Maker Faire Tokyo2016 機械学習を用いた自動運転についてのメモ
概要 (動画)
https://drive.google.com/open?id=0B_o9vkhBpXoYUEdaMzBiR2pMMUk
当日掲示していた資料
https://drive.google.com/open?id=0B_o9vkhBpXoYZWV0d1dsSTF3cUE
ソースコード
https://github.com/AAmmy/MFT2016
(当日使用したものは後日アップロード)
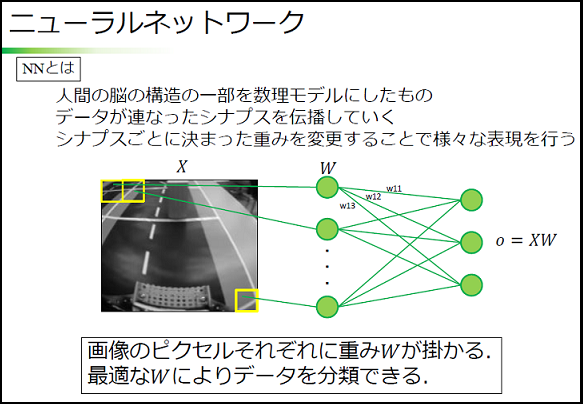
ニューラルネットワーク
前提
入力 X : 50×50 の画像を 1×2500 にしたもの
つまり $X = \{x_0, x_1, ・・・, x_{2499}\}$
$0 \leq x_i \leq 255$ は画像のそれぞれのピクセルの値 (輝度値)
出力 Y : 直進 ⇒ 0, 左 ⇒ 1, 右 ⇒ 2
つまり $Y = \{y_0, y_1, y_2\} = \{0, 1, 2\}$
重み W:ネットワークの大きさによって要素数が異なる
$\hat{y}$:作成したモデルによって予測される値
最も単純な場合
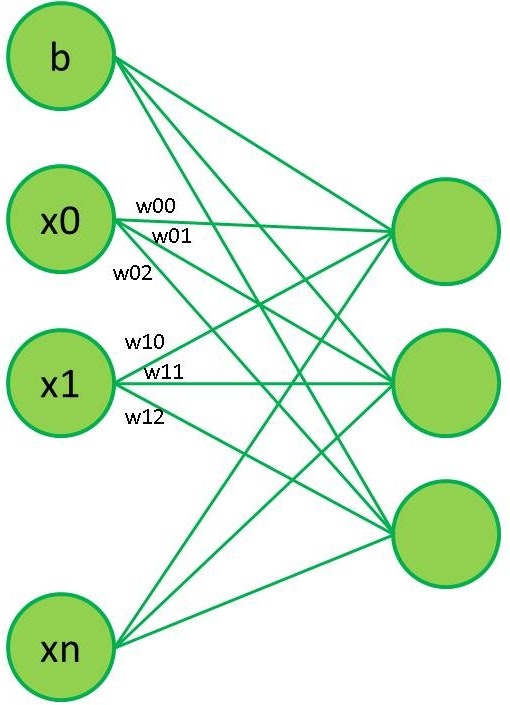
$\hat{y} = argmax(WX + b)$
W:今回は入力 2500, 出力 3 であるから, W は 2500×3 の2重配列
b:バイアス, 今回は出力 3 であるから, b はサイズ 3 の配列
WX:W と X の内積, 出力は3つ
float[] WX = new float[w[0].size] // 出力の数(3つ)
for(j = 0; j < WX.size; j++) // 3回
for(i = 0; i < x.size; i++) // 2500回
WX[i] += x[i] * w[i][j] // 積の和が内積
argmax():もっとも最大の要素を含むインデックスを求める
内積によって得られた3つの値のうち最大のものが予測される操作となる.
例
argmax([3, 2, 1, 0]) ⇒ 0 (0番目の要素の3が最も大きい)
argmax([0, 3, 2, 1]) ⇒ 1 (1番目の要素の3が最も大きい)
max = a[0]
argmax = 0
for(i = 0; i < a.size, i++) // a をすべて見る
if(max < a[i]){ // 現在のmaxよりも今見ているa[i]が大きいとき
max = a[i] // maxを更新
argmax = i // argmaxを更新
}
まとめると
y_pred = argmax(dot(X, W) + b)
実際にmnistのデータとpythonで実行すると次のようになる.
ソースコード
$ ./wxb
91.64%
$ python wxb.py
92.25 %
(Cを普段書かないので全部グローバル変数なのはご了承ください)
ソースコードについて
mnist:手書き数字のデータセット.手書きの数字のデータとそれが何の数字かというラベルデータが大量に入っている.
これと学習済みの重みとバイアスを用いて WX + b により 10000 のテストデータに対して数字の予測を行った結果を表示している.
C と python での結果が微妙に異なるのは精度が異なるため(だったと思う).
重みの学習は
http://deeplearning.net/tutorial/
の Logistic Regression や Multilayer perceptron のコードを用いた.
中間層を1つつける場合
$\hat{y} = argmax(tanh(W1X + b1)W2 + b2)$
層が一つ増えるので重み W とバイアス b も増える
W1:中間層の出力数を適当に 100 とすると, 入力 2500 であるから, W1は 2500×100 の 2 重配列
b1:入力は中間層の出力 100 となるため, b1はサイズ 100 の配列
W2:入力は中間層の出力 100 , また,出力 3 となるため. W2 は 100×3 の 2 重配列
b2:入力は中間層の出力 100 となるため, b1 はサイズ 3 の配列
tanh:ハイパボリックタンジェント,
tanh = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}
tanh = Math.tanh(x)
i for all input elements index // すべての入力の要素に対して
output[i] = tanh(input[i]) // 単純にtanhの値を求める
学習済みの重みを用いてテストデータを識別すると,
ソースコード
$ python mlpWXb.py
97.97 %
参考
https://www.coursera.org/learn/machine-learning
–機械学習の講義 (日本語字幕あり)
http://deeplearning.net/tutorial/
–Theano を用いた機械学習チュートリアル