Watson NLC Toolkitとは
Watson Natural Language Classifier (NLC)は機械学習を使ってテキスト分類を行うサービスです。詳細は以前の記事「密かに日本語化されたWatson Natural Language Classifier (NLC)でテキスト分類」をご覧ください。この記事にもありますが、NLCを利用するには以下の3ステップを行う事になります。
- トレーニングデータ(CSV)の作成
- 分類器の作成とトレーニング開始、利用可(avaiable)まで待機
- 分類器の使用
これらの各ステップをブラウザベースで容易に行うことができるようにするツールがNLC Toolkitです。
NLC Toolkit利用の基本的な流れと注意事項
NLC Toolkitは、オリジナルのリポジトリからクローンを作成、Bluemixに配置すれば、利用できるようになります。
ただし、いくつか注意点があります。ひとことでいえば課金に要注意ということです。
- Bluemix上で動作させるアプリケーションですので、リソース利用課金が発生します。
- Cloudantを使いますので、サービス利用課金が発生します。
- 使いやすいということでNLCトレーニングを多数行った場合、月内5回目以降あNLCのサービス利用課金が発生します。
さて、こうしたことをふまえて、実際にNLC Toolkitを導入してみましょう。
NLC Toolkitの導入
事前に準備するもの
以下のものは事前に準備しておいてください。
- Bluemixアカウント(Bluemix DevOps Servicesも同じID)
