本記事は Livesense Advent Calendar 2016 - Qiita の24日目の記事になります。
公開から1年ほどたち、当初はRESTの次の潮流か!?みたいな感じになったものの、イマイチ盛り上がってる気配のないGraphQL。
ただ、気になっていた技術だったので、気にせず2016年が終わる前にざっと調べてみました。
ここ2日ほどでざっと調べたもののまとめなので、理解や解釈に誤りや言ってる意味がわからないところがあればご指摘いただければ幸いです。
TL;DR
内容をコンパクトにしきれず(Queryにばかり集中して、Mutationについては全然触れてないのに!)かなり長くなってしまいました。実際は、
GraphQL | A query language for your API のTOPページを読んで雰囲気を掴み、
The GitHub GraphQL API | GitHub Engineering でGraphQLが必要とされる背景に思いを馳せ、
Introduction to GraphQL | GraphQL でもう少し詳しく知り、
Getting Started With GraphQL.js | GraphQL.js Tutorial に従って簡単に動かしてみて、
GraphQL Relay Specification - Relay Docs に一歩踏み込んで?が出てきたら、
GitHub GraphQL API | GitHub Developer Guide で実際のAPIを眺めてみると、
なんとなく理解できると思いますので、この記事を読まずにそっちで済ますほうが確実な理解につながるとは思います。
と言ってしまうと記事としてあれなので、英語のブログやドキュメントを読むのが辛い人のために一応以下つらつらとまとめます。
まずは雰囲気を掴む
GithubがGraphQLのAPIを提供して(現時点ではEarly Access)いるので、それを例に説明をしていこうと思います。
以下は「GraphQLという名前を含むリポジトリを検索して、該当するリポジトリの数を取得する」というクエリです。
query {
search(query: "GraphQL", type: REPOSITORY) {
repositoryCount
}
}
この結果として、以下のようなJSONが返ってきました。
{
"data": {
"search": {
"repositoryCount": 2955
}
}
}
もう一つ別の例を見てみましょう。
以下は「bananaumaiというログインIDのユーザーを取得して名前を取得する」というクエリです。
query {
user(login: "bananaumai") {
name
}
}
この結果としては以下の様なJSONが返ってきます。
{
"data": {
"user": {
"name": "YUTA Shimakawa"
}
}
}
以下のような形でHTTPのPOSTリクエストにのせてクエリーを投げています。 1
$ curl -H "Authorization: bearer <<your access token>>" -X POST -d '
{
"query": "query { user(login: \"bananaumai\") { name }}"
}
' https://api.github.com/graphql
GraphQLを何故使うのか?
GitHubのエンジニアブログ を読むと、彼らがRESTfulなWEB APIを拡張していく中で、だんだん辛みが出てきて、新しいパラダイムを模索してたところ、GraphQLに出会い、現在Early Access版で情報を提供しているようです。で、GithubがGraphQLを選んだ理由として以下のような内容が紹介されています。
- クライアントサイドである画面を描画しようとすると、複数回のHTTPリクエストを発行しなければならないという課題があった。
- その他、例えば、以下のようなAPIに関する細かな改善欲求があった。
- 各APIエンドポイントに必要とされるOauthのスコープを集めたい。
- コレクション系のリソースのページネーションをもっとスマートに行えるようにしたい。
- ユーザーが投げてくるAPIリクエストのパラメーターを型安全に扱えるようにしたい。
- APIの実装コードからドキュメントを生成したい
- クライアントコードを自動生成したい。
- etc
上のような課題がGraphQLでどのように解決されるのか以下で見ていければと思います。
GraphQLの特徴
Schema(APIの定義)の存在と問合わせ言語仕様がセットになっている
GraphQLにはSchemaが存在しており、それによって型システムに基づいたAPIの構築が可能になります。
例えば、お店の一覧をただ返すだけの単純なGraphQL APIのSchemaを考えてみます。
schema {
type Shop {
id: ID!
name: String!
}
type Query {
shops: [Shop]!
