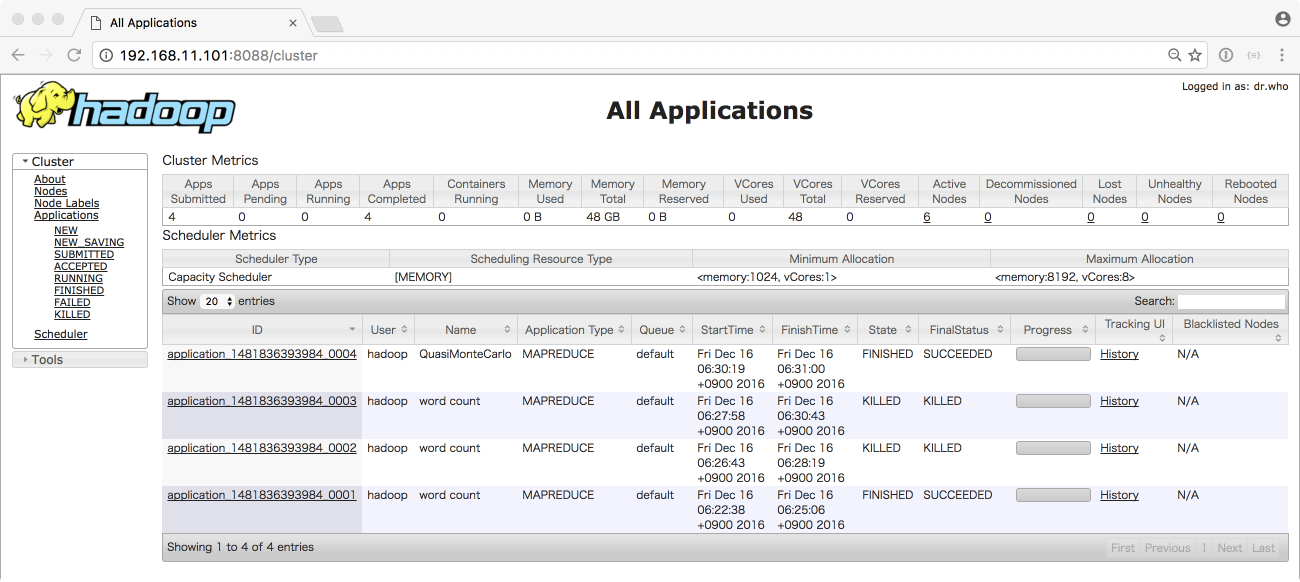
アプリケーションの実行
今回は、サンプルとして入っている円周率を求めるアプリケーションを実行してみたいと思います。
cd /usr/src/hadoop-2.7.3
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 30 100
円周率だけでなく、単語数のカウントやいろいろなサンプルが hadoop-mapreduce-examples-2.7.3.jar には入っていますので、色々試してみてください。