
ゲス野郎には容赦しないちょっとカタコトなウチのラズパイさん。(動画)
TL;DR
好きなメッセージを Raspberry Pi に読み上げさせる。
$ say 何をやったってしくじるもんなのさ、ゲス野郎はな。アリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリアリーベデルチ!
また、音声出力は USB スピーカーではなく小型のスピーカーユニット(モノラル)にして物理的にコンパクトにすることで、Raspberry Pi をラジコン化した際などに組み込みやすくしたつもり。
環境
- Raspberry Pi 2 Model B
- OS: Raspbian Jesse Lite
Raspberry Pi 2 の環境導入については下記記事を参照。
Raspberry Pi2 -電源と LAN だけ繋いで Raspbian Jessie Lite に ssh 接続するまで- - Qiita
アンプ基板とスピーカーユニットを接続する
音を出せないと始まらないので、D 級アンプ基板とスピーカーユニットを用意した。モノラルで十分な音量が出れば良いという前提で、自分が使用したものは以下の通り。(部品の組合せの良し悪しは正直分かってないが…)
- PAM8012 使用 2 ワット D 級アンプモジュール: 組立キット 秋月電子通商
- ALTEC LANSING 2.5"(64mm) 小型 スピーカーユニット 8Ω/5W NFJストア
- 3.5mm ステレオミニプラグ⇔スクリュー端子台: パーツ一般 秋月電子通商
- 電池ボックス 単3×3本 端子リード線仕上げ: パーツ一般 秋月電子通商
当初、別の 0.5W 出力のスピーカーユニットを使ったが、音量が思うほど大きくならなかったので上記の 5W 出力のものに変更したら十分な音量を得られた。
アンプ基板の接続
取扱説明書に記載されている通り、シングルエンド入力の使用例に従って接続した。
シングルエンド入力は GND との電圧差を信号化して、差動入力は入力電圧の差を信号化。差動入力の方が耐ノイズ性が優位と理解しているので、音声出力に音質を求めていないことからシングルエンド入力とした。
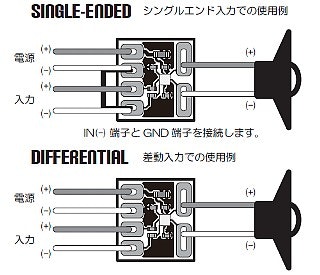
接続した雰囲気は以下のような感じに。
左の緑&黒のリード線は音源側のステレオミニジャックからの入力で、右側の赤&黒はスピーカーユニットへの出力。

なんだか冗長な接続をしているのは、リード線との接触不良で音が出たり出なかったりしたので、しっかり固定するための処置によるもの。きちんとピンヘッダをハンダ付けした方がいい。
スピーカーの動作確認
手元にあった Kindle Fire にステレオミニジャックからアンプ基板+スピーカーユニットに接続して音楽を流してみた。

流した曲が大きな音量で流れたので大丈夫そうだ。
これで Raspberry Pi に接続して読み上げさせれば、音声がスピーカーから出るはず。
音声合成システム OpenJTalk のインストール
ここから Raspberry Pi 上の作業で音声読み上げ用に OpneJTalk 等をインストールする。
作業にあたり下記記事を参考にさせていただいた。
手っ取り早く apt-get で一発インストール
ちょっと古いバージョンでも OK なら、apt-get で一式インストールしてしまうのが簡単でオススメ。
OpenJTalk のバージョンは最新 1.09 に対して 1.07 がインストールされる。
$ sudo apt-get install -y open-jtalk open-jtalk-mecab-naist-jdic htsengine libhtsengine-dev hts-voice-nitech-jp-atr503-m001
各ツールの最新版を個々にインストール
最新版をインストールしたい場合は、apt-get で入れずに以下の手順に従って個々にインストールしていく。
apt-get でインストール済みなら以下の作業は飛ばして OK。
hts_engine_API-1.10 のインストール
Text-To-Speech 本体となる hts_engine をインストールする。
$ mkdir /tmp/tts-install
$ cd !$
$ curl -L http://downloads.sourceforge.net/hts-engine/hts_engine_API-1.10.tar.gz | tar zxfv -
$ cd ./hts_engine_API-1.10
$ ./configure
$ make && sudo make install
$ which hts_engine
/usr/local/bin/hts_engine
$ hts_engine
The HMM-Based Speech Synthesis Engine "hts_engine API"
Version 1.10 (http://hts-engine.sourceforge.net/)
Copyright (C) 2001-2015 Nagoya Institute of Technology
2001-2008 Tokyo Institute of Technology
All rights reserved.
...
open_jtalk-1.09 のインストール
hts_engine を利用した日本語音声変換ツールの OpenJTalk をインストール。
$ cd /tmp/tts-install
$ curl -L http://downloads.sourceforge.net/open-jtalk/open_jtalk-1.09.tar.gz | tar zxfv -
$ cd ./open_jtalk-1.09
$ ./configure --with-charset=UTF-8
$ make && sudo make install
$ which open_jtalk
/usr/local/bin/open_jtalk
$ open_jtalk
The Japanese TTS System "Open JTalk"
Version 1.09 (http://open-jtalk.sourceforge.net/)
Copyright (C) 2008-2015 Nagoya Institute of Technology
All rights reserved.
