Python3に対応しました(2016.01.25)
Pythonでの機械学習を支援する,MALSS(Machine Learning Support System)というツールを作りました(PyPI/GitHub).
前回 は導入方法などについて書いたので,今回は基本的な使い方についてです.
パッケージのインポート
まずMALSSをインポートします.
from malss import MALSS
データの準備
つぎにデータを準備します.
今回はこちら の書籍で使われているHeart Disease Dataを使います.
AHDのカラムが心臓病か否かを表していますので,これを予測することを目的とします.
今回のデータは説明変数(予測に使う値)がカテゴリ変数(数値でないもの)を含んでいるので,
読み込みにはpandasライブラリを利用しています.
全て数値のデータであれば,numpyのloadtxtメソッドでもよいです.
import pandas as pd
data = pd.read_csv('http://www-bcf.usc.edu/~gareth/ISL/Heart.csv',
index_col=0, na_values=[''])
y = data['AHD']
del data['AHD']
分析
いよいよ分析を行います.
といってもインスタンスを生成し,fitメソッドを実行するだけです.
データ量やマシンスペックにもよりますが,分析には数分~数十分の時間がかかります.
cls = MALSS('classification',
shuffle=True, standardize=True, n_jobs=3,
random_state=0, lang='jp', verbose=True)
cls.fit(data, y, 'result_classification')
コンストラクタMALSSへ渡す引数で必須のものは,分析タスクのみです.
今回はラベル(Yes/No)を予測する分類(識別)タスクなので"classification"です.
値を予測する回帰タスクでは"regression"になります.
それ以外のオプションは初期値が設定されているので,入力は必須ではありません.
shuffle は機械学習を行う際にデータをシャッフルするか(初期値:True),
standardize はデータを基準化(各列を平均0,分散1に)するか(初期値:True),
scoring は評価指標名または評価関数(初期値:None(分類:F1値,回帰:MSE)),
n_jobs は並列実行数(初期値:1),
random_state は機械学習が乱数を用いるときのシード(初期値:0),
lang は分析レポートで使用する言語(初期値:en(英語)),
verbose は途中経過をコンソールに出力するか(初期値:True)です.
fitメソッドの引数は,入力データ(特徴量/説明変数)と出力データ(目的変数),出力先ディレクトリ(デフォルト:None)です.
出力先ディレクトリが渡された場合,分析結果のレポートを出力します.
レポートの確認
↑で指定したディレクトリ内のreport.htmlをブラウザで開きます.
(※注:スクリーンショットの内容は古いVer.のものである可能性があります)
分析結果
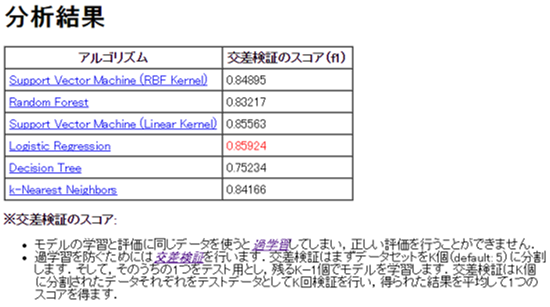
分析タスクとデータ(主にサイズ)に応じていくつかの機械学習アルゴリズムが自動で選択され,各アルゴリズムの交差検証スコアが表示されます.
この表をみると,今回のデータに対しては,ロジスティック回帰(Logistic Regression)を用いた場合のスコアが最も高いことが分かります.
機械学習を用いた分析では,モデルが与えられたデータのみに過剰に適応してしまわないように, 交差検証 という手法が用いられます.このことについて,※以下で解説するとともに,専門用語については解説ページ(Wikipediaなど)へのリンクを貼っています.
慣れてきたら,verboseオプションをFalseにすることで,このコメントを表示しないようにすることができます.
データ概要

次にデータの概要が表示されます.
MALSSには, ダミー変数 を使ったカテゴリ型データの変換機能と, 欠損値の補間 機能があり,それらについての解説もついています.
アルゴリズム別分析結果
以降,アルゴリズムごとの分析結果が表示されます.
