みなさん ライントレーサーってご存知ですか?
メカトロの入門として遊んだ方もいくらかいるのではないでしょうか。

今回はChainerでやってみるDeep Q Learning - 立ち上げ編 に引き続き、
基礎体力づくりとしてライントレーサーにDQNで校庭を走らせることにしました。
GitHubにも置きました。良いパラメータやモデル、アルゴリズムなど見つけたら教えてください。
GitHub : DeepQNetworkTest/DQN003.py
プログラムの雰囲気
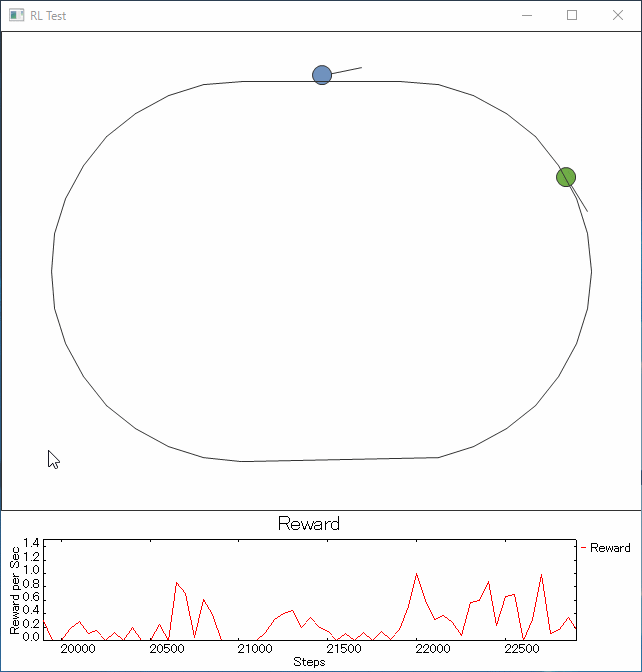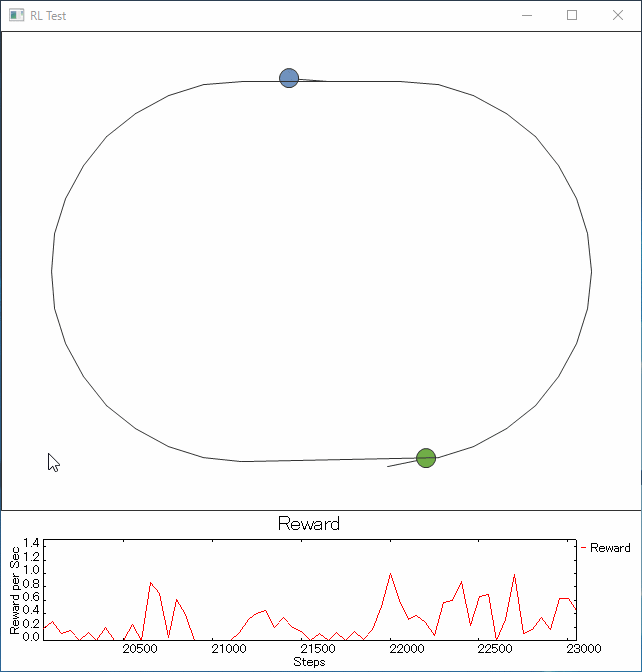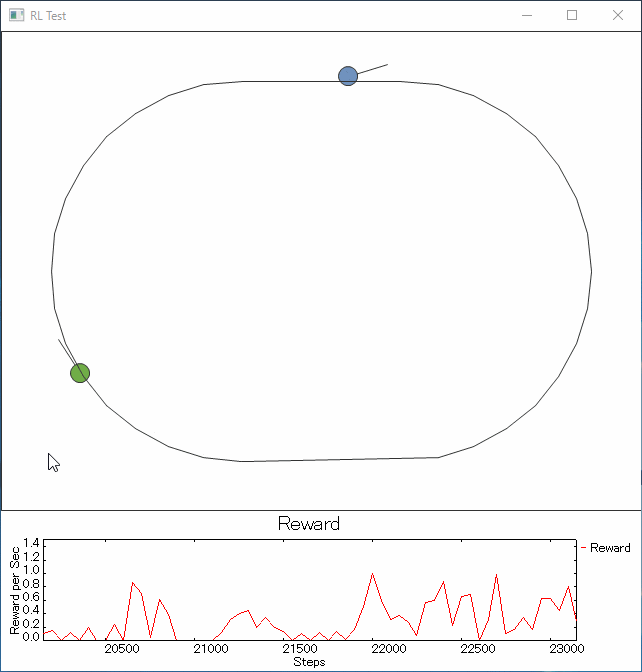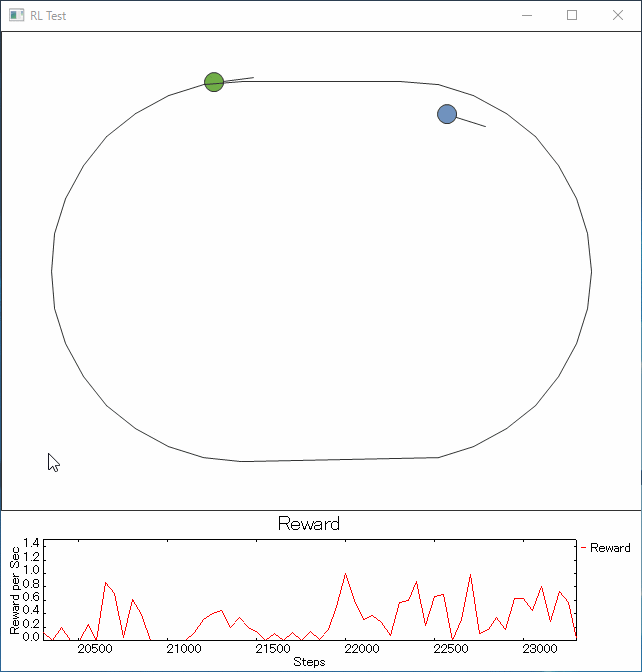
ライントレーサーは前記Youtubeのロボと同様に光センサ1個の情報で動きます。
