少し前まではすこぶる使いづらかった。。
というか、ただAPIが提供されて、「自分でJavaとか組んで叩いてね」「グラフの絵を書くのも自分で頑張れ」くらいだったのが、
GAしたおかげか、やさしいUIで、グラフDBをこれから始めてみよう!という気になれる(ように見える)。
カタログからIBM Graphのサービスを作成
・いつもどおり、bluemixの画面から。

・できると以下のような画面が出てくるので、「Open」で進む
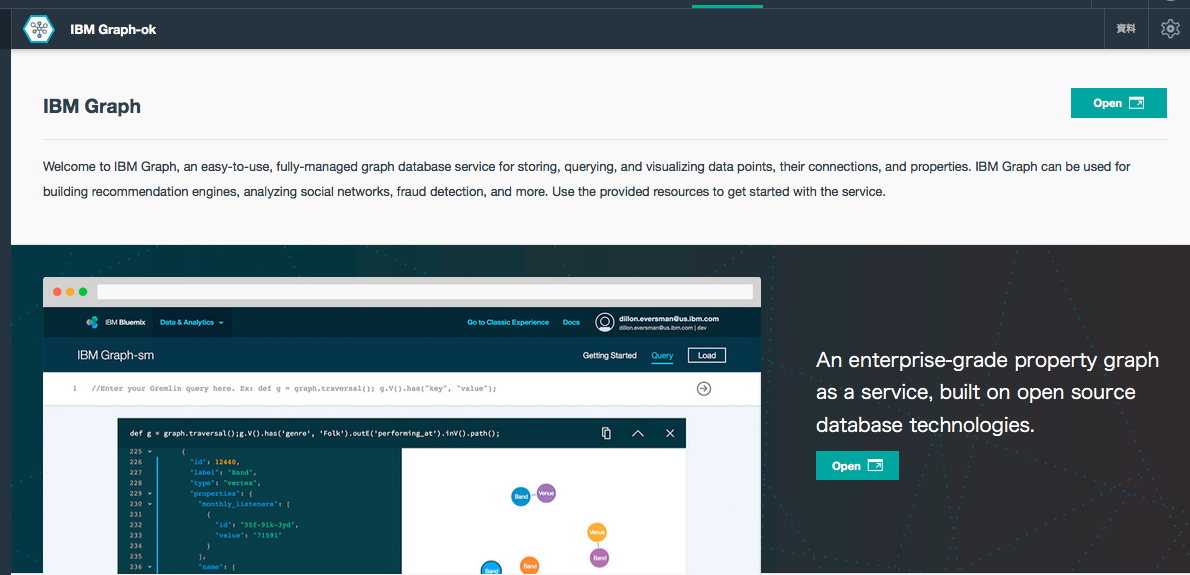
・これがホーム画面らしい。
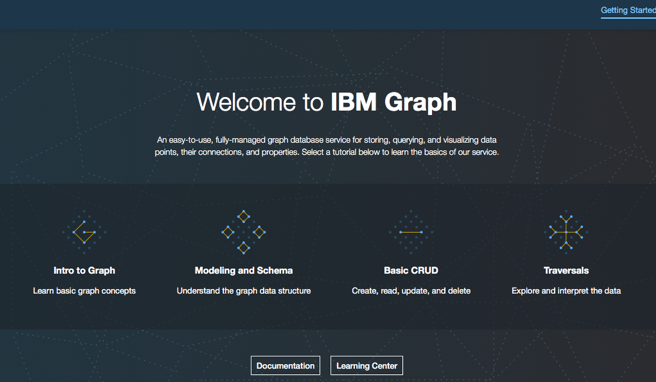
サンプル・データで遊んでみる
本当はget startedから順当に説明を見ていくのが良いと思いますが、とにかくいじってみたいので、いきなり遊んでみます。
データロード
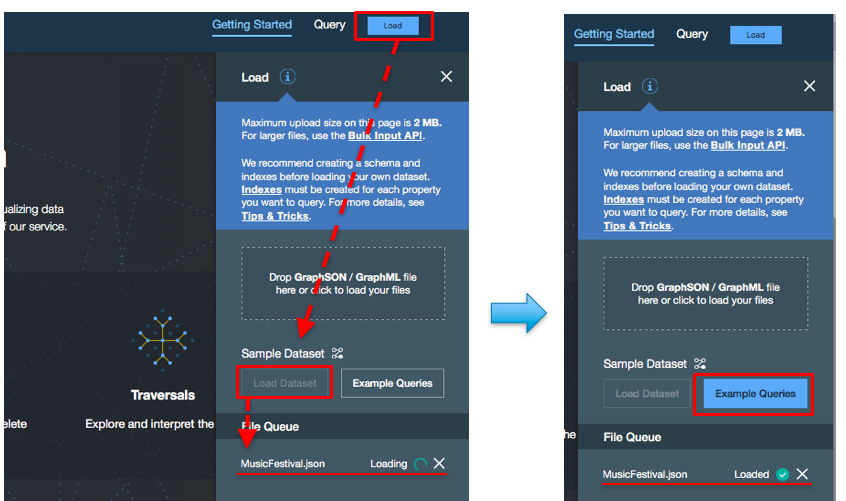
画面右上の「Load」をクリックすると、ローカルのデータをuploadとか色々出てきます。
ここでは、SampleDatasetにある「Load Dataset」をクリック
MusicFestival.jsonというファイルのロードが開始されます。
Loaded、になったら「Example Queries」に進みます。
グラフDBを可視化して見てみる
普通のDBでいうところのselect文みたいなのがすでに準備されているので、それを実行してみます。