...
open_jtalk_dic-1.09
辞書ファイルを /usr/local/share/open_jtalk/dic-1.09 以下に配置しておく。
$ cd /tmp/tts-install
$ curl -L http://sourceforge.net/projects/open-jtalk/files/Dictionary/open_jtalk_dic-1.09/open_jtalk_dic_utf_8-1.09.tar.gz | tar zxfv -
$ sudo mkdir -p /usr/local/share/open_jtalk
$ sudo mv ./open_jtalk_dic_utf_8-1.09 !$/dic-1.09
音響モデルをメイちゃんにする
デフォルトの音響モデル(音声) nitech_jp_atr503_m001.htsvoice だとカタコトな中年のおっさんがボソボソ喋り出すので、MMDAgent のメイちゃんに交代していただく。
MMDAgent に含まれる *.htsvoice を /usr/local/share/hts_voice に置く。
$ curl -L -O http://sourceforge.net/projects/mmdagent/files/MMDAgent_Example/MMDAgent_Example-1.6/MMDAgent_Example-1.6.zip
$ unzip MMDAgent_Example-1.6.zip
$ mkdir -p /usr/local/share/hts_voice
$ find ./MMDAgent_Example-1.6 -type f -name "*.htsvoice" -exec cp -v {} /usr/local/share/hts_voice/ \;
$ ls /usr/local/share/hts_voice/
mei_angry.htsvoice mei_happy.htsvoice mei_sad.htsvoice
mei_bashful.htsvoice mei_normal.htsvoice
メイちゃんの音響モデルは 通常、怒り、内気、悲しい、嬉しい の感情音声があるようだ。
Raspberry Pi に喋らせる
材料は揃ったので、いよいよ Raspberry Pi に喋らせたい。
Raspberry Pi のミニジャックとアンプ基板を接続しておく。
Raspberry Pi の設定
サウンド周りの設定にあたり ALSA (Advanced Linux Sound Architecture) ユーティリティを入れる。
$ sudo apt-get install -y alsa-utils
サウンド出力やボリュームの設定。
### サウンド出力先をアナログ出力(ミニジャック)にする
$ sudo amixer cset numid=3 1
### Raspberry Pi のボリュームを変更する
$ sudo amixer set PCM on
$ sudo amixer set PCM 100%
スピーカーから音が出せる状態になっているか確認する。
$ speaker-test
speaker-test 1.0.28
Playback device is default
Stream parameters are 48000Hz, S16_LE, 1 channels
Using 16 octaves of pink noise
Rate set to 48000Hz (requested 48000Hz)
Buffer size range from 512 to 32768
Period size range from 512 to 32768
Using max buffer size 32768
Periods = 4
was set period_size = 8192
was set buffer_size = 32768
0 - Front Left
Time per period = 0.794753
(Ctrl+c で停止)
スピーカーから「ザーッ」とノイズ音が出ればオッケー。
喋らせてみよう
OpenJTalk で PCM ファイルを出力して、aplay コマンドで再生させる。
とりあえず、ベタに実行。
$ echo "ラズベリーパイです。こんにちは、世界!" > voice.txt
$ open_jtalk -x /usr/local/share/open_jtalk/dic-1.09 -m /usr/local/share/hts_voice/mei_happy.htsvoice -ow voice.wav ./voice.txt
$ aplay ./voice.wav
Playing WAVE 'voice.wav' : Signed 16 bit Little Endian, Rate 48000 Hz, Mono
Raspberry Pi がメイちゃん音声で喋ってくれれば成功!
アンプ基盤で期待通りに音声が増幅されたようで、十分すぎるほどのボリュームだった。
say コマンドでスクリプト化
簡単に使えるよう Mac の真似して say コマンドを用意しておくことにした。
使い方は、引数に喋らせたいことを書くだけ。
$ say こんにちは世界、ラズベリーパイです。
スクリプトは以下の通りで、bash 前提の非 POSIX。
単純化の為に OpenJTalk のパラメータは固定にして、中間ファイルも生成させないようにした。
# !/bin/bash -eu
readonly MESSAGE=$@
readonly DIC=/usr/local/share/open_jtalk/dic-1.09
readonly VOICE=/usr/local/share/hts_voice/mei_normal.htsvoice
readonly PITCH=1.0
readonly GAIN=3.0
if [ -z "$MESSAGE" ]
then
echo "usage: $(basename `readlink -f $0`) MESSAGE" >&2
exit 1
fi
echo $MESSAGE | open_jtalk -x $DIC -m $VOICE -r $PITCH -g $GAIN -ow /dev/stdout | aplay --quiet
PITCH は喋るスピードで、GAIN はボリュームみたいなもの。
メイちゃんの感情音声を変更したければ、VOICE に指定した音響モデルのファイルを変えれば OK。
Raspberry Pi はミニジャック経由だと音質が悪い?
この程度の Text-to-Speech 用途なら許容範囲だけど、確かにノイズ混じり。
そもそも Raspberry Pi のミニジャックは 4 極なので、3 極ミニプラグを挿すと GND とショートしてよろしくないようだ。
Raspberry Pi B+の音声出力ジャックは4極型 | nao@snwlab
※コメント欄の記載が参考になる
音質が悪いと評されているのは、これが原因ではないのかなと思う。
今回書いた記事においても 3 極ミニプラグを使用したので 4 極に置き換えたい。