はじめに
Elasticsearchには、ドキュメント更新を1クエリで実行できるBulk APIなんてものがあります。テストデータを投入するときとかに便利なので、使っている方も多いかと思います。
アプリからElasticsearchにデータを投入するとき、Fluentdとかを経由すると自動でBulk APIを使ってくれるのですが、直にデータを投入するときは面倒だから1つずつで良いや、とかなったりします。性能差が大きいようなら積極的にBulk APIを使った方が良いよねということで、測ってみました。
測定条件
適当に、こんな感じでやってみます。
- インデックスは1つだけ。
- ドキュメントは10フィールド * 50文字。
テストコード
Pythonと公式クライアントの組み合わせで、テストコードを書きます。
Bulkサイズを変えながら、10,000件のドキュメントを登録します。
import time
from elasticsearch.client import Elasticsearch
from elasticsearch.exceptions import TransportError
from elasticsearch.helpers import bulk
def generate_test_doc():
"""
すごい適当にデータを作る。
"""
return {
"field1": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field2": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field3": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field4": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field5": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field6": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field7": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field8": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field9": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
"field10": "aaaaaaaaaabbbbbbbbbbccccccccccdddddddddd",
}
class PerformanceTimer(object):
def __init__(self, message):
self._message = message
def __enter__(self):
self._start = time.clock()
def __exit__(self, exc_type, exc_val, exc_tb):
print("| {0:30} | {1:>6.3f} |".format(
self._message,
(time.clock() - self._start)))
if __name__ == "__main__":
INDEX_NAME = "test_index"
TYPE_NAME = "test_type"
NUM_DOCS = 10000
es = Elasticsearch([{"host": "192.168.99.100", "port": 9200}])
try:
es.indices.delete(INDEX_NAME)
es.indices.flush()
except TransportError:
pass
# Index API (create)
with PerformanceTimer("Index API (create)"):
for i in range(0, NUM_DOCS):
es.create(INDEX_NAME, TYPE_NAME, generate_test_doc())
es.indices.flush()
assert es.count(INDEX_NAME, TYPE_NAME)["count"] == NUM_DOCS
es.indices.delete(INDEX_NAME)
es.indices.flush()
# Bulk API (create)
for bulk_size in [1, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120]:
with PerformanceTimer("Bulk API {0} (create)".format(bulk_size)):
for i in range(0, NUM_DOCS - (NUM_DOCS % bulk_size), bulk_size):
actions = []
for j in range(0, bulk_size):
actions.append({
"_op_type": "create",
"_index": INDEX_NAME,
"_type": TYPE_NAME,
'_source': generate_test_doc()
})
bulk(es, actions)
# あまり。
if NUM_DOCS % bulk_size != 0:
actions = []
for j in range(0, NUM_DOCS % bulk_size):
actions.append({
"_op_type": "create",
"_index": INDEX_NAME,
"_type": TYPE_NAME,
'_source': generate_test_doc()
})
bulk(es, actions)
es.indices.flush()
assert es.count(INDEX_NAME, TYPE_NAME)["count"] == NUM_DOCS
es.indices.delete(INDEX_NAME)
es.indices.flush()
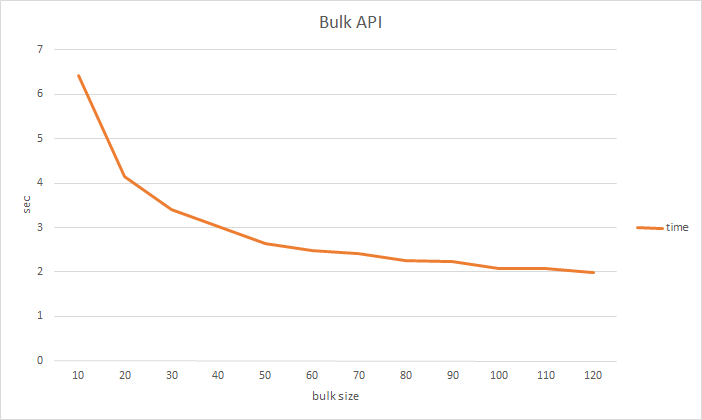
測定結果
結果はこんな感じ。
| op | time |
|---|---|
| Index API (create) | 23.365 |
| Bulk API 1 (create) | 20.791 |
| Bulk API 10 (create) | 6.414 |
| Bulk API 20 (create) | 4.148 |
| Bulk API 30 (create) | 3.403 |
| Bulk API 40 (create) | 3.017 |
| Bulk API 50 (create) | 2.638 |
| Bulk API 60 (create) | 2.474 |
| Bulk API 70 (create) | 2.424 |
| Bulk API 80 (create) | 2.258 |
| Bulk API 90 (create) | 2.244 |
| Bulk API 100 (create) | 2.071 |
| Bulk API 110 (create) | 2.073 |
| Bulk API 120 (create) | 1.998 |
結論
Elasticsearchにデータを入れるときはBulk APIを使いましょう。
一度に入れるドキュメント数は、100くらいで十分。