はじめに
業務データやログ、さらにはストリームデータなど、多量のデータをRedisで扱うことかある。
私の場合、数億行✕数種類と、数千万行✕数百種類のデータが相手。
Redisの場合、条件に数千万行までのデータはハッシュ(HSET,HMSET)を使うことでアクセスもそこそこ高速でいてくれて、数億行になった後に応答速度とかRAM容量とかがかなり気になってくる感じ(そのため、データベースの分割を行ったり、それで混乱したり...)。
ということで、ここではRedisにたくさんのデータを突っ込んてあれこれ探す作業を効率化・高速化するためのTipsを備忘録としてまとめていく。
取り上げる予定は、
・ PostgreSQLのredisFDW(redisのデータをSQLのテーブルとして扱える) => 今回
・ Vedis(ネットワーク層を省いたredisリスペクトの軽量KVS)
・ [rediSQL] (https://github.com/RedBeardLab/rediSQL) (Redis module that provides a completely functional SQL database)
といったところ。
Redisの活用シーン
Redisというとsorted setによるリアルタイムランキングが有名なのだろう( こちらとか)。ここではそれ以外の使われ方を書いておく。
① バッチ処理:pipeでのデータ投入
redisはデータを高速に受け取るのは得意。
例えば、redisコマンド入りのテキストを作成し、
HSET mytable data1 123
HSET mytable data2 456
HSET mytable data3 789
... 延々と続く ...
クライアント(redis-cli)のpipeモードでデータを一括投入できる。
cat mydata.txt | redis-cli --pipe
※(私が普段使いしている環境のように)行の先頭に半角スペースを入れないとただしくデータ投入がなされない場合があることに注意。
参考 Redis Documentation日本語訳『大量データのインサート』
② ストリーム処理:キューイング
redisでは(リストと呼ばれる)キューイングに使いやすいpush/popの仕組みを持つ。