プロジェクトのクローンと初回デプロイ
まず、ツールのテンプレートとなるリポジトリを開きます。
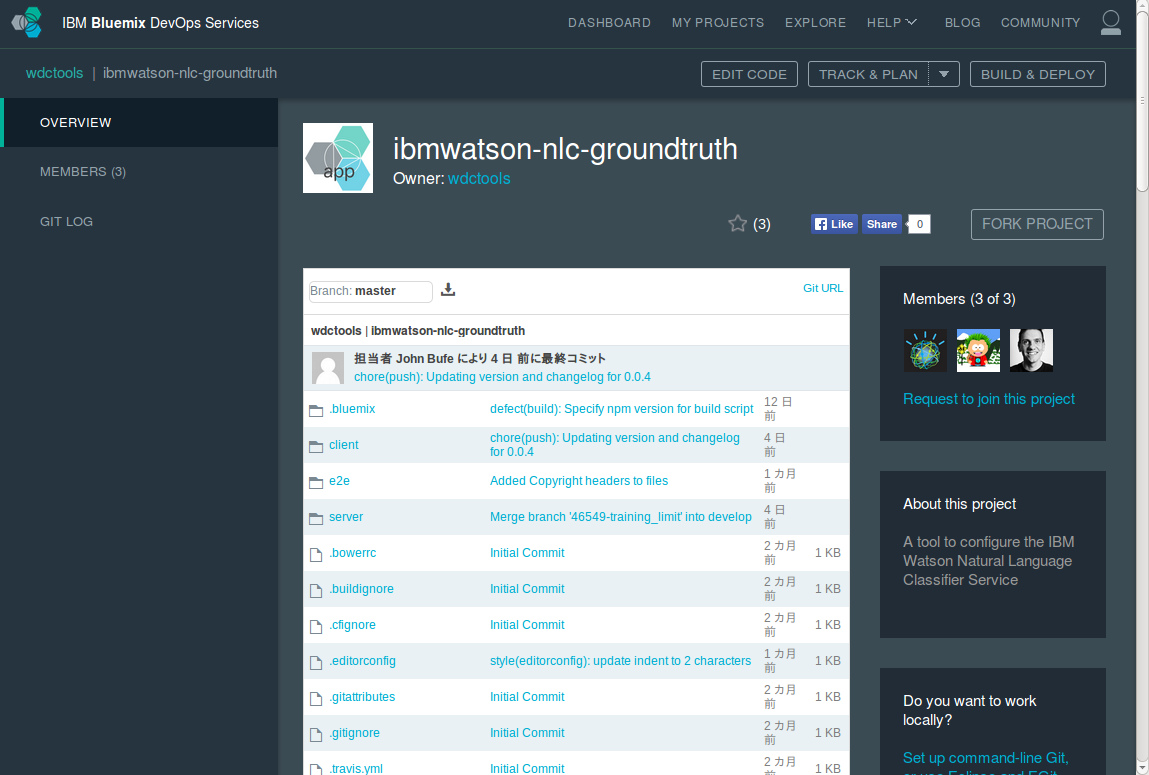
この状態でファイル構成の下にある説明まで下がっていくと、「Deploty to Bluemix」というボタンが出現します。

これをクリックすると、このプロジェクトをBluemixへデプロイするための画面に遷移します。アプリケーション名(ホスト名にもなります)が生成されていますので、必要であれば変更してください。また、Bluemixのリージョン、組織(organization)、スペースも必要に応じて変更してください。なお、Bluemixのセッションが切れている場合はこの画面の前にBluemixへのログインを要求されます。
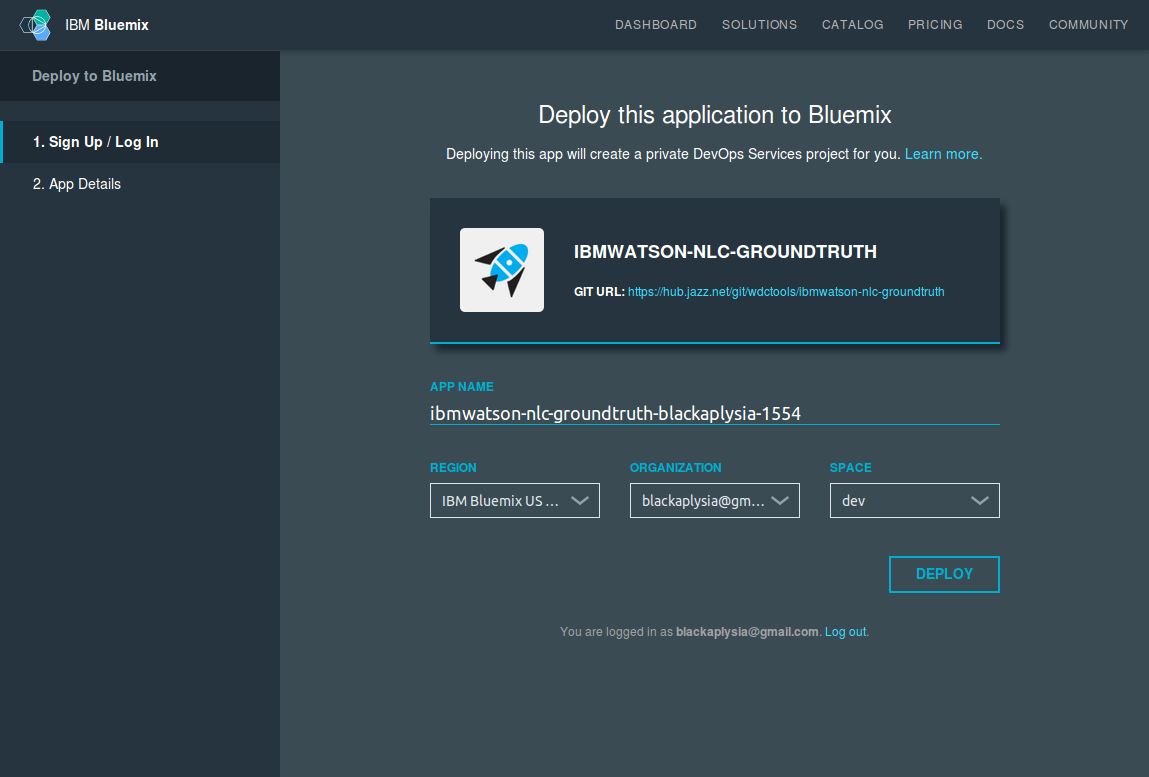
ここで「DEPLOY」をクリックすると、DevOps Servicesはログインしているユーザのリポジトリを作成し、ビルドし、指定されたアカウント、リージョン、組織、スペースへのデプロイを行います。すべて成功した場合には次のような画面になります。

この時点で、すでにアプリケーションは起動しており、「VIEW YOUR APP」をクリックすると、アプリケーションのログイン画面が開きます。一方、「EDIT CODE」をクリックすると、DevOps Servicesのプロジェクトが開きます。
それでは、「VIEW YOUR APP」をクリックして、ログイン画面(http://<アプリケーション名>.mybluemix.net/login)を開いてみましょう。