パラメータチューニング結果
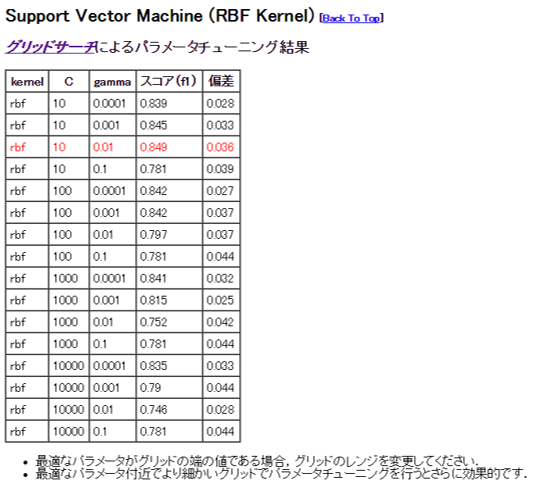
たいていの機械学習アルゴリズムはパラメータを調整することで性能が変化します.調整するパラメータが複数ある場合には, グリッドサーチ によりパラメータをチューニングします.
コメント部分に記載されているように,最適なパラメータ(赤字部分)がパラメータ変化幅の端の値である場合,幅を変更する必要があります(変更方法については次回記載予定です).この図の場合,パラメータ C が1の場合などを検討してみると良いことが分かります.
パラメータの詳細などは,アルゴリズム名のリンクからscikit-learnのドキュメントに飛んで確認してください.
分類結果

分類/識別タスクにおいて,ラベルの比率に偏りがある場合,単純に精度(予測が合っていた割合)で評価することが適切でない場合があります(例えばAHDがYesのデータが全体の1%であった場合,常にNoと予測するモデルの精度は99%になります).
このようなケースでは, F値 (F1値)などが評価指標としてより適切です.
学習曲線
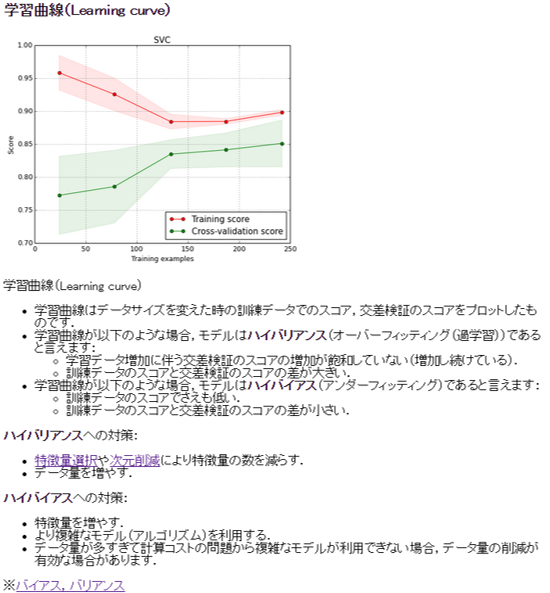
最後に, 学習曲線 が表示されます.
学習曲線はデータサイズを変えた時に評価スコアがどのように変化するかを図示したものです.
学習曲線をみることで,モデルがどのような状態( ハイバリアンス か, ハイバイアス )かを確認し,性能を上げるためにどうすれば良いのかのヒントを得ることができます.
モジュールサンプルの出力
自動で分析をすることができても,システムに組み込むことができなければ意味がありません.
MALSSでは,評価スコアの最もよい学習アルゴリズムを使ったモジュールのサンプルを出力することができます.
cls.generate_module_sample('sample_code.py')
出力したモジュールサンプルはscikit-learnの機械学習アルゴリズムと同じように,fitで学習,predictで予測ができます.
from sample_code import SampleClass
from sklearn.metrics import f1_score
cls = SampleClass()
cls.fit(X_train, y_train) # X_train, y_trainは学習用データ(MALSSに渡したものと同じでOK)
pred = cls.predict(X_test) # X_testは実システムに入力される未知データ
print f1_score(y_test, pred)
実際には,都度モデルを学習するようなことはないと思うので,学習済みのモデルをpickleでdumpしておくのが良いと思います.
おわりに
MALSSの基本的な使い方について解説しました.
分かりづらいところなどご意見頂けると嬉しいです.
次回は自分でアルゴリズムを追加するなど,応用的な使い方について書く予定です.