お疲れ様です。
株式会社アカツキでサーバエンジニアとして働いている申です。
はじめに
AWSを使用する上で失敗(ミス)した話と、それの原因及び対処方法などを共有し、みなさんは私と同じ過ちを起こさないようにすることが目的です。
Single-AZよりMulti-AZのほうが重い
概要
Single-AZとMulti-AZの両方性能テストする機会があり、Single-AZに比べてMulti-AZの方が性能が悪くていろいろ調べました。(特にコミット遅い)
原因
別AZ間でマスター・スレーブを配置するMulti-AZ構成では、AZ間で通信のレイテンシーが発生するためです。
Multi-AZのRDSにおいて、AZ間のデータレプリケーションは、非同期ではなく、 同期レプリケーション です。
よって、マスターDBに書き込み及びコミットが発生した場合、スレーブDBに書き込むための通信が発生し、それが完了するまで待つことになります。
対処
Single-AZを使用する
高可用性及びフェイルオーバーのため、AWSはMulti-AZをおすすめしていますが、
以下の理由でSingle-AZを選択することもありえるかと思います。
・性能優先
・コスト削減
・しばらく中断されても、すぐ対応できればいいサービス
EBSの最適化を提供する(PIOPS最適化)RDSインスタンスタイプを使用する
一般のEBSネットワークは他のトラフィックも使用する共存ネットワークです。そのため、高性能のIOPSを持っていても、他のネットワークトラフィックによりIOPSが影響され、IOPSが低下する場合があります。
EBSの最適化を提供しないRDSインスタンスタイプを使用する場合、他のトラフィック状況によって(例えば、マスターとスレーブ間で通信で)、IOPSも低下されることがあります。

EBSの最適化を提供するRDSインスタンスタイプで、専用のネットワークが確保ができ、プロビジョンドIOPSを最大まで引き上げることができます。
EBSの最適化を提供するRDSインスタンスタイプは、r3ですと、
r3.xlarge ~ r3.4xlargeまでです。r3.8xlargeは提供しません!
もし、他のネットワークトラフィックに影響されやすい環境だと、場合によってはr3.8xlargeの方がもっとIOPSが低いのでは?という疑問になりますが、これは後日ベンチマークしてみます。
新しくEC2をELBに登録した途端にOutOfServiceになってしまった話
概要
1個のAZで構成されているELBに新しくもう1個のAZを追加しました。
そのあと、新しいAZに1個のEC2を追加しましたが、追加したEC2が「InService」になったとたんに負荷が高まり、すぐ「OutOfService」になってしまったことがあります。
原因