}
}
typeキーワードは型の宣言です。
type Shop {...}でShopというオブジェクト型を定義しています。その中にある"name"というキーワードはフィールドと呼ばれており(JavaScriptと一緒ですね)、コロンの後ろに続く"String"でそのフィールドの型がStringの値であることを示しています。!はNot Nullの指定キーワードです。オブジェクト型には任意の数のフィールドを設定できます。idというフィールドはID型という重複のない一意性の保証された特殊な文字列です。ここでは詳しく触れませんので、必要であれば http://graphql.org/learn/schema/#scalar-types あたりを参照してみてください。
次にQueryという型が定義されています。Queryはshopsという[Shop]型のフィールドを持っています。これはShop型のリストであることを示しています。また、Queryという型はGraphQL Schemaにおいて特別な意味を持っており、Query Typeに指定されたフィールドがAPIのトップレベル(root)のクエリー用インターフェースになります。つまり、上記のようにQueryに1つのフィールドしか存在しない場合、以下のような問い合わせだけしかできないことになります。
query {
shops {
id,
name
}
}
以下、返却値の例。
{
"data" : {
[
{id: "1B814046-86C1-43E7-BE77-443B8F3319C9", "name": "バナナ屋"},
{id: "C0C62859-C5D8-4BFD-B2BB-93574C4B2921", "name": "りんご屋"},
{id: "A5640770-E9B8-4532-AF39-B027BC79A19F", "name": "みかん屋"}
]
}
}
