muninに辛くなってfabricでなんやかんやするアプリケーションを作ったりしていたがグラフ描画部分で辛くなり、色々と調べた結果InfluxDBとGrafanaの組み合わせが良さそうだったので、それでいい感じにリソース可視化してみたという内容。
概要
監視サーバーと監視されるサーバー群が存在していて、監視サーバーにInfluxDB、Grafana、Fabricをインストールする。
監視サーバーはFabricで各サーバーにssh接続しメトリックを取得する。取得したメトリックはInfluxDBに保存され、Grafanaで可視化される。という感じ。
Versions
OSはCentOSでやったけどInfluxDBとGrafanaのインストールと起動が違うだけだと思われる。
InfluxDB = 0.8.8(stable)
Grafana = 2.0.1
Fabric = 1.10.1
influxdb-python = 2.2.0
Install & Launch
公式のinstallationがちゃんとしているのでそこをそのまま実行。
InfluxDB
デフォルトだと 8083, 8086, 8090, __8099__番のポートを使うので、必要なら開けておく。
ulimit -n 65536でファイルディスクリプタ数の上限を上げる。
wget http://s3.amazonaws.com/influxdb/influxdb-latest-1.x86_64.rpm
sudo rpm -ivh influxdb-latest-1.x86_64.rpm
sudo service influxdb start
Grafana
デフォルトだと __3000__番のポートを使うので、必要なら開けておく。
wget install https://grafanarel.s3.amazonaws.com/builds/grafana-2.0.2-1.x86_64.rpm
sudo rpm -ivh grafana-2.0.2-1.x86_64.rpm
sudo service grafana-server start
Fabric
各サーバーからメトリクスを取得するのに使用する。各サーバーから数値を取ってきてInfluxDBに保存できるのなら別にFabricじゃなくても可。今はDiamondというツールが良さそうかなーと目星をつけている。
FabricのインストールはPythonのパッケージシステムから。(2.x系のPythonじゃないと動かない)
sudo pip install Fabric
influxdb-python
これもpipでインストールする。Fabricを使用しないならいらない。
sudo pip install influxdb
Setting
InfluxDB、Grafana共にwebインターフェースにアクセスできる。
ユーザーとかは各自色々やってください。
InfluxDB
メトリクスを保存するためのDBを作成する。
http://localhost:8083/にアクセスするとログインを求められるのでuser=root, password=rootでログインする。

ログインするとデータベース一覧が表示される。
各サーバーから取得した計測値を格納するdimensionsというデータベースを新しく作成する。

GraphanaとInfluxDBの接続
http://localhost:3000/にアクセスするとこちらもログインを求められる。デフォルトはuser=admin, password=adminでログイン出来る。

空のダッシュボード。左上のGrafanaマークをクリックするとメニューが開くので、メニュー中のData Sourcesをクリックし、Grafanaのバックエンド設定画面を開く。

Data Sourcesをクリック後、画面中央上のAdd newをクリックしInfluxDB 0.8.xをバックエンドに設定する。urlのポートはapiのポートなので、ブラウザの8083ではなく __8086__を指定する事に注意。Nameは適当でいい。 Databaseは先ほどInfluxDBで作成したdimensionsを設定する。最後にAddをクリックで完了。

これでGrafanaとInfluxDBのつなぎ込みが完了した。
Fabric
各サーバーからメトリクスを取得しInfluxDBに保存する。詳しい使い方は他のページで見る感じでお願いします。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from fabric.api import env, run
from influxdb.influxdb08 import InfluxDBClient
import re
env.hosts = ["server01.hoge.jp"]
env.key_filename = ["~/.ssh/server01_rsa"]
env.user = "myuser"
client = InfluxDBClient('localhost', 8086, 'root', 'root', 'dimensions')
def loadaverage():
match = re.search(r"load averages?:\s+(\d+\.\d+),\s+(\d+\.\d+),\s+(\d+\.\d+)", run("uptime"))
min1 = float(match.group(1))
min5 = float(match.group(2))
min15 = float(match.group(3))
client.write_points([
{
"name": "loadaverage_1min",
"columns": ["value"],
"points": [[min1]]
},
{
"name": "loadaverage_5min",
"columns": ["value"],
"points": [[min5]]
},
{
"name": "loadaverage_15min",
"columns": ["value"],
"points": [[min15]]
}
])
こんな感じのfabfileを用意し、crontabで毎分実行するようにする。
*/1 * * * * fab loadaverage
数分経ってからInfluxDBのdimensions DBのwebインターフェースからlist seriesとクエリを投げて3つseriesが返ってきたらok。ちなみにseriesとはRDBにおけるtableみたいなもの。

Grafanaで可視化
ダッシュボードのメニューからNewを選択する。

新しいダッシュボードに飛ばされるので、緑色のところからメニューを開いて新規グラフを作成する。

グラフのタイトル(no title(click here)となっている所)をクリックしeditでグラフの設定画面を開く。
seriesにloadaverage_1minと入力するとグラフが出てくる(!)。group by timeを1mに設定。
後はAdd queryを押してクエリを追加し、同じようにloadaverage_5minとloadaverage_15minの設定を追加する。
aliasとかグラフタイトルとかをいい感じに設定するとさらに良い。ちなみにseries名をドット区切りで付けていればaliasでドットで区切ったそれぞれのフィールドが$0, $1...に代入されるので変数が使える。
この辺、fork元のkibanaより設定がしやすいような気がする(設定もリアルタイムに反映されるし)。

