[ニュースメディアWWD JAPAN.comを支えるSPA+Aurora+サーバーレス, サーバーレスの現実と夢と今 にも同様のトピックをまとめました]
WordPress + MovableType で運用されていた WWD JAPAN.com というウェブメディアをサーバーレスに置き換えました。
2016 年 1 月からモックアップの開発を始めて、9 月のローンチまでに大部分の古典的リソースを捨て、トラフィックの影響を受けないサーバーレスなアーキテクチャへと刷新できました。
TL;DR
AWS を利用したサーバーレスアーキテクチャは以下のような構成になりました。
- リクエストを受け付けるのは CloudFront
- フロントエンドは S3 で HTML/JS/CSS
- バックエンドは Lambda で Node.js
- 管理画面専用に EC2 で WordPress( PHP )
旧構成と新構成を図にすると、次のようになります。
旧構成
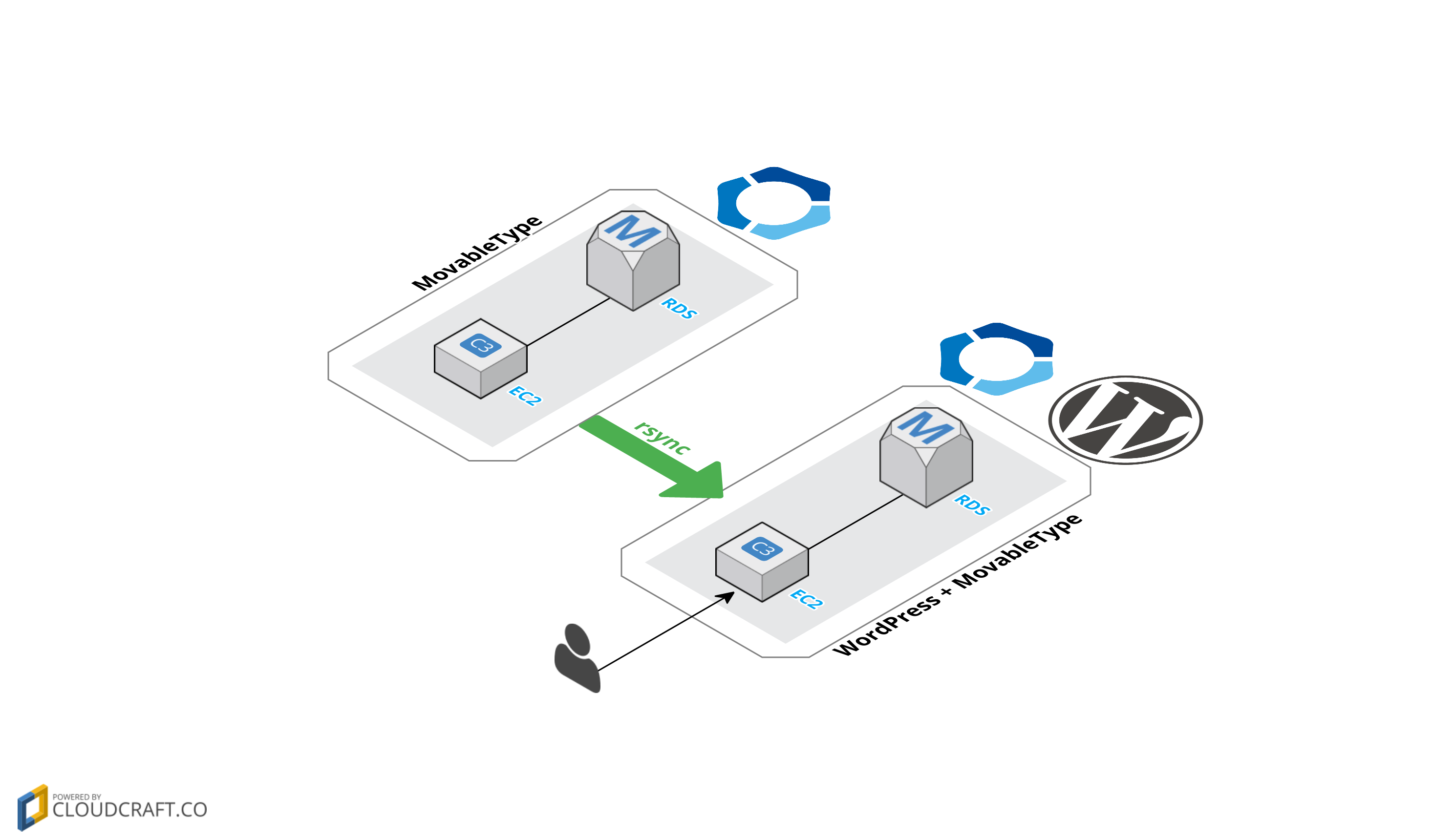
私がジョインする前から、苦しい事情があって MovableType と WordPress が混在していました。
MovableType が生成した静的ファイルを WordPress 用の EC2 に rsync していて、大量の静的ファイルが EC2 に追加され続ける構成のためオートスケーリングもできない状態でした。