また、もしもREST APIでShopリソースを表現するとしたら、nameとidの両方を返すのが普通だと思いますが、GraphQLでは以下のようにShop.nameだけを取得することも可能です。
query {
shops {
name
}
}
{
"data" : {
[
{"name": "バナナ屋"},
{"name": "りんご屋"},
{"name": "みかん屋"}
]
}
}
次に、このAPIをもう少し拡張してみます。
以下のように引数付きフィールドを定義することも可能です。
schema {
type Shop {...}
type Query {
shops: [Shop]!
shop(name: String): Shop
}
}
このようなAPIが提供されている場合、以下のようなクエリが可能になります。
query {
shop(name: "バナナ屋") {
name
}
}
結果は以下のようになります。
{
"data" : {
"name": "バナナ屋"
}
}
データ操作に関してのAPIも定義することができます。
schema {
type Shop {...}
type Query {...}
type Mutation {
addShop(shop: ShopInput): Shop
updateShop(id: ID!, shop): ShopInput
}
input ShopInput {
name: Name
}
}
Mutationという型を指定して、そのフィールドとしてデータ操作用のAPIを定義します。また、inputというキーワードはmutation時に利用するデータを保持するためのデータを定義するものです。この定義の元以下のようにデータ更新を行います。
mutation {
addShop({ name: "いちご屋" }) {
id
}
}
データ追加に成功した場合以下のようなデータが返ります。
{
"data": {
"addShop": {
