はじめに
ElasticsearchのTerms Aggregationをを使用すると、集計結果の上位n件とかをサックリと取得できます。取得できるのですが、基本的にTerms Aggregationで取得できるのは「おおよそ」の値です。もしかすると、1位だと思っていたデータが、実は2位かもしれません。
大抵の場合は問題ないと思いますが、どうしても正確な値が欲しいということもあります。そんな場合は適切にオプションを設定しましょう。公式ドキュメントでも丁寧に説明されていますので、そちらも合わせてご参照ください。
Terms Aggregationの動き
Terms Aggregationの動きを説明するために、アクセスログからアクセス数の多いIPアドレスの上位3件を取得するケースで考えてみます。
以下のように、doc_countでソートしてsizeで件数をしてあげれば良さそうです。
{
"aggs": {
"source_ip_addresses": {
"terms": {
"field": "source_ip_address",
"order" : { "_count" : "desc" },
"size": 3
}
}
}
}
しかし、sizeに3を指定しても、全ドキュメントからIPアドレス数を集計して3つを取得する訳ではありません。集計は、まずshard単位に行われます。shard単位に上位3つ取得し、次に各shardの上位3つを集計、その集計結果の上位3件が最終結果となります。つまり、各shardの4位以下のデータはすべて切り捨てられてしまうわけです。
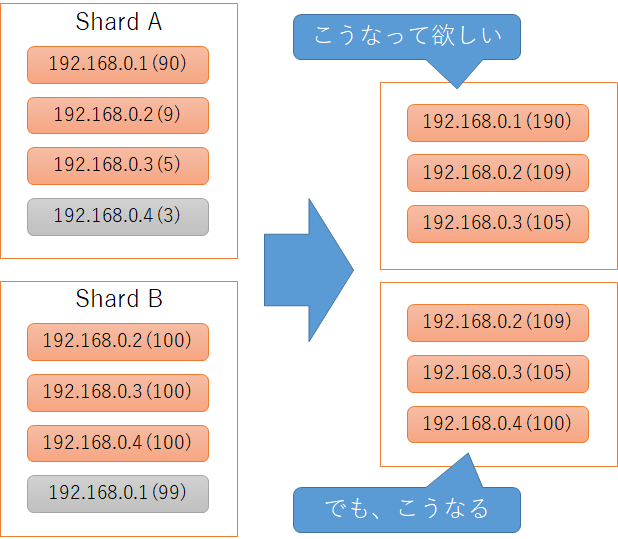
正確な結果を求めるには
これを解決するためには、shard単位では全集計結果を取得し、最終的な結果に対してのみsize指定できれば良いのです。Terms Aggregationでは、shard単位のsizeを設定するために、shard_sizeオプションが用意されています。shard_sizeは指定されない場合にsizeと同じになりますので、上記の例では各shardの4位以下が切り捨てられてしまったのです。
以下のようにshard_sizeに0 (Integer.MAX_VALUE)を設定し、sizeに3を指定すると正確に上位3件が取得できます。
{
"aggs": {
"source_ip_addresses": {
"terms": {
"field": "source_ip_address",
"order" : { "_count" : "desc" },
"size": 3,
"shard_size": 0
}
}
}
}
ちょっとだけ注意
shard_sizeを大きくすると、当然Elasticsearchの負荷が高くなります。どうしても必要な場合だけ使うと良いでしょう。