AWS re:Invent 2014 - Breakout Session 1日目が終了しました!
忘れないうちに本日の内容についてまとめておきます.
「AWS re:Invent 2014」とは
私自身,今回初参加となる「AWS re:Invent 2014」について簡単にまとめます.
AWS re:Invent 2014とは,Amazon Web Service (AWS; http://aws.amazon.com/jp/) に関する世界最大のイベントで,AWSに関する知識はもちろん,クラウドサービスについての基本的知識から業界の最先端の動向まで,幅広く知ることが出来るカンファレンスです (※私的意見).
3回目の開催となる今回は,世界63カ国から13,500人以上の方が参加しているそうです.この数は1回目開催時の約2倍にあたるそうで,この規模の変化だけに着目しても,現在AWSが世界的に注目を集めているサービスであることが分かります.
見たセッションについてまとめ
私が参加したセッションについて,感想ベースでまとめていきます.
Keynote

とにかくプレゼンに圧倒されました!
AWSは,世界で最も伸びているクラウドサービスだそうです (参考: http://aws.amazon.com/jp/resources/gartner-mq-2014-learn-more/).
デモでは,7TB * 2430 games / season = 17PB のMLBのデータや,1PB / monthずつ追加されていく医療データが取り上げられていました.
秒間2000回のシミュレーションを行えるAWSのcompute力もさることながら,近年益々注目されている医療分野においてもAWSが強い存在感を放っていることが分かり,さすがAmazonという感じです.
また,KeynoteではAmazon Aurora,Amazon CodeDeploy,etc.といった数々の新製品も発表されました.これらについては書いていくと終わらなさそうなので省略させて頂きます (他でたくさん紹介されているはず。。。←)
全体的な感想としては,今回の発表を通して「すべてがAWSになる」・・・という感じで,Coreな機能は全てAWSに委譲した運用が可能になる世界が来るんだなという印象です.
私達がInnovationを起こすんだ!という気概がビシビシ伝わってきました.
最後の方では,Amazonのユニークなカルチャーについて
- 顧客志向であること - 顧客が必要なサービスを提供する
- パイオニアであること - 私達自身が常に革新的な物事を生み出していく
- 長期的な目線を持つこと - 真に必要(=有用)なビジョンを見据えて,長期的に種から育てていくこと
の3つが取り上げられていましたが,今回の発表がまさに象徴的だなと感じました.
BDT205 - Your First Big Data Application on AWS
Apacheログ (Log4J) をKinesisで取り込んでEMR->S3->Redshiftな話.
もう少しBig Dataによった話かと想像していたんですが,かなり初心者向けな話で,九分九厘知っている感じでしたorz
セッション選びにおける痛恨の戦略ミス.
AWSを全然触ったことがなくて,これから始めたいという方にはオススメです.
本日の内容が以下にまとまっているので,興味のある方はご一読下さい.
http://bit.ly/aws-bdt205
HLS402 - Getting into Your Genes: The Definitive Guide to Using Amazon EMR, Amazon ElastiCache, and Amazon S3 to Deliver High-Performance, Scientific Applications
life Cloudの話.
- generic informationを得るために,大規模データをリアルタイム解析する
- 大規模な科学計算データを保存&管理する
- 大規模データセットから,インタラクティブ&スピーディーにグラフを描画する
- データをシェアしたり他者との共同編集が容易である
といった,医療分野における要件を満たすために,AWSを利用してシステムを構築した事例を紹介していました.
ElasticCascheをin-memoryなストレージとして利用し,DynamoDBとRedshiftの前に置くことで,リアルタイムに複雑なグラフを描画することが可能になった話などが面白かったです.
全体的に初心者向けな話でした.
BDT306 - Mission-Critical Stream Processing with Amazon EMR and Amazon Kinesis
DataXuの方が話されていました.
広告配信を例に,データ損失がイコール利益損失につながるような,ミッションクリティカルなストリーム処理について,EMR + (multiple AZs) Kinesisな環境構築例が紹介されました.
状況に応じてKinesisのScale upとScale downが行われ,CloudWatchを利用してその状況を監視しています (Real-time BiddingデータやRetargeting infoなどは全てKinesisに入ってきます).