"id": "592AC8B4-76A3-417F-B193-97114ECF9CBE"
}
}
}
Schemaの存在によって、クエリに対しての型レベルの検証ができる
上述したように、Schemaによって型レベルでクエリの妥当性を検証することができます。
例えば、GraphiQLというGraphQLのGUIクライアントでは、Query Editor内での不正な引数やフィールドの指定が検知され、ハイライトされます。おそらく(ちゃんとソース見てないけど)、GraphQLの仕様上、Schema情報などのメタ情報にアクセスするためのAPIが定義されており、この情報をひいてクライアントがSchemaを検査し、型のチェックをしているのだと思います。
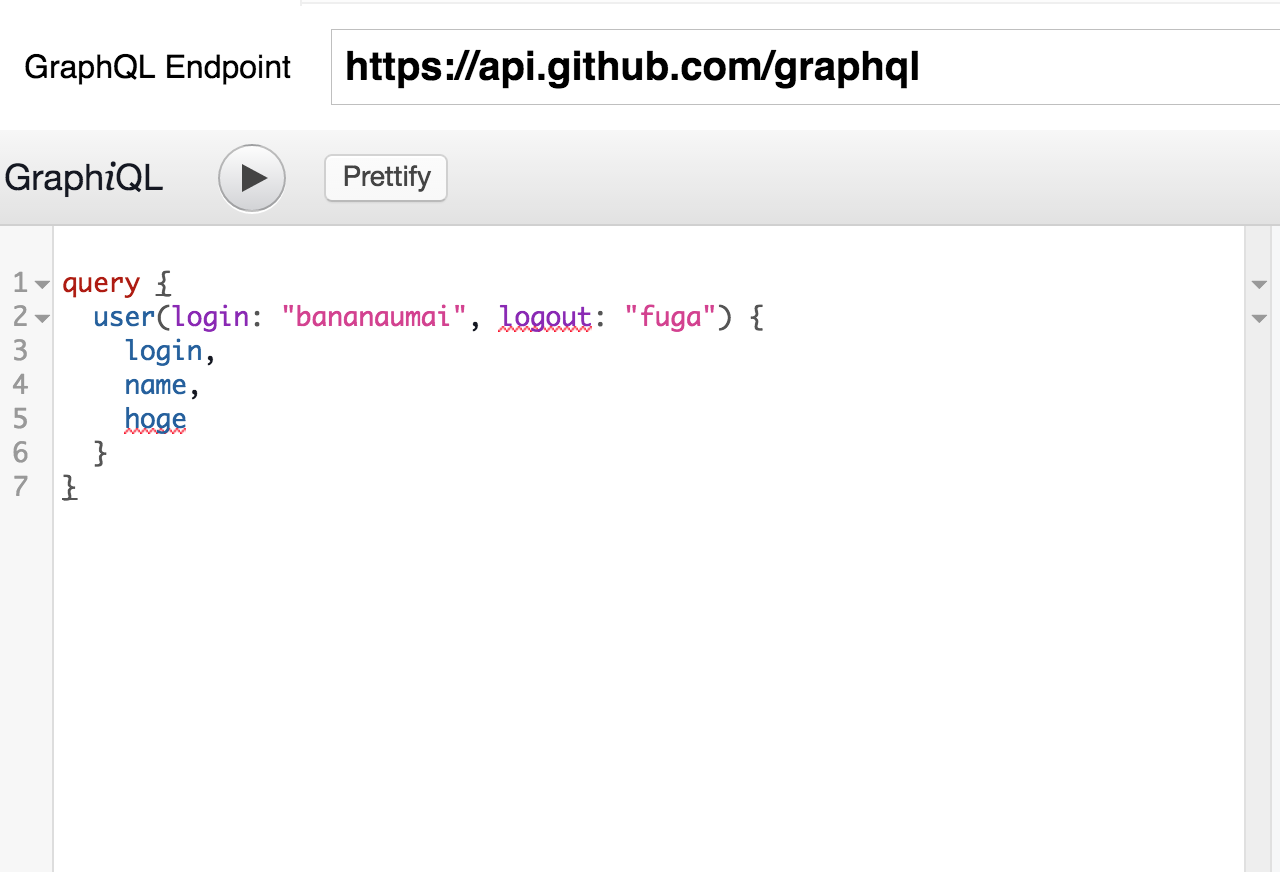
ここではこれ以上触れませんが、より詳しくは知りたい方は http://graphql.org/learn/validation/ を参照してみて下さい。
オブジェクトグラフをSchemaで表現できる
前述しましたがGraphQL Schemaにおいて、ユーザーが独自の型を定義でき、またその型情報は別の型定義に利用できます。そのため直接的にオブジェクトの関係性(グラフ)をAPIとして表現できるようになっていると思います。
例えば、先程のお店だけのリストを返すGraphQL APIを少し拡張して以下のようなモデルを扱うAPIを考えてみたいと思います。
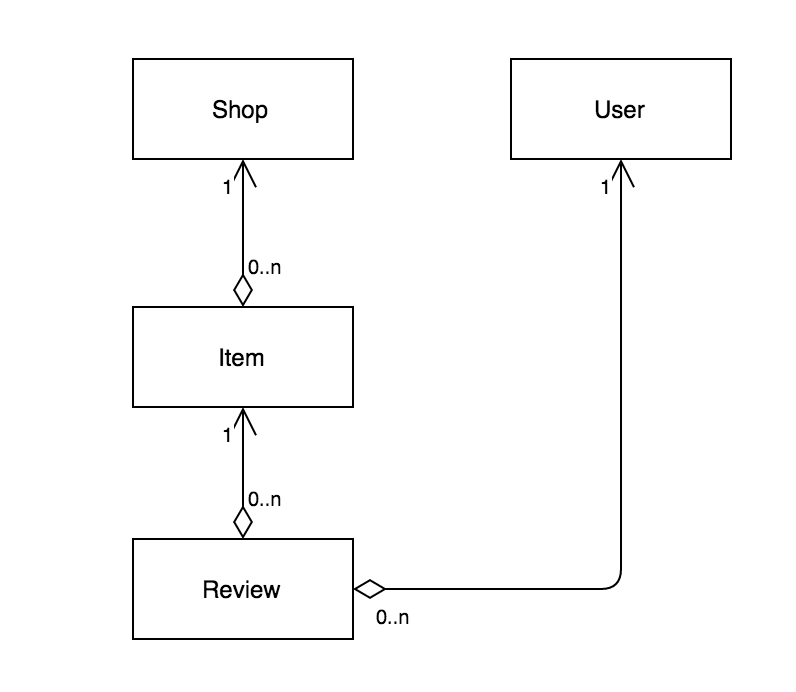
このようなモデルをもう少し考えてみると以下のようになります(単純化のためここではデータ操作系のAPIや関係性にかかわらないフィールドについては省略しています)。
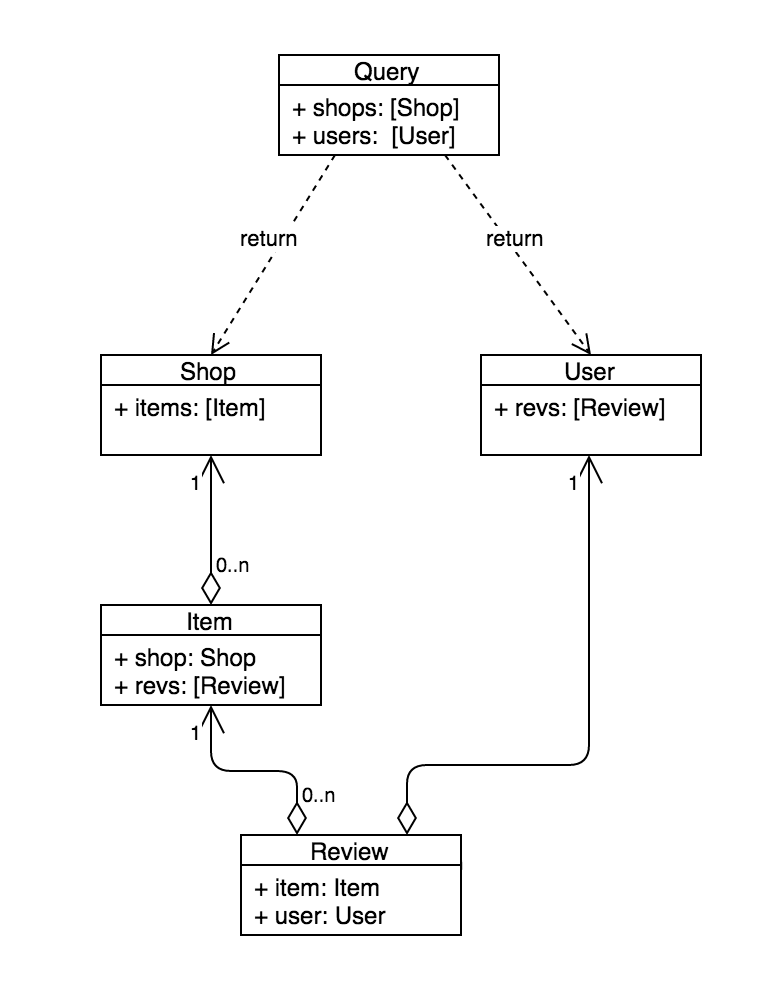
これをGraphQLに落とし込むと以下のようなSchemaになります。
type Shop {
id: ID!
