はじめに
procfsのエントリを作成する処理はカーネルやデバイスドライバのコードによく現れます。その際によく見かけるのは、以下のようにプレフィックスが「seq_」となっている関数名です。
static const struct file_operations proc_schedstat_operations = {
.open = schedstat_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};
これはseqファイルシステムと呼ばれる仕組みで提供しているI/Fになります。seqファイルシステムとは何でしょうか。
今回いろいろな目的があり、seqファイルシステムについての文書を作成しました。
なお、今回読んだLinuxのソースコードのバージョンは4.9になります。
まずDocumentを読む
8 There are numerous ways for a device driver (or other kernel component) to
9 provide information to the user or system administrator. One useful
10 technique is the creation of virtual files, in debugfs, /proc or elsewhere.
11 Virtual files can provide human-readable output that is easy to get at
12 without any special utility programs; they can also make life easier for
13 script writers. It is not surprising that the use of virtual files has
14 grown over the years.
要約すると以下のとおりです。
ユーザやシステム管理者にデバイスドライバが保有する情報を提供する手段はいろいろありますが、その中でも有用な手段のひとつが/procなどに代表される仮想ファイルを使うことです。しかし、仮想ファイルをフルスクラッチで都度実装するのは面倒であり、かつ同じような実装が重複してしまうため、良いことはありません。
よって、仮想ファイルのフレームワーク的なものを提供した・・・というのがseqファイルシステムが生まれた動機です。
67 The iterator interface
68
69 Modules implementing a virtual file with seq_file must implement a simple
70 iterator object that allows stepping through the data of interest.
71 Iterators must be able to move to a specific position - like the file they
72 implement - but the interpretation of that position is up to the iterator
73 itself. A seq_file implementation that is formatting firewall rules, for
74 example, could interpret position N as the Nth rule in the chain.
75 Positioning can thus be done in whatever way makes the most sense for the
76 generator of the data, which need not be aware of how a position translates
77 to an offset in the virtual file. The one obvious exception is that a
78 position of zero should indicate the beginning of the file.
79
80 The /proc/sequence iterator just uses the count of the next number it
81 will output as its position.
82
83 Four functions must be implemented to make the iterator work. The first,
84 called start() takes a position as an argument and returns an iterator
85 which will start reading at that position. For our simple sequence example,
86 the start() function looks like:
実装者がこの仮想ファイルシステムを使うためには、「提供したいデータをseqファイルシステムで扱うためのイテレータI/F」を実装します。
このI/Fは4つあり、以下のとおりです。
| I/F | 役割 |
|---|---|
| void *start(struct seq_file *s, loff_t *pos) | 第二引数で渡された位置情報に対応したイテレータを返す |
| void *next(struct seq_file *s, void *v, loff_t *pos) | 第三引数で渡された位置情報に対応したイテレータを返す。一般的には第三引数は「次」の位置を指している。また、第二引数で渡されるイテレータは「現在の」イテレータである。 |
| void stop(struct seq_file *s, void *v) | イテレータによったデータの横断が完了したときに呼ばれる。一般には後始末処理であり、第二引数で渡されたイテレータは最後のイテレータである。 |
| int show(struct seq_file *s, void *v) | seq_fileシステム内部で確保したバッファに、第二引数で渡されたイテレータに対応した情報を書き込む。「seq_fileシステム内部で確保したバッファ」については後述。 |
イテレータの型はvoid *であり、仮想ファイル提供側にとって意味のある「何か」を指し示していれば何であっても構わない点に留意します。
なお、上の表の説明にあるI/Fの仕様を知るには、Documentationだけではいささか読み取りにくい部分があります。なので、一緒に実装を読んで確認していきます。
4つのイテレータI/F
Linuxのソースを確認します。すると、使い方が実にわかりやすいseqファイルシステムの内部関数を見つけることができます。この実装を見ると、上記4つのI/Fの目的がわかりやすくなると思われます。