走行はmobile robot風に左輪と右輪の速度差などで向きを変えたり前進したりする仕様。慣性はない。
線の太さはグラフィックとして書かれている1pxを中心に幅10pxです。
緑色
そっけないルールベース ライントレーサー
# 線が見えているとき
if self.EYE.obj == 1:
# [左輪速度、右輪速度] // 左曲がり
action = [0.5, 0.1]
# 線が見えていないとき
else:
# 右曲がりに移動
action = [0.1, 0.5]
光センサがコースを検知したら左曲がりに進行、検知しなかったら右回りに進行、という味気ないやつ
青色
僕らの期待の新星DQN
入力:[[光センサの検知/不検知][前回とった行動]]を1セットに過去5個分 : 20次元
隠れ層:50ユニット x 2枚ほど
<実は前の記事で隠れ層が1枚なのに2枚と勘違いしてました>
出力:左曲がり進行、直進、右曲がり進行
ご褒美:コースから5px以内 +1ポイント
10px以内 +0.5ポイント
壁際2px以内 -1ポイント
そして、壁にぶつかったら張り付き続けてしまい学習時間に支障が出そうになるのでコース上に位置リセット。
現状の状況
いくら直近の過去のことを覚えていても自分の位置もわからない一つ目お化けじゃ迷子になる様子?
せめて2つ以上センサーがあるようなライントレーサーにしたり、自分の位置を計算したりするなど何らかの手段で、自分とコースの位置関係を把握できるようにしないと上手く走れるようにならないのかなぁ。
たまに半周くらい上手く走ってくれると「おぉぉぉぉお、今回こそは!」と手を汗を握りますが毎度残念。眺めているのは楽しいです。でも少なくとも15分くらいの教育ではダメみたい。
50分くらいの教育結果
1つ目 ライントレーサーと視野を持たせたライントレーサーの学習を競争させてみると、
やっぱりというか視野を持ったロボットの方がラインをトレースできるようになるのが圧倒的に早い。
というか1つ目君は迷子になった子にしか見えない。せめて線の濃淡を見えるようにしてあげた方がよかったのだろうか。
