スクレイピングをするときの注意点
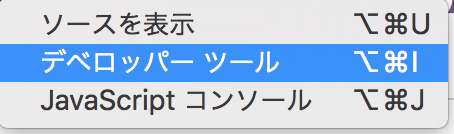
ページのソースコードは右クリックをして、ページのソースを表示ではなく
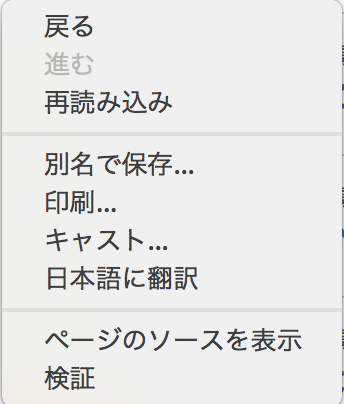
デベロッパーツールで表示された方を使う
textの取り出し
<dt>価格<span class="tax">(税込)</span></dt>
のようにdtタグにspanタグが埋め込まれたもののテキスト取り出すには
source = '<dt>価格<span class="tax">(税込)</span></dt>'
soup = BeautifulSoup(source, "html.parser")
soup.text
と.text指定やることで取り出せる
空白文字の削除
<dt>
価格
<span class="tax">(税込)</span>
</dt>
といったタグ内に空白文字がある場合
def remove_whitespace(str):
return ''.join(str.split())
source = '<dt>価格<span class="tax">(税込)</span></dt>'
soup = BeautifulSoup(source, "html.parser")
remove_whitespace(soup.text)
とやって取り出せる
strip()とかでは中央にある空白は削除できないため、split()で空白文字を区切り文字として
.joinで結合している
BeautifulSoupでのfind
ある特定のクラスを探したい場合
一つの場合
soup.find(class_='hoge')
全てを検索する場合
soup.find_all(class_='hoge')
ある特定のidを探したい場合
一つの場合
soup.find(id='hoge')
全てを検索する場合
soup.find_all(id='hoge')
ある特定のタグを探したい場合
一つの場合
soup.find('hoge')
全てを検索する場合
soup.find_all('hoge')
またこれらは複数条件を同時にもできます
soup.find('hoge',class_='fuga)