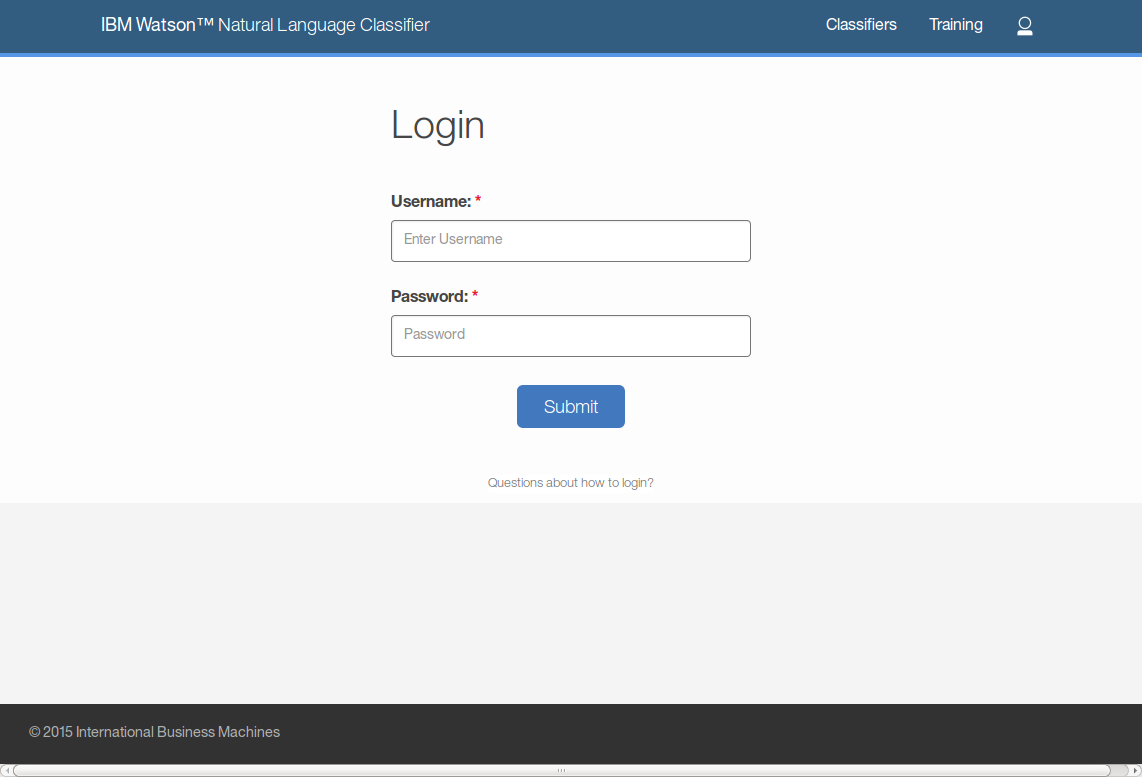
ログイン画面にはユーザ名とパスワードがあります。ここには何を入れればいいのでしょうか? そのこたえは、NLCの認証情報(credentials)です。認証情報を確認するには、Bluemixのダッシュボードでアプリケーションの環境変数を表示します。環境変数VCAP_SERVICESの中身であるjsonに埋め込まれている、natural_language_classifierの中のcredentialsの中にあるusernameとpasswordが必要な情報です。
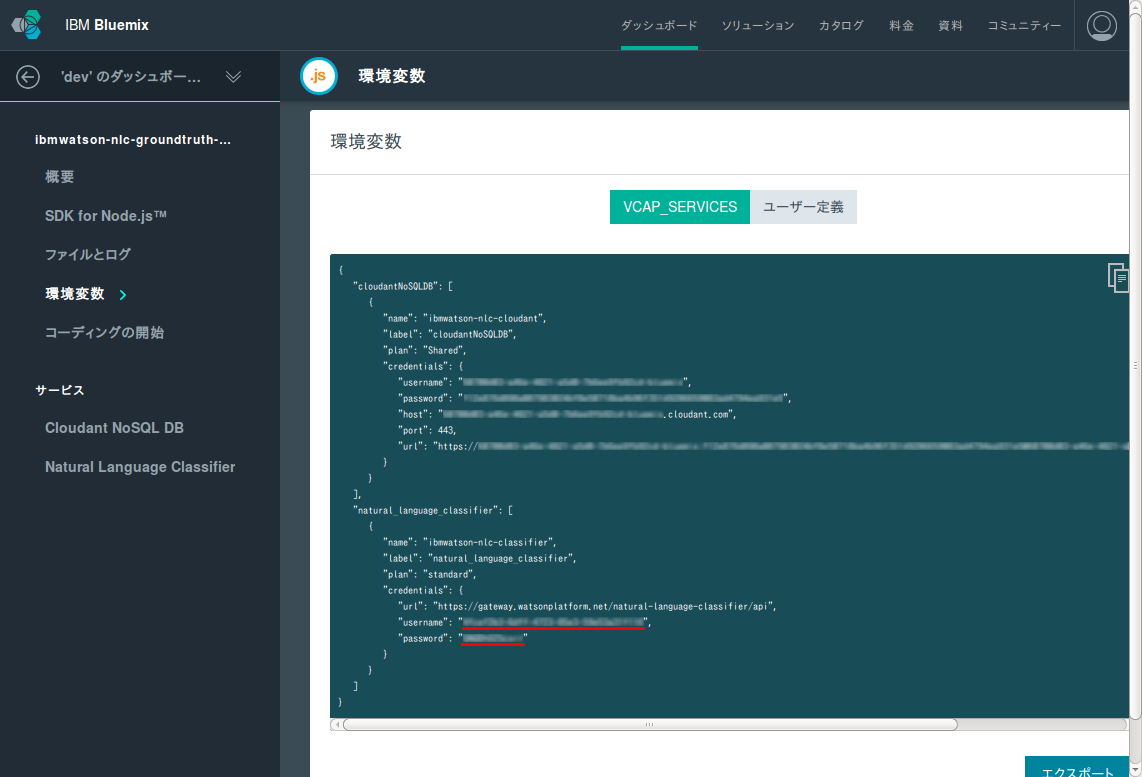
さて、Bluemixダッシュボードからユーザ名とパスワードを確認できたら、それらの情報を先ほどのログイン画面に入力します。
トレーニングデータのインポートと日本語での問題
無事にログインすることができたら、事前に準備したトレーニングデータ(CSV)をこのツールにインポートします。
- 右上の「Training」をクリックし、トレーニングタブにうつる
- 左上の「Import」をクリックし、トレーニングデータファイルを選択してデータのインポートを行う(まだトレーニングは行われていません)
ここで、右上の「Train」ボタンをクリックし、言語と分類器の名前(任意の名前)を指定すれば、トレーニングが行われるはずなのですが、残念ながら日本語のクラス名では次のようにエラーとなってしまいます。
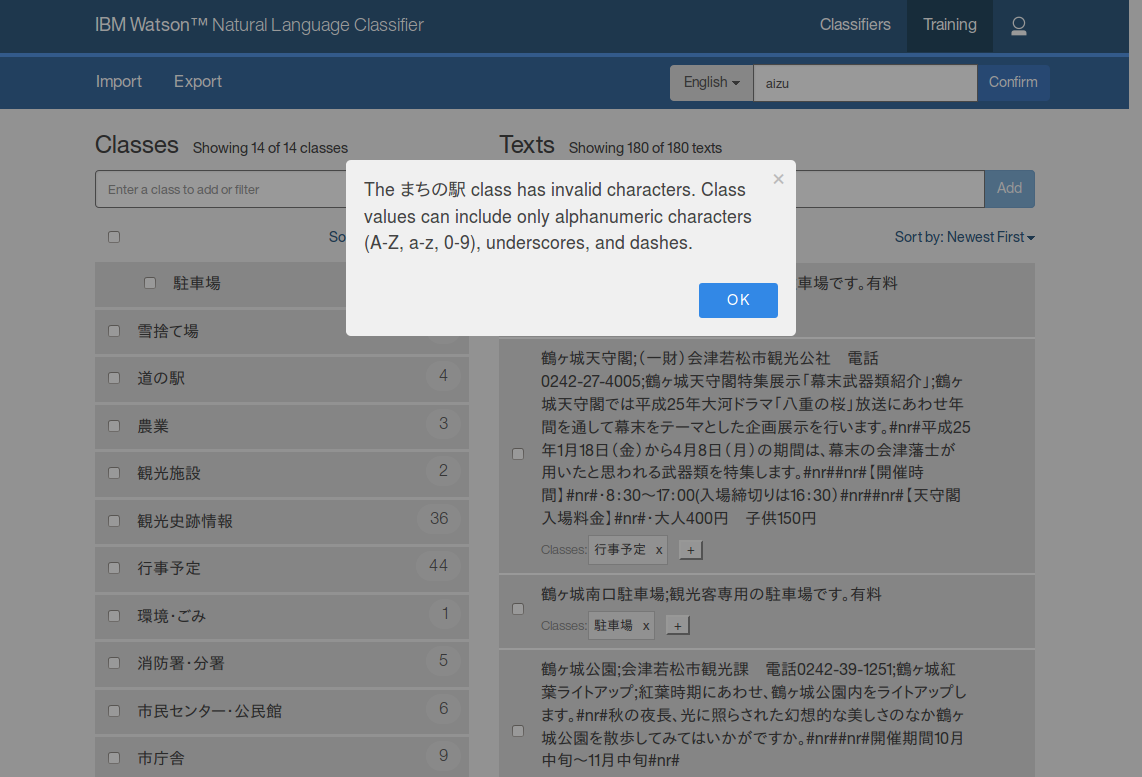