デフォルトのクラシックELBは全てのEC2に均等に分散されるのではなく、 まず AZごとに均等に分散される ためです。
以下の画像をみてください。
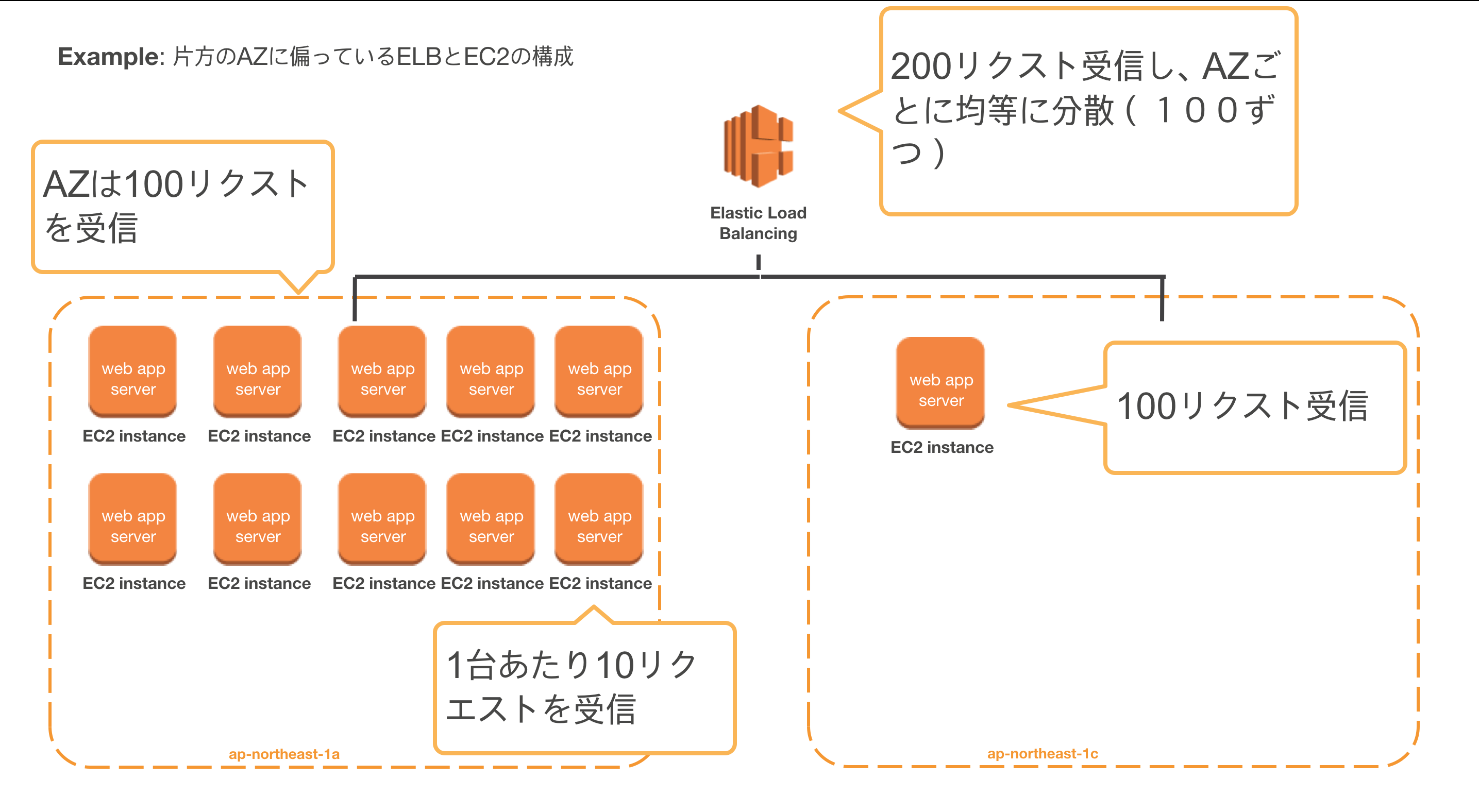
例えば、 ap-northeast-1a と ap-northeast-1c に跨っているELBがあるとします。そのELBにそれぞれ、10台、1台のEC2インスタンスが登録されています。
ELBに200のリクエストが来た場合、ELBには ap-northeast-1a と ap-northeast-1c に100リクエストずつ均等に分散されます。
そうしてしまった場合、 ap-northeast-1a の10台のEC2インスタンスは1台あたり10リクエストを受け付けますが、ap-northeast-1c の1台EC2インスタンスは100リクエストを一人で受け付けてしまいます。
対処
安定的に追加するためには、
・既存AZと同じ数のEC2を新しいAZに追加するか。
・「クロスゾーン負荷分散を有効化」する ※1
※1 「クロスゾーン負荷分散」を有効化することでAZごとではなくELBに登録されている全EC2ごとに分散されるようになります。
しかし、耐障害性を高めるために、できれば各AZに等しいEC2を分散配置するのがベストです。
AWSサービスはできるだけ新しい世代を使用する
新しい世代は以下のメリットがあります。
・コストが安い、性能がいい
・いいオプションがデフォルトで付いている ※1
※1 例えば、いいオプションは、EC2のC3世代にはなくて、C4世代にはデフォルトで付いているEBS最適化オプションなどになるでしょう。
RDSにおいて容量変更やスケールダウンするとたまに変更完了するまで時間がかかる話
概要
普段なら10分〜20分で終わるRDS容量変更がたまに3〜4時間かかったりする場合がありました。
メンテ作業を10分〜20分で見積もったのに、いざとなってメンテ入って変更を行うとなかなか終わらなくて汗かいたことがあります。
原因
いまだに原因不明です。
AWS側に、問い合わせしたい。
Redisのバックアップを取得したが、データが入っているはずのバックアップが0MBだった話
概要
Redisのバックアップ完了後、それを元に復元をしましたが、入っているはずのデータが空っぽでした。AWSマネジメントコンソルから、バックアップ容量をみたら、0MBでした。
翌日、再度バックアップされたデータ容量をみたら、1000MBになっていました。
原因
いまだに原因不明です。AWSの不具合?
AWS側に、問い合わせしたい。
教訓
バックアップをとったら、ちゃんと容量を見てから復元作業を行いましょう。
いろいろ、AWSって女心のように予測できないことがおおいため、丁寧に研究しながら、やさしく付き合っていきましょう。
以上、AWS失敗談でした。