はじめに
Webページから特定の要素を抽出してごにょごにょしたいときってよくありますよね。
(あるECサイトのある商品の在庫や価格を5分毎にウォッチしていたいとか、文書分類のために本文を正確に抽出したいだとか、などなど...)
そういう要素抽出をWebスクレイピングと呼んだりしますが、そんなときにもPythonは便利です。
ところでそういう目的ぴったりの、クローラー/スクレイピング Advent Calendar 2014というのがあって、以下の記事がよくまとまっています。(ちょっと前にその存在に気づいた)
http://orangain.hatenablog.com/entry/scraping-in-python
まずはやってみよう
前述の記事の最後にある通りPythonでスクレイピングするときにはrequestsとlxmlでだいたい事足ります。
pip install requests
pip install lxml
ではさっそくテレ朝ニュースの以下のページから本文部分を抽出してみます。
http://news.tv-asahi.co.jp/news_politics/articles/000041338.html
まずページの構成がどのようになっているかを確かめます。Chromeだと下のように標準でDeveloper Toolsというのがあって(FirefoxだとFirebugとか)、それを起動したら虫眼鏡アイコンをクリックして抽出したい部分にマウスカーソルを持って行くと簡単に目的要素あたりがどのようなページ構造になっているかわかります。
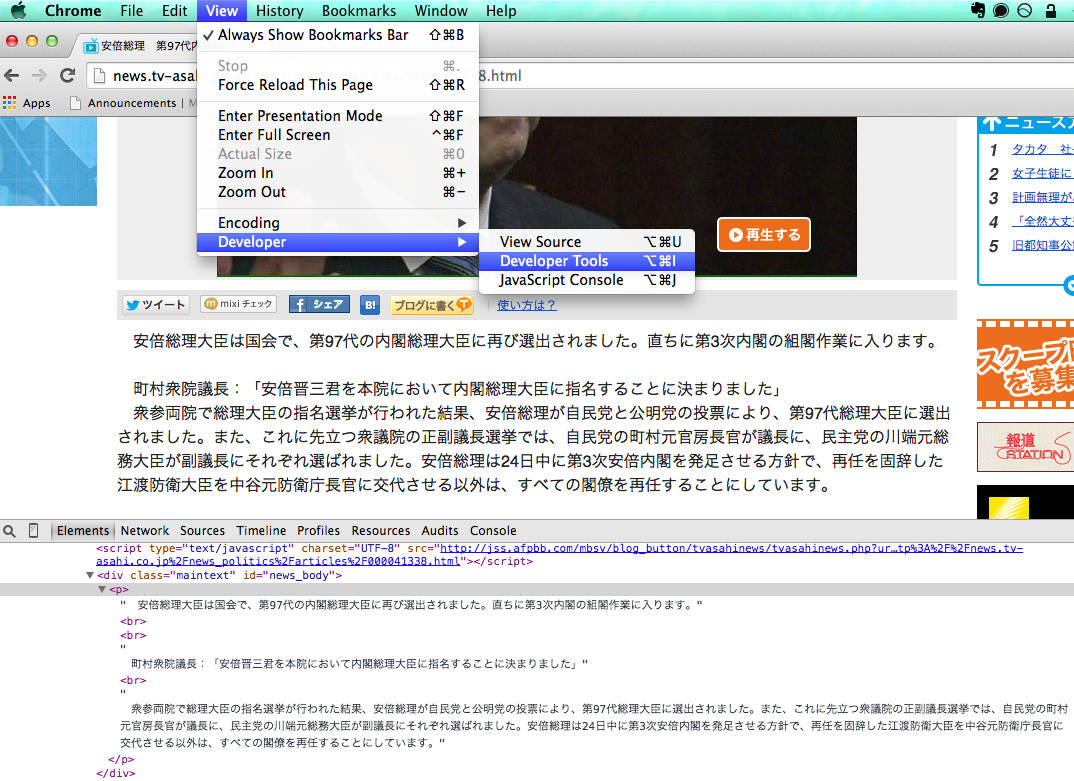
<div class="maintext" id="news_body">タグの下の<p>タグのさらにその下に目的の文章があることがわかります。
この場所はCSSセレクタを用いて#news_body > pと表現することができるので、最終的にこの部分のテキストを抽出するスクレイピングコードは次のように書けます。
cf. CSSセレクタのまとめ
http://weboook.blog22.fc2.com/blog-entry-268.html
import lxml.html
import requests
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
target_html = requests.get(target_url).text
root = lxml.html.fromstring(target_html)
# text_content()メソッドはそのタグ以下にあるすべてのテキストを取得する
root.cssselect('#news_body > p').text_content()
もしImportError: cssselect seems not to be installed.