name: String!
items: [Item]
}
type Item {
id: ID!
name: String!
shop: Shop
revs: [Review]
}
type User {
id: ID!
name: String!
revs: [Review]
}
type Review {
id: ID!
content: String!
item: Item
user: User
}
type Query {
shop(name: String): Shop
user(name: String): User
item(id: ID): Item
}
このようなSchemaに対しては、こんなクエリが発行可能です。
query {
shop("バナナ屋"): {
name,
items: {
id,
name,
revs: {
content
}
}
}
}
{
"data": {
"name": "バナナ屋",
"items": [
"id": "DF9B698A-A70E-4DC0-989A-8003A8168E11"
"name": "甘熟王"
"revs": [
{"content": "うまい!"},
{"content": "甘い!"},
{"content": "楽しい!"}
]
]
}
}
一方で、Queryにitemのフィールドが定義されているのでこのようなデータの引き方も可能です。
query {
item("DF9B698A-A70E-4DC0-989A-8003A8168E11"): {
name,
revs: {
content
}
shop: {
name
}
}
}
{
"data": {
"name": "甘熟王",
"revs": [
{"content": "うまい!"},
{"content": "甘い!"},
{"content": "楽しい!"}
],
"shop": {
"name": "バナナ屋"
}
}
オンメモリでのオブジェクトの扱い方に似ている気もします。
インターフェースを定義できる
さらに、GraphQLのschemaではインターフェースも定義できます。
JavaとかPHPのあれと一緒です。以下のように使います。
interface Node {
id: ID!
}
type Shop implements Node {
id: ID!,
name: String!
items: [Item]
}
type Item implements Node {
id: ID!
name: String!
revs: [Review]
}
:
Java等と同様にあるInterfaceをimplementする場合には、Interfaceに定義されているフィールドを実装する必要があります。これによって云々、というへんはまぁここで語らなくても良いかと思いますので、割愛します。
GraphQL自体はあくまで問い合わせ言語の仕様
GraphQLはあくまでオブジェクトデータに対してのクエリ/操作のインターフェース仕様であり、GraphQLという名前のデータベース製品やアプリケーションサーバーがあるわけではありません。SQLが具体的な製品ではなく、RDBMS等のデータベースの問い合わせ言語として利用されているのと同様です。GraphQLが扱うデータのストレージが何であるのか、という点についても特に制限があるわけではありません。GraphQLの詳細な仕様は GraphQL にて公開されています。
GraphQLのサーバーを実装するためのライブラリが様々な言語で実装されており Code | GraphQL にて確認することができます。ここに載っていないものも結構あるようです。ライブラリによってどのくらいのことまでできるようにサポートしているかは異なるのでしょうが、おそらく、クエリの字句解析/構文解析や、後述するSchemaに基づく検証等のGraphQLの仕様に関する実装 + ユーティリティといったところが提供されていると思います。ただ、問い合わせの実装やデータストアに関しては基本的にはこれらのライブラリの範疇外なので、この辺は実装者が自ら設計/実装する必要があります。
ですので、これまでschemaだけ定義しながら、「こういうクエリを書くと」「こういうデータが返ります」はあくまで期待値でしかなく、その実装が必要ということです。実装についての入門としては Getting Started With GraphQL.js | GraphQL.js Tutorial この辺を参考にされると良いかと思います。
その他