普通のDBでは、selectすると表の結果が返ってきますが、グラフDBは、グラフ(エクセル的なグラフ、ではなくて、ネットワーク図、みたいなもの)が表示されます。

サンプルの中からVisualizeなんとかを選択してみると、
select文に相当するものが画面上部に表示されるので、右端の実行ボタンをクリックすると・・・
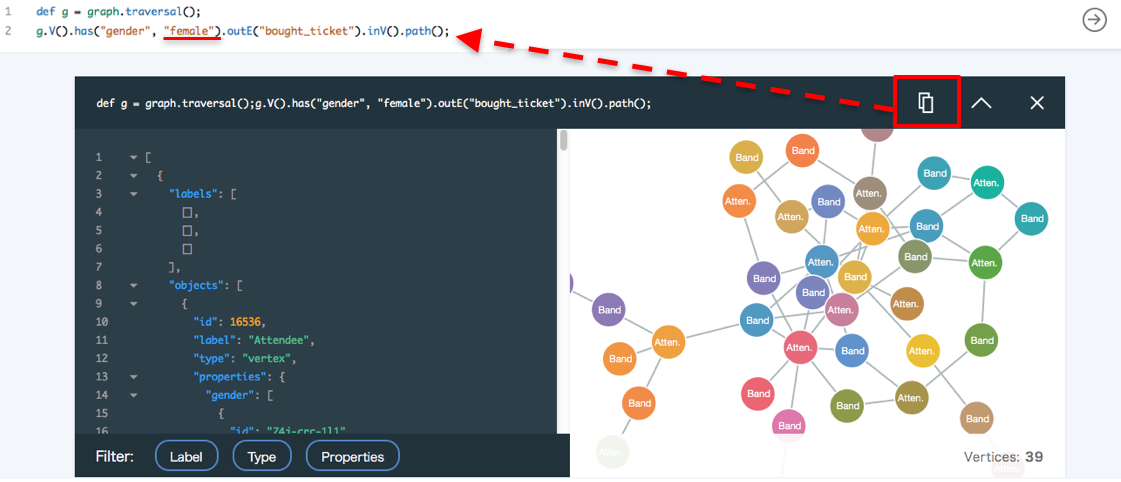
おー。美しい・・・・
左側が、元になっているjsonのデータ、右が可視化結果。
IBM Graphの良いところは、クエリを動的に変えて、その都度、結果をすぐ確認できる柔軟性・・・らしいです(どっかに書いてありました)。
というわけで、赤枠のアイコン、これが既存のクエリを複製するアイコンらしいので、クリックして、また画面上部にクエリを表示させます。
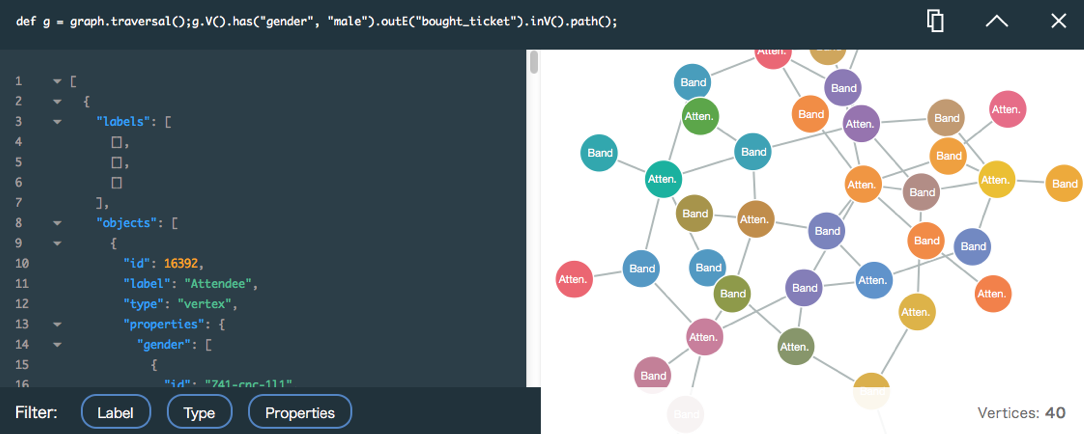
femaleの部分をmanに変えて、再度、クエリ実行ボタンを押してみます。
maleでの結果が出ました。
先ほどは右下のvertices(グレーの線の本数)が39だったのに対して、40に変わってます。
ちゃんとクエリの結果が反映されているようです。
もうちょっとグラフDB勉強して、遊んでみよ。
参考資料
・概要説明動画:酔います・・・(笑)
https://www.youtube.com/watch?v=qMitNJ5zzow