とか怒られたらpip install cssselectでおうけいです。
この通りすごく簡単なことがわかると思います。
JavaScriptを読み込む
次にちょっとやっかいなのがJavaScriptでレンダリングされている部分です。
先ほどのようにDeveloper Toolsで見てみると、同じようにとれるんじゃないかと思いますが実はこれJavaScriptを読み込んでレンダリングされた結果なんですね。
JavaScriptを読み込む以前のhtmlは単純にこうなっています。
<!-- 関連ニュース -->
<div id="relatedNews"></div>
なのでrequestsで取得したhtmlをそのまま解析しようとしてもうまくいきません。
そこでseleniumとPhantomJSの出番です。
pip install seleniumしてPhantomJSをこのあたりを参考にインストールしておきます。
そうしたらJavaScriptを読み込むバージョンはこんな感じです。
selenium&PhantomJSを通してhtmlを取得したら後の流れは同じです。
import lxml.html
from selenium import webdriver
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
driver = webdriver.PhantomJS()
driver.get(target_url)
root = lxml.html.fromstring(driver.page_source)
links = root.cssselect('#relatedNews a')
for link in links:
print link.text
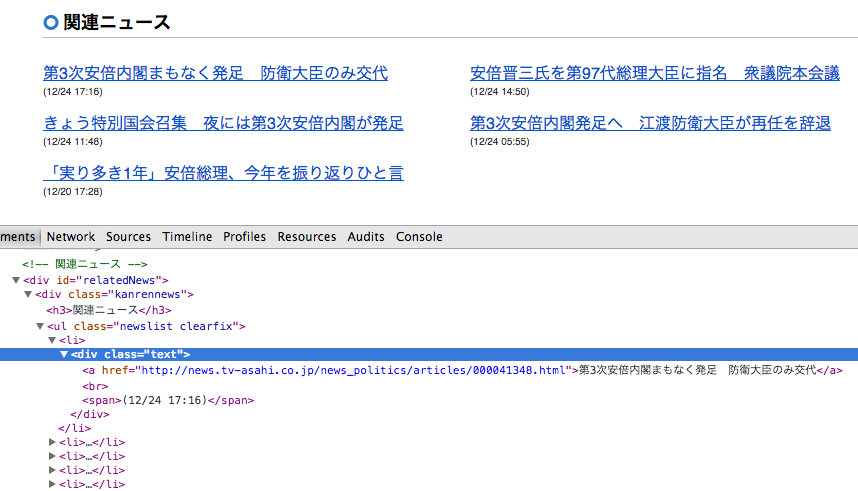
実行結果
第3次安倍内閣まもなく発足 防衛大臣のみ交代
安倍晋三氏を第97代総理大臣に指名 衆議院本会議
きょう特別国会召集 夜には第3次安倍内閣が発足
第3次安倍内閣発足へ 江渡防衛大臣が再任を辞退
「実り多き1年」安倍総理、今年を振り返りひと言
まとめ
以上のように通常のhtmlページだけでなく、JavaScriptによるレンダリングが入っているページでもさくっと簡単にスクレイピングすることができました。
実際にいろんなサイトをスクレイピングしてみると文字コードの問題で頭を悩ませたりすることもよくありますが、Webスクレイピングができるといろんな作業を自動化したりすることができたりするので、さまざまな場面で個人的には役立っています。
それではみなさまも良いクリマスとWebスクレイピングライフを。