1枚の記事ではGraphQLの特徴のすべては網羅しきれないのでその他の特徴や詳細については公式ページを参照していただくのが良いかと思います。
Introduction to GraphQL | GraphQL
より実践的な使い方
前章で例に出したShop - Item - Review - UserのGraphAPIは現実には使えません。というのも、Shopに紐づくItemや、Itemに紐づくReviewの数が何件かわからないからです。そのような状況で、オブジェクトグラフをすべて解決するみたいなことをすれば、ネットワーク帯域を埋め尽くしたり、あっという間にサーバーのリソースを食い尽くしてしまいそうですね。
この点を考慮しなくてよいのであれば、上のオブジェクトグラフをREST APIで表現しても良いのですが、ここがまさに問題になる箇所だと思います。RESTfulなAPIの場合、現実的には、Shopリソースのレスポンスの中には、Shopに紐づくItemリソースのidやリソースのURIを入れるような形になるかと思います。
RelayのためのGraphQLの仕様
で、この点をGraphQLがどう解決するのか気になるところです。が、GraphQLの言語仕様自体はこの点に対して特にノータッチ。なので、この辺の工夫をどうやるんだろうな〜と考えていたのですが、そんな時に GraphQL Relay Specification | Relay Docs を読んで、なるほどとなりました。
RelayはGraphQLの生みの親であるFacebookが作ったReactのためのデータアクセスフレームワークで、GraphQLサーバーをバックエンドとして作られています。Relayのドキュメントの中で上記のように「Relayが想定するGraphQLサーバーの満たすべき仕様」が定義されています。これを読んでみると、Relayに特化したGraphQLのサブセット要件が書かれています。このドキュメントによれば、RelayのためのGraphQLは以下の要件を満たす必要があるとのことです(大分意訳しています)。
- オブジェクトを識別子、確実に同一オブジェクトを再取得できるようにするためのユニークID
- コレクションデータのページネーションに関する情報を表現するための「コネクション」という仕組み
- 予測可能なオブジェクトの変更を可能にする仕組み
これだけ見るとはっきり行ってなんのこっちゃよくわからないかと思います。ので、次項でもう少し詳しく見ていきます。ただ、私自身が、ミューテーション周りの考えをうまく整理できていないので、1、2のオブジェクトの識別とコレクションデータのページネーションについてのみ説明したいと思います。
オブジェクトの識別
これは既に出たIDによって担保されるものです。実装上もGraphAPIが扱うデータは確実にIDが着く必要があります。DDDにも出てくるオブジェクトの同一性の話ですね。これを実現するには、バックエンドがRDBであれば、オブジェクトをあらわすエンティティーのテーブルにユニークキーを設けるとか、別の形であればUUIDのような重複のないIDを生成する仕組みが必要になります。が、この点に関しては概念的にはあまり難しくないかと思います。
コレクションデータのページネーションをどう扱うか。
上ではコネクションという概念が説明されていましたが、これがなんだかわかりづらいな〜と思っていました。が、上記のドキュメントを一通り呼んだ後にGithubのGraphQL APIを眺めてみるとイメージがわきました(おそらく、GithubのAPIもGraphQL Relay Specificationを意識して作られていると思われます)ので、以下読んでも意味分からないという方におかれましては、GithubのGraphQL APIのドキュメントを読んでみることをオススメします。
さて、Relay GraphQLではページネーションを実現するために、ConnectionとEdgeという2つのインターフェースを用いています2。
GraphQL Schemaで表現すると以下のような感じです。
interface Connection {
pageInfo: PageInfo
edges: [Edge]
}
interface Edge {
cursor: String
node: Node!
}
interface Node {
id: ID!
}
type PageInfo {
startCursor: String
endCursor: String
hasNextPage: Boolean!
hasPreviousPage: Boolean!