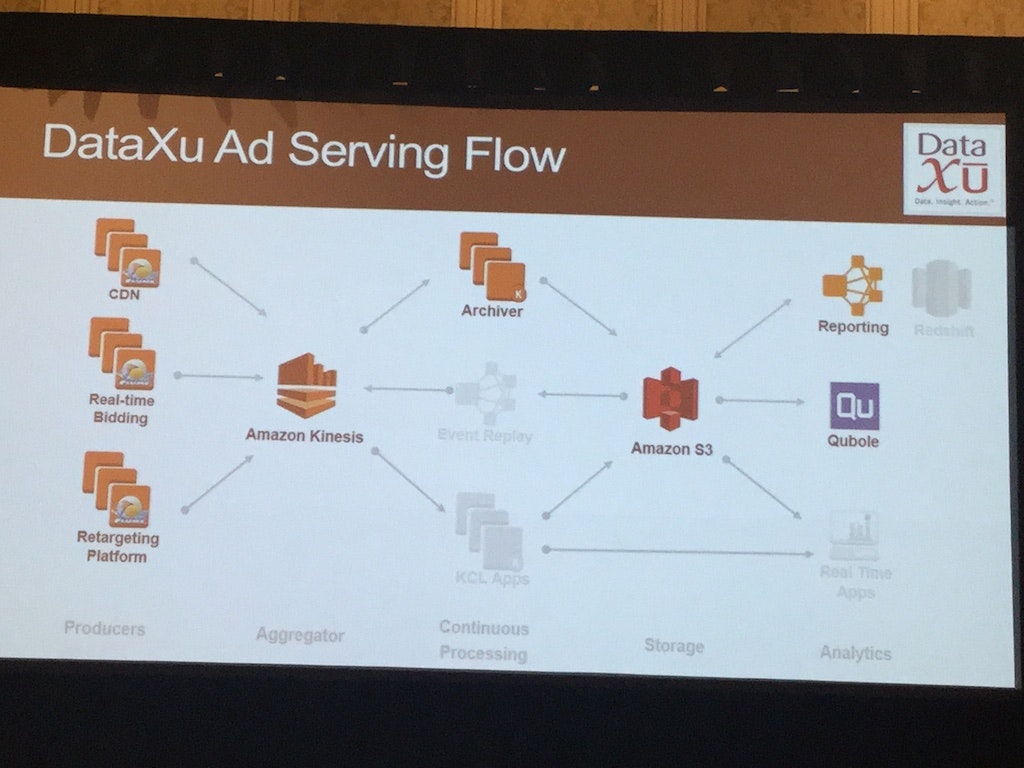
個人的には,業務ともかなり関連した話題なので後でもう一度整理したいと思っています.
また,ここでグラフ描画ツールとしてKibanaライクなGrafanaというツールを初めて知りました.
HLS201 - Using AWS and Data Science to Analyze Vaccine Yield
Explore Data Scienceの方が話されていました.
解析者 (Data Scientist) がよくぶつかる問題とは何でしょうか?
- 1000種類を超える素性 (=特徴量,e.g. 温度,モーターの値)を扱う
- 直感的に選択できる影響力の高い素性は限られている
- 各センサ毎にTB級のデータ量が発生する
データ規模が大きくなる&これらが計算可能 (=AWSを使うと可能!!) であると,問題の答えをデータ自身が教えてくれることがあります・・・という話をされていました.すごくシンプルなパターン認識の話です.
具体的な例として,1000個のセンサーの時系列データから類似性を発見する話をされていました.
後半でconcrete implementationの話をするということで楽しみにしていたのですが,内容としては解析者/開発者入り乱れた現場で誰にどのような権限を与えれば円滑に回るか (=security)・・・という話がほとんどで,個人的にはあまり興味をそそられなかったので省略させて頂きます.
APP315-JT - Coca-Cola: Migrating to AWS - Japanese Track
日本語トラックだったのに,事前に受け取っていたTranslator用チケットを忘れて結局英語で聴講w
個人的には,今日聞いた中で一番面白かったです.
コカ・コーラ社が行った大規模サービスにおけるAWSの活用事例に関する話.
まず課題として,1日に世界中19億のユーザに配信するプロモーションをどうやって捌くのかという問題が取り上げられていました.500種類以上のbrandがあり,207カ国に配信しなければいけないという背景の中で,同社としては収益性を重視したシステムを構築したいというモチベーションを持って取り組んでいました.具体的には時間とコストの2点に着目しています.
- コカ・コーラにおける最大の問題点は常にスケールだった.スケール出来るということはクラウドの大きな利点である -> コストに対する効果が見える (オートスケール最高!)
- トラブルシューティングが出来る人がデータセンターにいない/グローバル事業なので,世界規模でメンテナンスを考慮する必要がある -> AWSはフルマネージドサービスである
- その他 色々
特にCloud Formationが運用の上で非常に有用だったという話をされていました.
過剰な投資はやめたいけど,ユーザをがっかりさせないためにサービスのパフォーマンスは維持したい・・・というシンプルな目標に対して,AWSが最も最適だったそうです.
最終的にコストを40%削減し,Ticketが80%も減ったらしい (!)
ここでは書きませんが,色々なノウハウについても話していて,非常に興味深いセッションでした.クラウド活用の良いモデルだなと思います.
まとめ
初参加ですが,色々と濃くて学びのある場で楽しいです.
明日以降も聞きたいセッションがたくさんあるので楽しんできます.
※Pub Crawlで飲んで酔っ払って後に書いた記事なので,おかしな点などありましたらお気軽にお知らせ下さいmm