static int traverse(struct seq_file *m, loff_t offset)
{
// 略
index = 0;
// 略
// 先頭のデータを指すイテレータを取得。void *なので「何か」を指しているに過ぎない。
// I/Fを提供する側にとって意味のある何かであり、このレイヤで中身は詮索しない。
p = m->op->start(m, &index);
while (p) {
// 略
// 現在のイテレータが指している情報を表示
error = m->op->show(m, p);
// 略。indexの更新などを行っている。
// 現在のイテレータと次の位置を示すindexを渡して、次の情報を指すイテレータを取得。
p = m->op->next(m, p, &index);
}
// 全ての情報を辿ったので、後始末処理
m->op->stop(m, p);
// 略
}
使用例から使い方を把握する
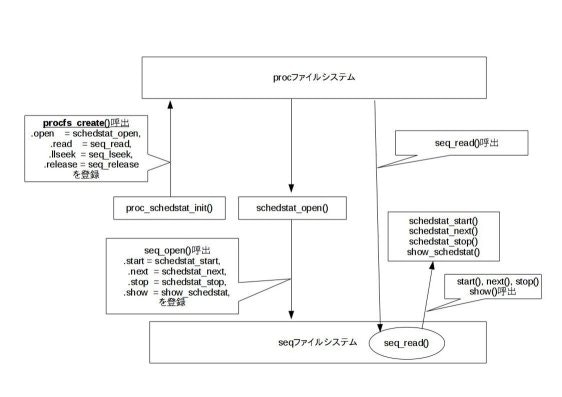
使用例として/proc/schedstatを挙げます。なお、schedstat出力にとって重要な箇所であっても、seqファイルシステムの使い方にとって些細と思われる箇所は省略しました。
実装の概要図は以下の図のとおりです。これをもとに、以下引用ソースを読まれるとわかりやすいと思われます。
/*
* bump this up when changing the output format or the meaning of an existin g
* format, so that tools can adapt (or abort)
*/
# define SCHEDSTAT_VERSION 15
static int show_schedstat(struct seq_file *seq, void *v)
{
int cpu;
// 初回
if (v == (void *)1) {
seq_printf(seq, "version %d\n", SCHEDSTAT_VERSION);
seq_printf(seq, "timestamp %lu\n", jiffies);
} else {
// 二回目以降(一部処理を略
cpu = (unsigned long)(v - 2);
rq = cpu_rq(cpu);
/* runqueue-specific stats */
seq_printf(seq,
"cpu%d %u 0 %u %u %u %u %llu %llu %lu",
cpu, rq->yld_count,
rq->sched_count, rq->sched_goidle,
rq->ttwu_count, rq->ttwu_local,
rq->rq_cpu_time,
rq->rq_sched_info.run_delay, rq->rq_sched_info.pcount);
seq_printf(seq, "\n");
// 略
# endif
}
return 0;
}
/*
* This itererator needs some explanation.
* It returns 1 for the header position.
* This means 2 is cpu 0.
* In a hotplugged system some cpus, including cpu 0, may be missing so we have
* to use cpumask_* to iterate over the cpus.
*/
static void *schedstat_start(struct seq_file *file, loff_t *offset)
{
unsigned long n = *offset;
if (n == 0)
return (void *) 1;
// 次のオフセット(n)を計算する。詳細は略。
*offset = n + 1;
if (n < nr_cpu_ids)
return (void *)(unsigned long)(n + 2);
return NULL;
}
static void *schedstat_next(struct seq_file *file, void *data, loff_t *offset)
{
(*offset)++;
return schedstat_start(file, offset);
}
static void schedstat_stop(struct seq_file *file, void *data)
{
}
static const struct seq_operations schedstat_sops = {
.start = schedstat_start,
.next = schedstat_next,
.stop = schedstat_stop,
.show = show_schedstat,
};
static int schedstat_open(struct inode *inode, struct file *file)
{
return seq_open(file, &schedstat_sops);
}
static const struct file_operations proc_schedstat_operations = {
.open = schedstat_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};
static int __init proc_schedstat_init(void)
{
proc_create("schedstat", 0, NULL, &proc_schedstat_operations);
return 0;
}
subsys_initcall(proc_schedstat_init);
seqファイルシステムの内部実装を少し覗く
seqファイルシステムの働きをより把握するために、内部実装を少し覗きます。
seq_open()
seq_file構造体の割当と初期化が主な処理です。
また、上位レイヤから渡されたfile構造体のprivate_dataにseq_file構造体を割り当てます。
int seq_open(struct file *file, const struct seq_operations *op)
{
struct seq_file *p;
WARN_ON(file->private_data);
p = kzalloc(sizeof(*p), GFP_KERNEL);
if (!p)
return -ENOMEM;
file->private_data = p;
mutex_init(&p->lock);
p->op = op;
// No refcounting: the lifetime of 'p' is constrained
// to the lifetime of the file.