この問題は、NLC ToolkitがNLCの多言語対応に追随できておらず、クラス名が英数字等に限る、という以前の仕様のままである、ということに起因しています。
日本語対応のための修正と再デプロイ
それでは、ソースを修正して、前述の問題の原因となっている文字種類チェックを削除してしまいましょう。また、このエラーを解消した後に、実はもう1点問題が生じますので、それもついでに解決しておきます。
まず、Bluemixダッシュボードでアプリケーションの画面を開き、アプリケーション名のすぐ下にある「GIT URL」またはその横の「コードの編集」からIBM Bluemix DevOps Servicesに遷移します。
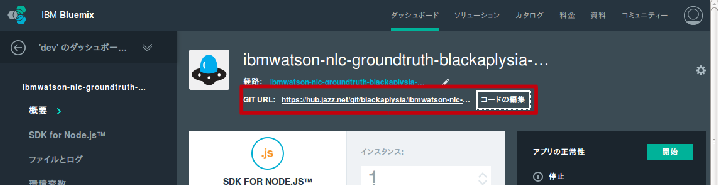
左側のファイルツリーで、client/app/training/training.controller.jsを開き、以下の2点を修正します。
- [修正1] 英数字チェックの削除
- [修正2] メタデータに埋め込む言語の種類を「en」から「ja」に変更
[修正1] 英数字チェックの削除
935〜945行目(2015/10/7現在)を削除します。以下の部分です。
- // if some invalid characters have been used, do not allow the training to go ahead.
- // Inform the user using a dialog box and closr the box when they confirm they have read it.
- for (i = 0; i < $scope.classes.length; i++) {
- if ($scope.numberTextsInClass($scope.classes[i]) > 0 && !$scope.classes[i].label.match('^[a-zA-Z0-9_-]*$')) {
- validationIssues++;
- msg = inform('The ' + $scope.classes[i].label + ' class has invalid characters. Class values can include only alphanumeric characters (A-Z, a-z, 0-9), underscores, and dashes.');
- ngDialog.open({template: msg, plain: true});
- return $q.when();
- }
- }
[修正2] メタデータに埋め込む言語の種類を「en」から「ja」に変更
トレーニングAPIに送るメタデータには言語指定がありますが、オリジナルは「en」(英語)固定であり、このままではAPIが日本語としてのトレーニングを行ってくれないようです。したがって、選択肢を「ja」(日本語)固定にします。(もちろん選択にすることも可能です)
270〜280行目(2015/10/7現在)が対象となります。
- { label: 'English', value: 'en' }//,
+ // { label: 'English', value: 'en' }//,
...