}
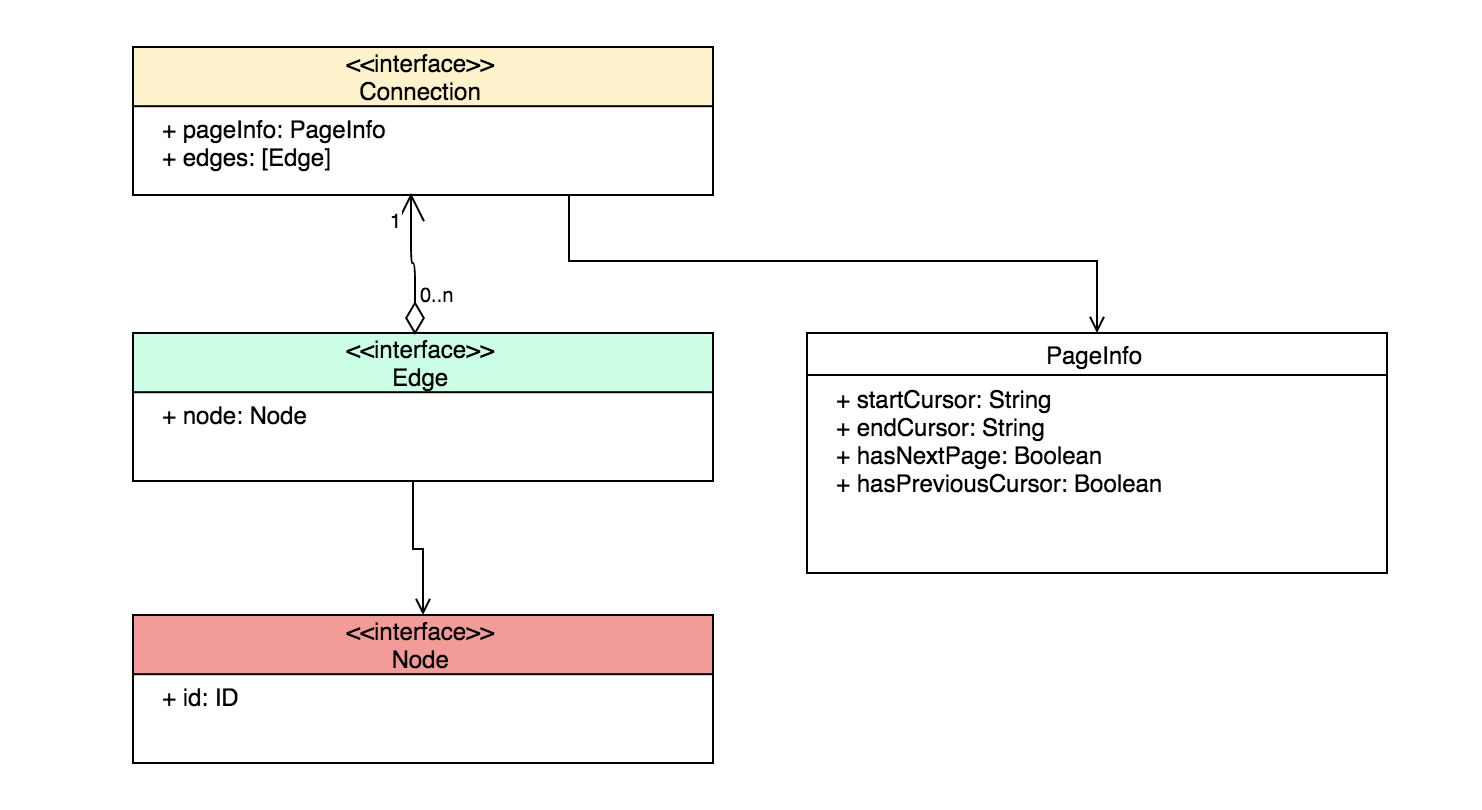
これをもう少し概念的な図で表すと以下のような感じ。
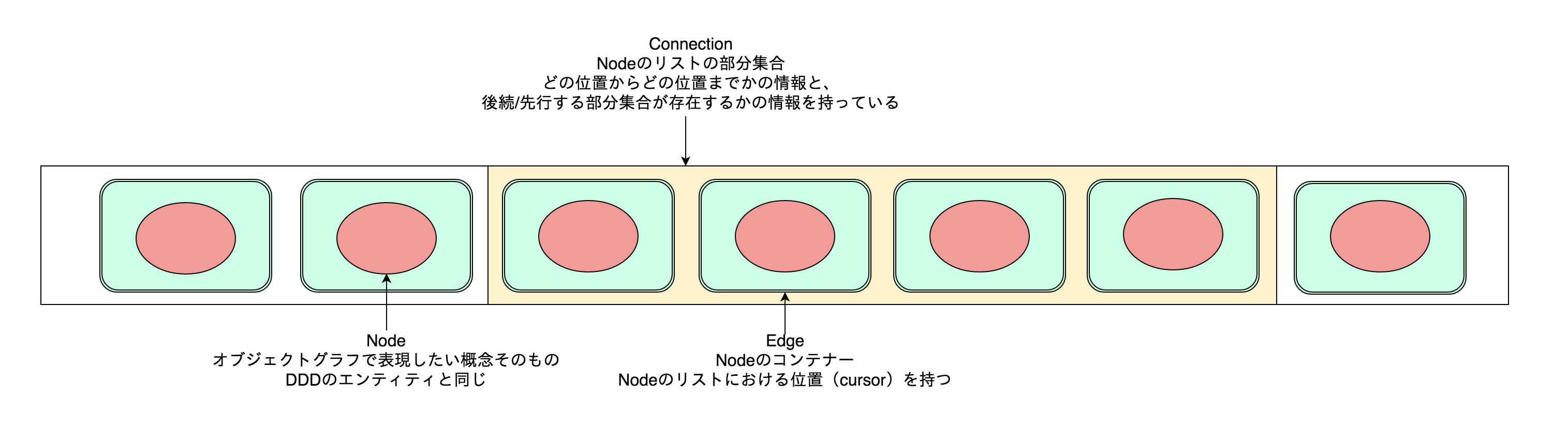
Nodeはオブジェクトグラフの中で本来表現したい概念。多分DDDを読んだことのある方ならピンと来ると思うが、Relay GraphQLでNodeをインプリメントする型になるようなデータはDDDでいうところのエンティティにあたると思います。
一方、実際の世界をシステムで表現すると、エンティティが別のエンティティを不定の数持つことになるのですが、それをGraphQLというシステムの中で取り入れたのが、EdgeとNodeという仕組みだと思われます。EdgeはNodeを格納するリストの中で、番号付きの箱のような役割をしています。ConnectionはNodeのリストをサブリストに小分けにしながら取り出すためのスポットライトのような仕組みと考えるのが良いのではないかと思います(なんだかこの比喩も意味不明かも)。
概念はここまでにして、実際に、GithubのAPIを見てみましょう。
例えば、「livesnse-incというオーガニゼーションが持っている、public repositoryの名前を知りたい」という場合には以下のようなクエリーを投げます。

上の概念図のような関係になっていることがわかると思います。
ここでOraganizationのrepositoriesフィールドにはfirst | lastというInt型の引数を指定する必要があります。これは、取得するConnectionの中にいくつのEdgeを含むかという情報になります。また、上のキャプチャにはのっていませんが、afterという引数も指定可能で、これは特定のcursorのIDを指定すると、そのcursor移行のn個のEdgeを取得することができるようになっています。