p->file = file;
// 略
return 0;
}
EXPORT_SYMBOL(seq_open);
seq_read()
seq_read()がやっているのはおおよそ以下の処理です。
- 内部バッファが確保されていない場合、内部バッファ(m->buf)を確保する。
- 確保した内部バッファにあらかじめ貯めこまれた or seq_read()内で貯めこんだデータをcopy_to_user()でユーザプロセスに渡す。ユーザランドから要求される読み出しサイズは第三引数経由で渡される。
ポイントになるのは、「seqファイルシステムは内部バッファを持ち、そこに貯められたデータをユーザに渡す」です。
ssize_t seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{
struct seq_file *m = file->private_data;
size_t copied = 0;
loff_t pos;
size_t n;
void *p;
int err = 0;
// 略
// バッファ割当
/* grab buffer if we didn't have one */
if (!m->buf) {
m->buf = seq_buf_alloc(m->size = PAGE_SIZE);
if (!m->buf)
goto Enomem;
}
// バッファの中にデータが残っている場合、ユーザに渡す
/* if not empty - flush it first */
if (m->count) {
n = min(m->count, size);
err = copy_to_user(buf, m->buf + m->from, n);
// 略
}
//
/* we need at least one record in buffer */
pos = m->index;
p = m->op->start(m, &pos);
while (1) {
// 先に紹介したtraverse類似の処理。start(), next(), show(), stop()を使い、
// 情報を内部バッファにコピーする。細かな処理は略。
}
m->op->stop(m, p);
m->count = 0;
goto Done;
Fill:
// 略
}
EXPORT_SYMBOL(seq_read);
データの出力
ここで、seqファイルシステムもファイルシステムです。したがってseq_read()は、「ユーザプロセスから渡されたバッファにデータを書き込んでユーザプロセスに渡す」という本来のread()の約束事を踏襲します。
そして、内部バッファに情報を書き込む処理は、先に紹介したshow() I/Fになります。
その名前から、printk()などでデータをコンソール出力すると勘違いしがちですが、show()に期待されるのはseqファイルシステム内部で用意した内部バッファにデータを書き込む処理です。
では、内部バッファが何で、そのどこにデータを書き込むのか・・・と行った細かなことをいちいち意識し、バッファへの書き込み処理を自前で書かないといけないのでしょうか。
特別なことがない限り、内部バッファへの書き込みは、seqファイルシステム内部のユーティリティ関数で実施します。
(※もしくはseq_read()が実施することもあるが、基本的にはこれは意識しなくても良い)
ユーティリティ関数の代表例は、seq_printf()です。しかし、seq_printf()自体はコンソールにデータを出力しません。
seq_printf()は内部でvsnprintf()を呼び出します。
void seq_vprintf(struct seq_file *m, const char *f, va_list args)
{
int len;
if (m->count < m->size) {
len = vsnprintf(m->buf + m->count, m->size - m->count, f, args);
if (m->count + len < m->size) {
m->count += len;
return;
}
}
seq_set_overflow(m);
}
EXPORT_SYMBOL(seq_vprintf);
vsnprintf()は以下コメントの通り、メモリバッファへの出力を行います。コンソールへの出力を行いません。
* vsnprintf - Format a string and place it in a buffer
今回の場合、vsnprintf()の書き込み先となるバッファはseqファイルシステムが用意した内部バッファになります。
データの流れはおおよそ以下のとおりです。
主にshow() -- seq_printf()など --> 内部バッファ --- seq_read() ---> ユーザプロセスが渡してきたバッファ
よって、show()では、printk()を使った出力をするのでなく、seq_printf()などのユーティリティ関数を使って内部バッファへの書き込みを行うようにしてください。
なお、ユーティリティ関数については、Documentation/filesystems/seq_file.txt を参考にしてください。