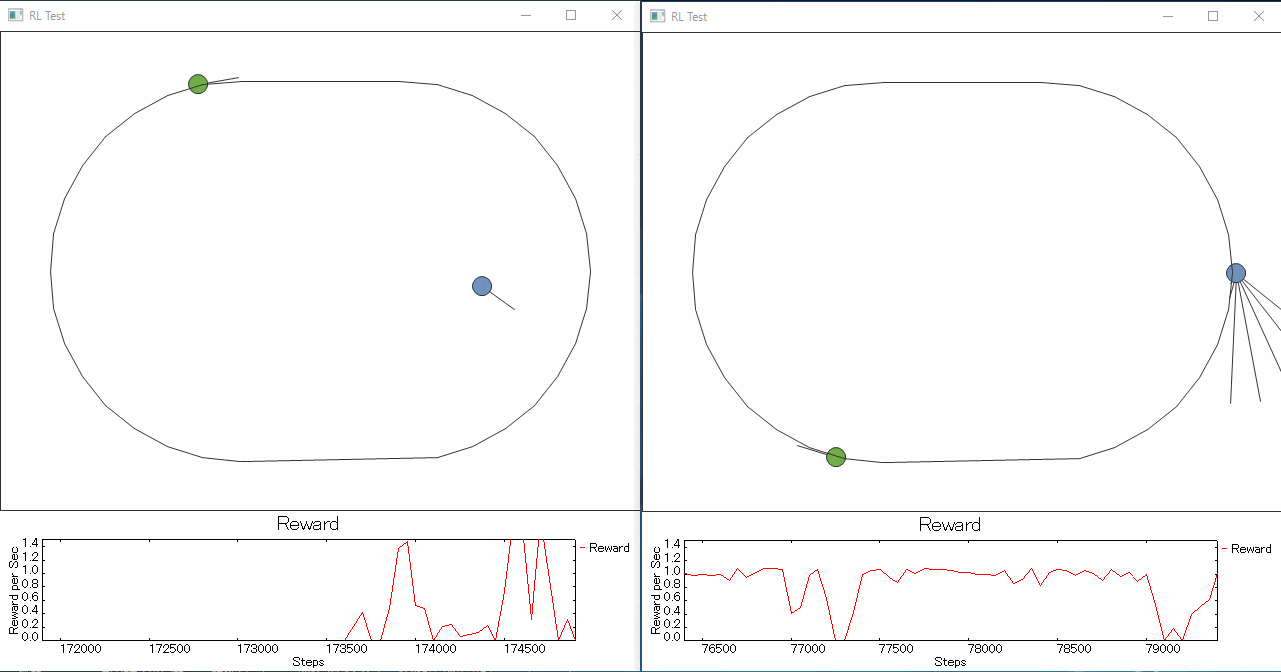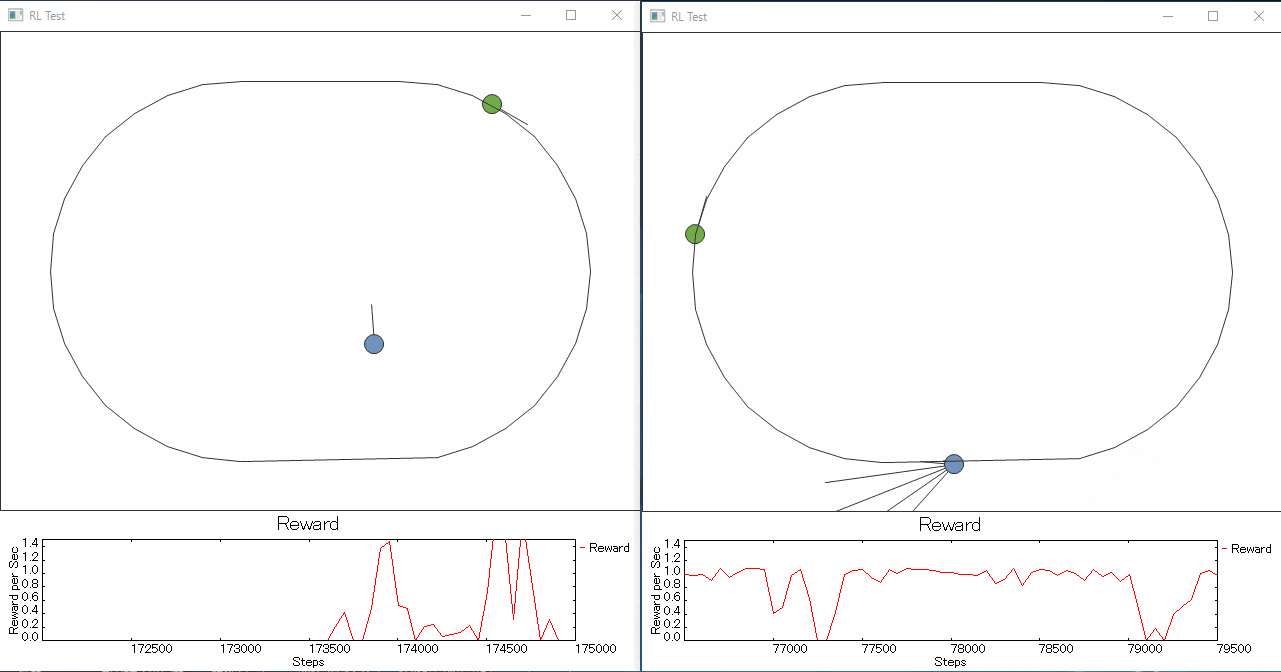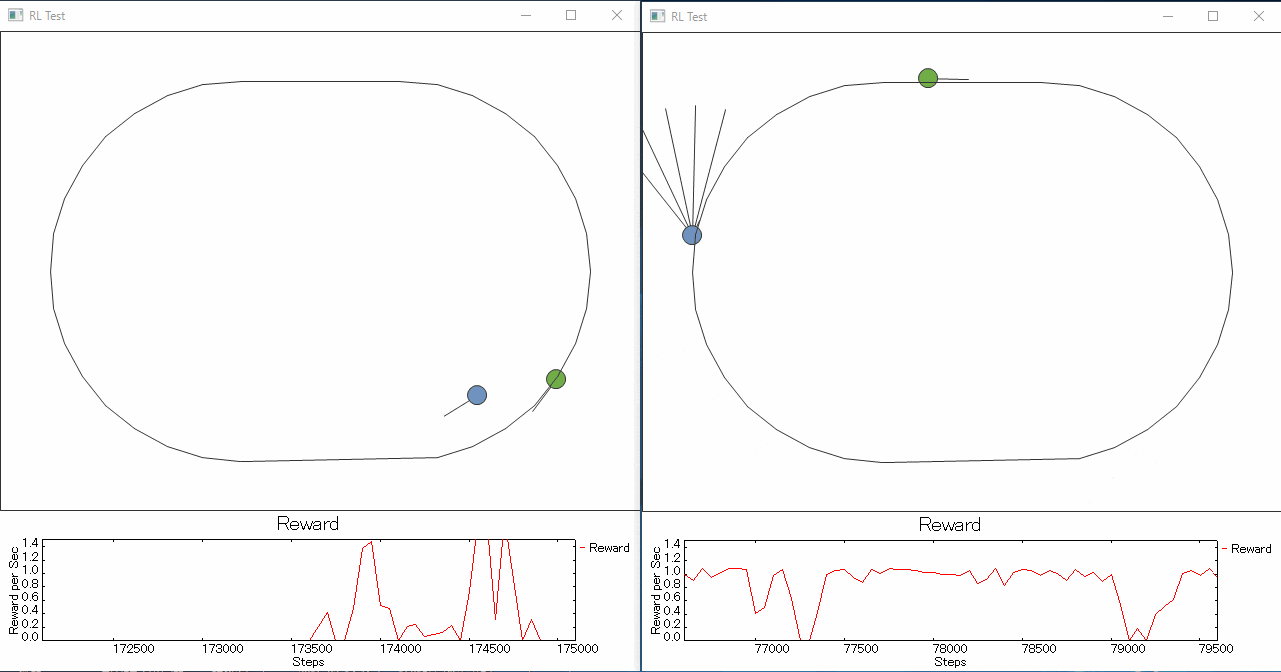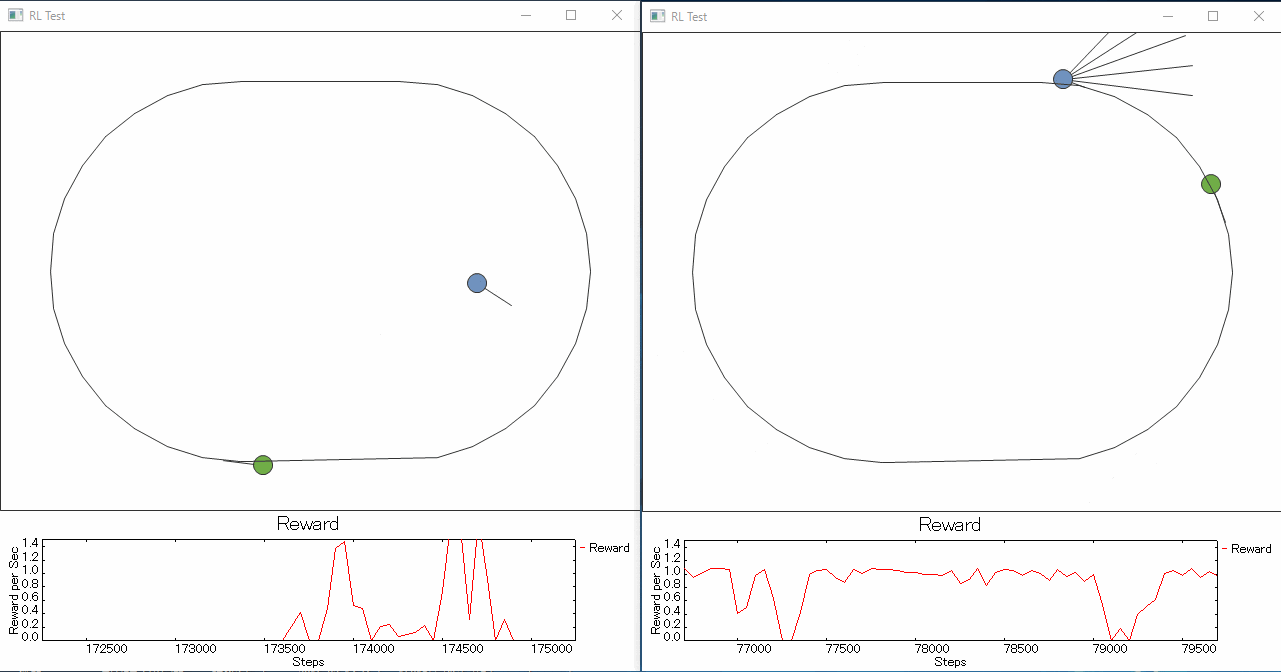
右の例でネットワークの規模は入力数以外変えてないのですが、(NN: 18 x 50 x 50 x 3)
コースをたどる程度のレベルだと、こちらのデモは意外と手の届く範囲にあるかもしれない。
しかし、273 x 600 x 400 x 200 x 100 x 50 x 5という、
かなり大規模なNN使っていますよね。
ただ難易度の高そうなのがいくつか残っていますね。
- 分散学習
- コースのトレース
- 車同士の衝突回避
- モータや慣性など物理応答の反映
- 重力・斜度などの外乱対応
- 画像認識から車体位置把握 → やらないと思う