今のところストリーム処理はおこなっていないので、あまり試していないのだけれど、
Spark streamingやApache Flinkとの組み合わせていける模様。
このあたり、キューイングについてまとめてくれている以下の資料が参考になる(まとめが33枚目、40枚目)。
ストリーム処理を支えるキューイングシステムの選び方
気合を入れて使うのにはキューイングに特化したApache Kafkaがおすすめらしいけど、とりあえずredisで、という選択肢があるのはうれしい。
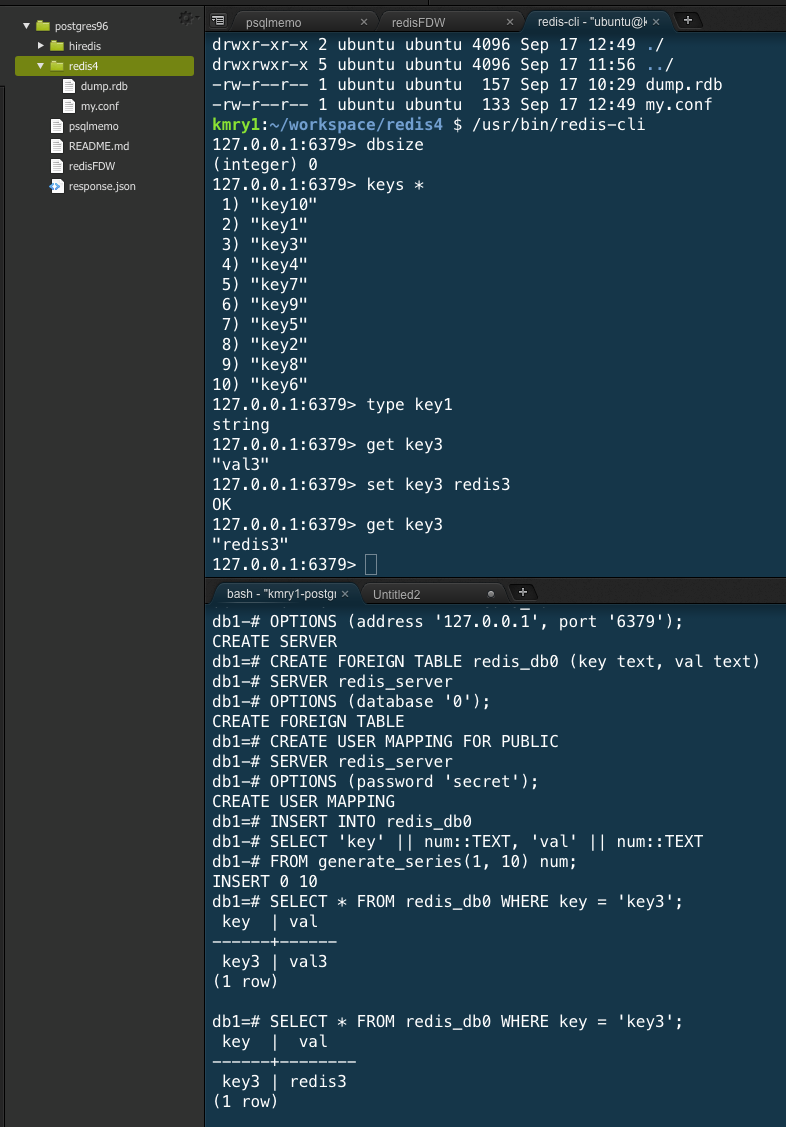
redisのハッシュをPostgresで扱う例
PostgreSQLのredis向けFDWを使ってうれしいのは、redisのハッシュに対しSQLでクエリをかけられることだろう。このアクセスは、最近のPostgresに入っているキーバリューストアhstoreを介して行われる。
そのため、はじめにpsqlでPostgreSQLに接続し、redis_fdw拡張に加え、hstore拡張を生成しておく必要がある。
CREATE EXTENSION redis_fdw;
CREATE EXTENSION hstore;
(redis_fdwのインストールと初期設定はこちらが参考になる。)
personから始まるキーを持つ以下のようなハッシュを登録した場合
HMSET person:id100 name Nicolson age 55
PostgreSQL側に対応するテーブルredisPersonを用意し、
CREATE FOREIGN TABLE
redisPerson (key text, value text[])
SERVER redis_server
OPTIONS (database '0', tabletype 'hash', tablekeyprefix 'person:')
;
以下のようなクエリで50歳以上の人を絞り込むことができる。
select * from
(select key,hstore(value) as value from redisPerson) as X
where cast(value->'age' as numeric) > 50
;
結果
key | value