右上の時間表示からグラフに表示する最大時間とリアルタイム更新の時間を設定できる。最後に保存をクリックすればダッシュボードが完成する。
後は煮るなり焼くなりどうぞという感じ。
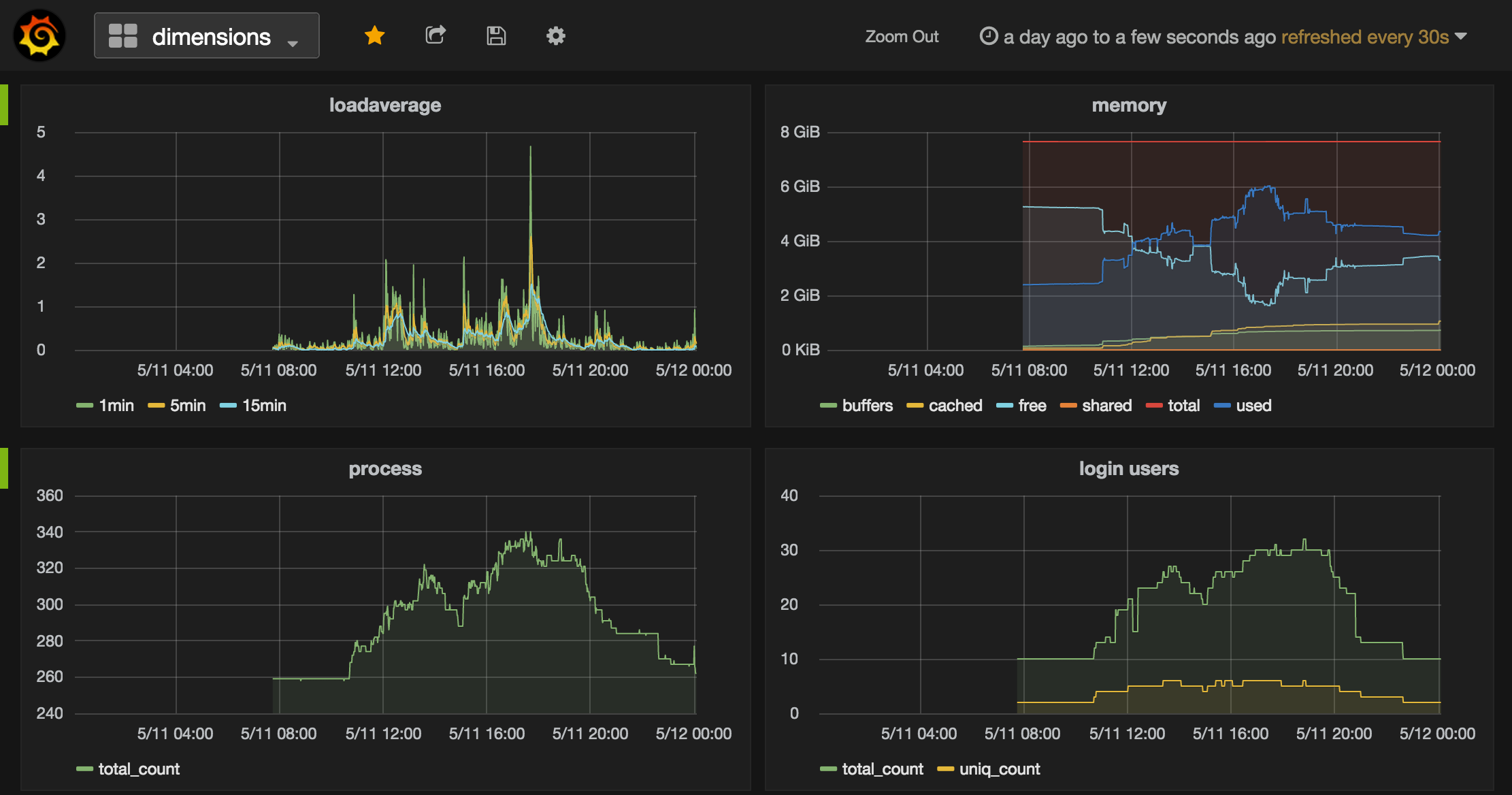
まとめ
個人的に作ってて辛かったメトリクスデータの時系列管理とグラフ化がInfluxDBとGrafanaで非常に簡単に出来た。
InfluxDBの1.0リリースが楽しみだけど0.8と0.9で互換性があまりないっぽいのでつらそう。
Grafanaはkibanaのクローンということで見た目のかっこよさはそのままに、操作性がさらに良くダッシュボードが作れるようになってて最高。また、Kibanaで可視化したいだけなのにElasticsearch入れないといけないのが結構辛かったけれど、Grafanaはバックエンドの種類を選べるのが地味に嬉しい。
FabricもDiamondも競合するわけでは無いので、loadaverageとか一般的なメトリクスはDiamond、もっとアプリケーション寄りなメトリクスだったらFabricというように使い分けるのがよさそう。
ダッシュボードは今回書いたグラフ表示に加えて、Single statもあるので、現在の状態を表示するだけ、みたいな事も出来る。アノテーションを付けてグラフのここはこの状態だったみたいな事も出来るっぽい。