- // { label: 'Japanese', value: 'ja' },
+ { label: 'Japanese', value: 'ja' }//,
ビルドおよびデプロイ
ソースの修正後、以下の手順でコミットすると、DevOps Serviceが自動的にビルドとデプロイを行います。各手順が何を行っているかについての詳細はgitの書籍などを参照ください。
- git操作の画面を開く
- コミットメッセージを記入
- コミット実行
- リモートリポジトリにプッシュ
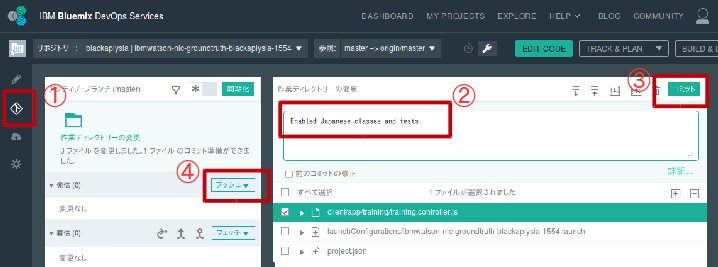
ビルドとデプロイの状況は、DevOps Serviceの「BUILD & DEPLOY」タブで確認できます。
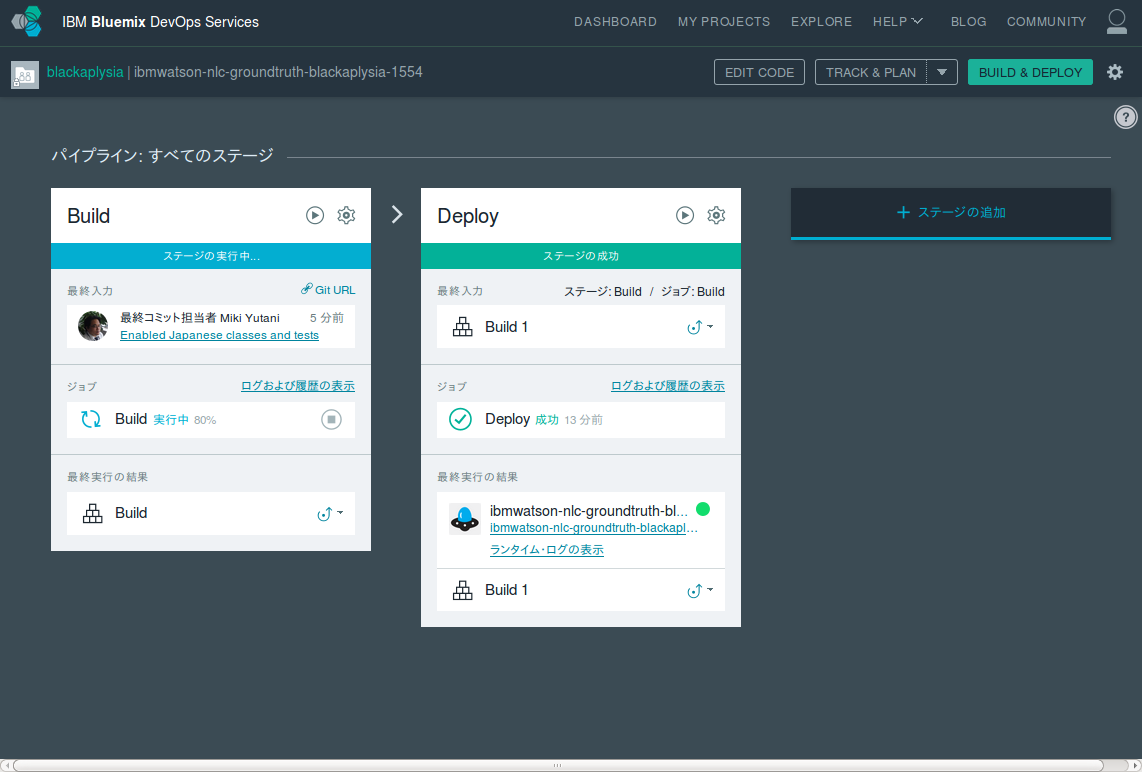
この画面で「Deploy」ステージが「成功」になるか、またはアプリケーションが再起動すれば修正は完了です。
トレーニング
ブラウザで再度アプリケーションを開き、トレーニングを開始すると、以下のように「Japanese」を選択できるようになっています。ここで分類器の名前を入力して「Confirm」ボタンをクリックします。

今度は無事にトレーニングを開始することができました。(タブが「Training」から「Classifiers」に移動していることに注意)