このようなconnectionに対してのアクセスのインターフェースはすべて共通になっており、必ずオブジェクトの集合に対してはConnectionとEdgeを挟んでアクセスされるように設計されています。
以上のような工夫により、RESTfulなAPIで入れ子のデータすべて引き抜いてしまうとデータ量が膨大になってしまうというような問題を回避しつつ、オブジェクトグラフの特定のNodeから、必要な深さで必要な情報に対して、1回のクエリでアクセスできるようになっています。しかも、おそらくGraphQLのクエリー言語仕様自体には特に変更はいらず、その仕組みの範囲内で、EdgeとConnectionという概念的なオーバーヘッドというか型を作ることでとても柔軟なAPIができるようになっているのでとても感動しました(小並感)。ConnectionとかEdgeをすべてのオブジェクトに実装するのはだるそうだなと思ったのですが、これも、graphql/graphql-relay-js: A library to help construct a graphql-js というGraphQLの拡張ライブラリのユーティリティでこの辺のボイラープレートを扱ってくれるっぽいので素敵だと思います。
終わりに
本記事ではあまりMutationや実装について触れられませんでしたので、別の記事でその辺も後日まとめられたらなと思います。
長くなってしまいましたが、ちょっとでもGraphQLに興味を持って頂けたら幸いです(別に回し者ではないですが)。
追記:
ReactとApolloを使ってGithub GraphQL APIを試してみる にGraphQLクライントのサンプルコードとその解説を作りましたのでご興味ある方は覗いてみてください。