--------------+----------------------------------------------
person:id100 | "age"=>"55", "name"=>"Nicolson"
SQLが得意な人にとっては、その知識を活かしつつ、PostgreSQL方言のhstoreをマスターするだけなので、 redis埋没データの発掘方法としては一番お手軽なのかと思う。
私は、redis_fdwを使えるようにするのに必要なスーパーユーザー権限の申請に気がひけて、業務では未活用。お試しした際のスクリーンショットを以下に貼っておく。
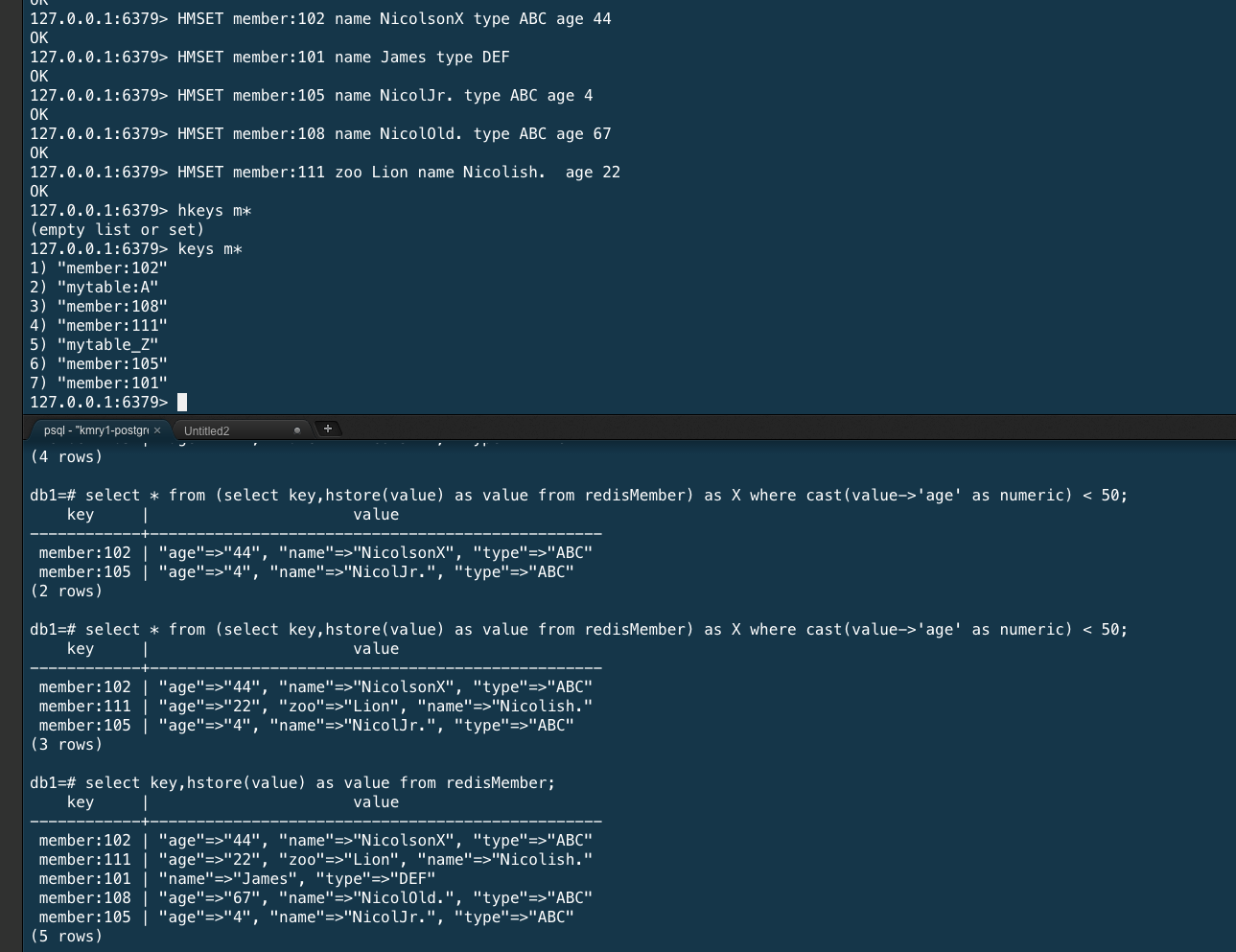
(参考)redis_fdwのインストール記
RedisのCクライアントライブラリとredis-fdwの両方が必要。
これらの導入は、PostgreSQLのバージョンやインストール状況に依存する。
必要条件は、 (おそらく)以下の通り
psqlにパスを通しておくこと
postgresql-server-devのインストール
PostgreSQLのバージョンに合わせたredis_fdwブランチを導入
Ubuntu(Cloud9)に導入したpostgresql9.6の場合、
PATH=/usr/usr/share/postgresql-common/:$PATH #最近のpostgresの場合
sudo apt-get install postgresql-server-dev-9.6
git checkout -b REL9_6_STABLE origin/REL9_6_STABLE
が必要だった。ここに至るまで、若干の試行錯誤が。。
web上の導入記を見てみても、皆それぞれの環境で試行錯誤しながら導入している模様。
以下のようにdockerを使ってredisデータ分析用のpostgresを導入するのが簡単かと思う。
(redisのデータをrdbファイルとして移動させることは簡単)
Docker で PostgreSQL の FDW を使って MySQL や Redis と JOIN してみた
関係ないけど、(私は趣味で使っている)cloud9はdocker環境にも導入できるので、両方扱えるようにしておくと、近い将来に、チーム開発の場面で約だったりするかもよ(=>近い将来の自分向けに)。