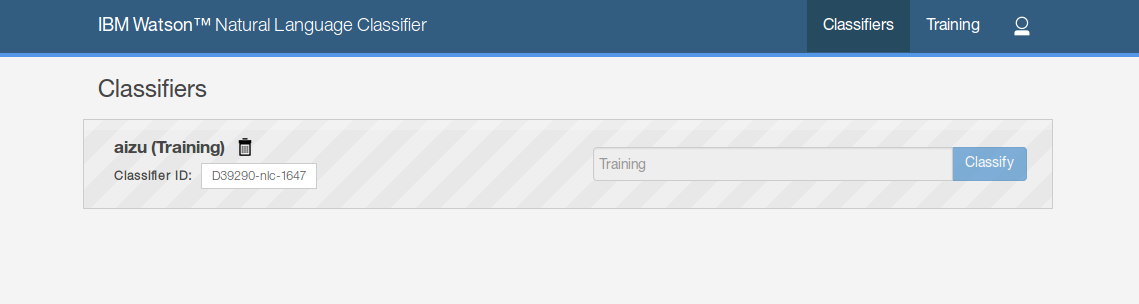
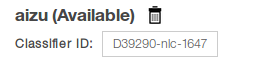
ステータスが「Training」から「Available」に変化すると、トレーニングは終了です。
分類器の使用
それでは実際に分類器を使用してみましょう。分類器名の右にあるテキストボックスに分類したいテキストを入れて「Classify」ボタンをクリックします。

少し待つと結果が返ってきます。
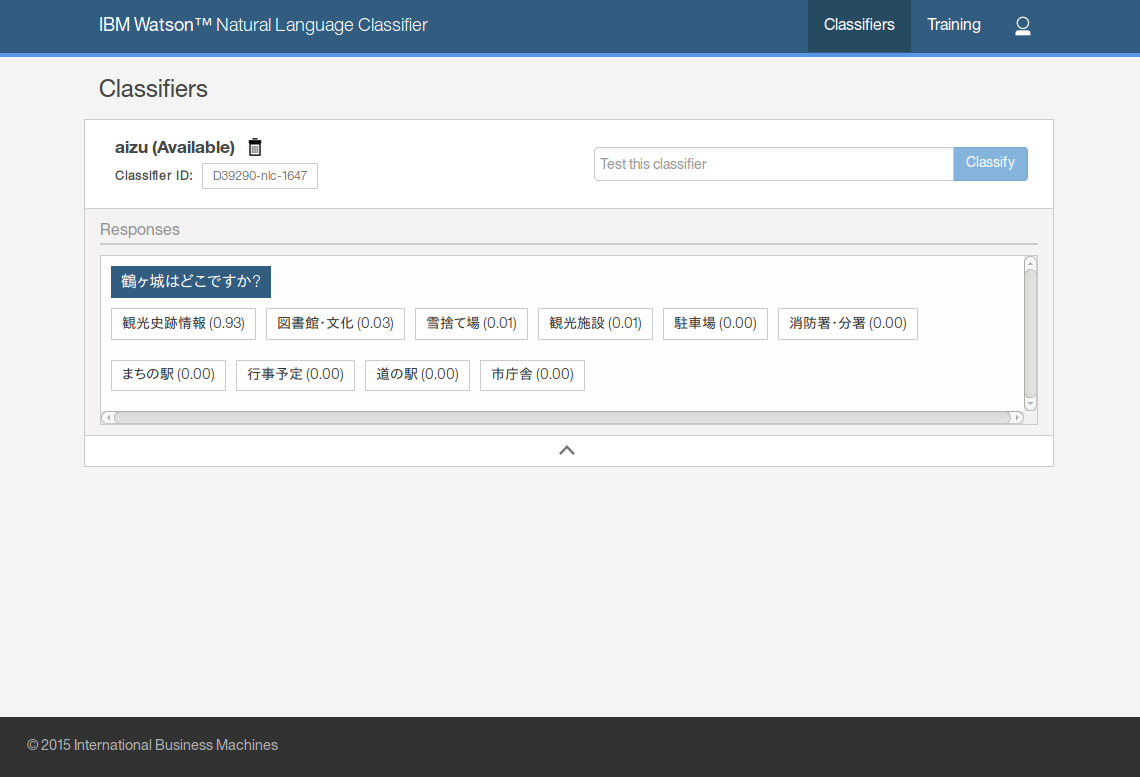
この例では、「鶴ヶ城はどこですか?」というテキストに対して、「観光史跡情報」という分類結果(確信度0.93)が返ってきました。
このタブでテキストを試しながら、結果が望ましくなければ、「Training」タブに戻ってトレーニングデータの追加削除を行ってチューニングし、さらにトレーニングを行う、という使い方になるようです。
まとめと考察
- NLC Toolkitは現時点で日本語対応していないが、少しの変更で対応することができた
- 前記事のようにcurlで実行するよりもGUIのほうがわかりやすい
- 簡単にトレーニングを行えるため、課金には要注意