- 無線による遠隔操作、むだ時間 → 興味あるけどロボカー買えるおこづかいがあったら…
条件を複雑にしていくと、うちのショボパソコンだときつそうだけど、
逆に、これだけの計算回しても絵を描けるって大分早くなったよなぁ。
全部マイコンでできる時代も、もう少しか!?
追伸
そうこう書いている間に、一つ目くんも校庭1周走れるようになってた。
君も合格だ!!!
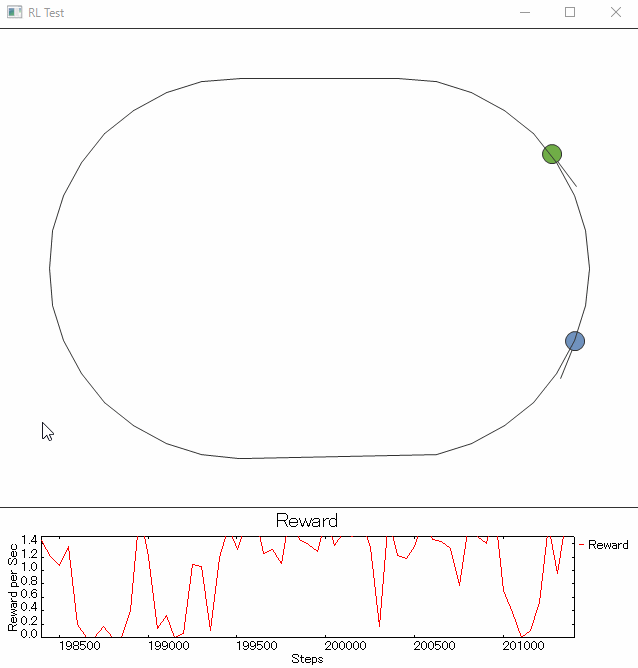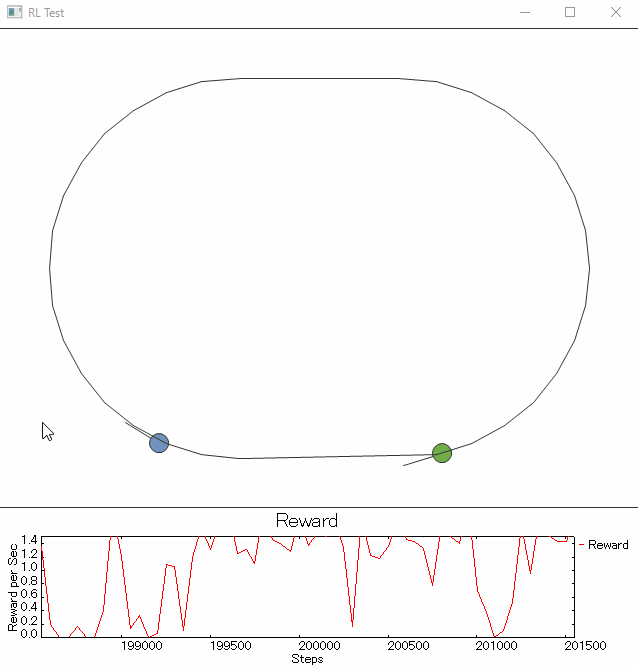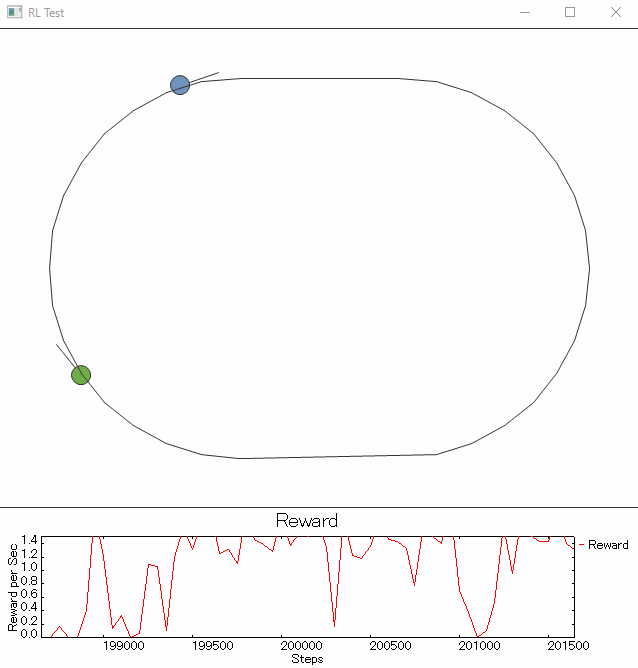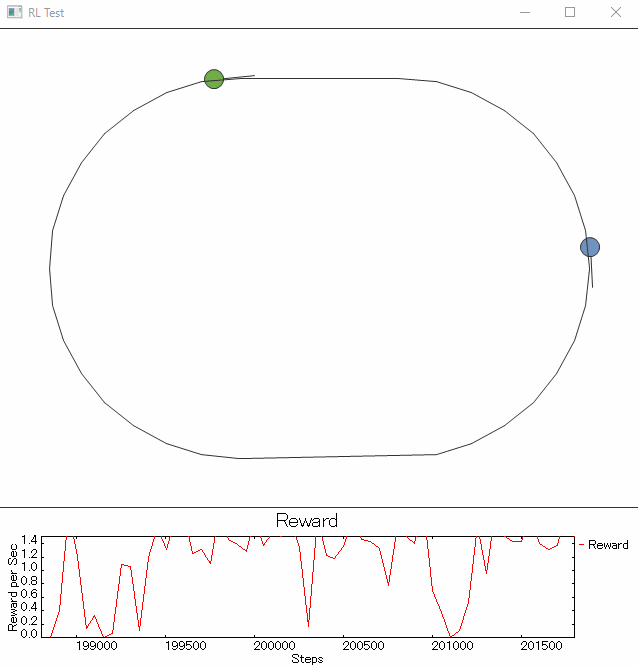
少し、ご褒美をいじっています
# Reward
# コースにどれだけ沿っているかのご褒美
proximity_reward = 0.0
if self.Course.adLines([ag.pos_x, ag.pos_y], 5.0):
proximity_reward = 1.0
elif self.Course.adLines([ag.pos_x, ag.pos_y], 10.0):
proximity_reward = 0.5
# 壁にぶつかったら罰則
if self.Box.adLines([ag.pos_x, ag.pos_y], 3.0):
proximity_reward -= 1.0
# 直進を選好するようにご褒美
forward_reward = 0.0
if(action[0] == action[1] and proximity_reward > 0.75):
forward_reward = 0.1 * proximity_reward
# センサがコースを検知し続けるようなインセンティブ
eye_reward = 1.0 if ag.EYE.obj == 1 else 0.0
# ご褒美の合計
reward = proximity_reward + forward_reward + eye_reward