simple系のI/Fについて
seqファイルシステムを使った仮想ファイルの機能でありがちなのは、以下に書いたような簡単な使い方ではないでしょうか。
- イテレータのような特別なデータ構造を必要としない。位置情報だけ受け取ればそれで足りる
- 位置情報について、インデックス的な使い方を想定している。
- next()で位置情報をインクリメントして”次に移る"だけで十分
- show()では、位置情報だけ貰えれば表示対象のデータが何で、それをどう表示すればよいのかわかる
- stop()で、特にやるべき後始末処理はない
そういう場合、いちいちstart(), next(), stop()を書くのは簡単ですが面倒ですね。
そんな人のために、seqファイルシステムにはsingle_open(), single_release()が用意されています。
内部実装を直接見たほうがわかりやすいので、実装を以下に引用します。
これを見ると、以下のことがわかります。
- start(), next(), stop()にはあらかじめ用意された処理が割り当てられる。
- single_open()を使う実装者は、show()を渡す。
int single_open(struct file *file, int (*show)(struct seq_file *, void *),
void *data)
{
struct seq_operations *op = kmalloc(sizeof(*op), GFP_KERNEL);
int res = -ENOMEM;
if (op) {
// start(), next(), stop()は用意してくれる。こちらで用意するのはshow()のみ
op->start = single_start;
op->next = single_next;
op->stop = single_stop;
op->show = show;
res = seq_open(file, op);
if (!res)
((struct seq_file *)file->private_data)->private = data;
else
kfree(op);
}
return res;
}
EXPORT_SYMBOL(single_open);
また、start(), next(), stop()に割り当てられた関数群は以下のとおりです。実に簡潔な処理です。
static void *single_start(struct seq_file *p, loff_t *pos)
{
return NULL + (*pos == 0);
}
static void *single_next(struct seq_file *p, void *v, loff_t *pos)
{
++*pos;
return NULL;
}
static void single_stop(struct seq_file *p, void *v)
{
}
single_open()を使うためには、上位レイヤがopen()したときに呼ばれるコードでsingle_open()が呼ばれるようにします。
例えば、procファイルシステムの場合、proc_create()に渡すfile_operations構造体のopenメンバで渡した関数で、single_open()を呼ぶようにします。
single_open()呼び出し時、実装者が定義したshow()を渡してあげます。さすがに「なんの情報をどのように扱うか」はseqファイルシステムのレベルではわかりませんので、show()は自前で用意します。
使用例としては以下のとおりです。これを見ると使い方がつかめるかな、と思います。
static int virq_debug_open(struct inode *inode, struct file *file)
{
return single_open(file, virq_debug_show, inode->i_private);
}
static const struct file_operations virq_debug_fops = {
// procfs(/proc/irq_domain_mapping)をopen()したときに呼ばれる。
.open = virq_debug_open,
// single_open()を使っていても、seqファイルシステムを使っているので、seq_read, seq_lseekを使うのが無難、というか普通。
.read = seq_read,
.llseek = seq_lseek,
// releaseはsingle_release()で。
.release = single_release,
};
static int __init irq_debugfs_init(void)
{
// procファイルシステムにエントリを登録する際、file_operationを渡し、seqファイルシステムのI/Fが呼ばれるようにする
if (debugfs_create_file("irq_domain_mapping", S_IRUGO, NULL,
NULL, &virq_debug_fops) == NULL)
return -ENOMEM;
return 0;
}