また、2 つの CMS が混在するために複雑化したソースコードが、技術的負債として積もり続けていました。
新構成
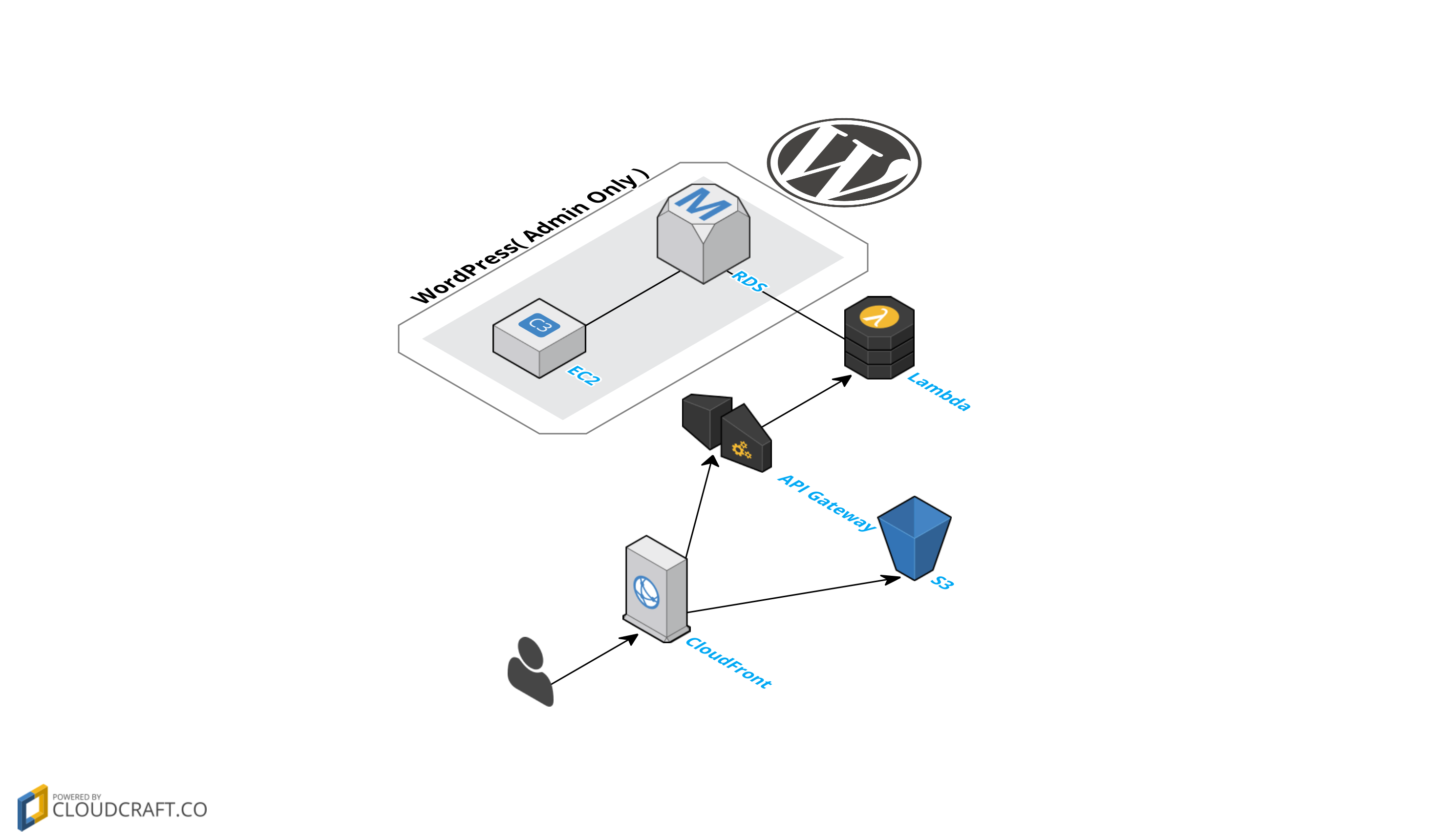
まず MovableType の廃止と、フロントエンドを S3 がレスポンスするようになりました。
統合された CMS( WordPress ) は管理画面専用として利用されます。ここだけ EC2 なのでサーバーレスではありませんが、管理画面専用ですのでフロントエンドとは切り離されています。
フロントエンドは単純な JavaScript アプリケーションとなったため、もはや EC2 でホスティングする必要はなくなり、S3 に置くだけで動作します。
データの取得は Lambda によって行われ、API Gateway が API 化しています。詳しくは後述しますが、API Gateway のキャッシュを有効にするとコストがかかるため、API Gateway をオリジンとした CloudFront へのリクエストをするようにしています。
データベースはマルチ AZ の Aurora です。データベースのサーバーレス化は執筆時点では見当たりませんでした。Aurora はそのなかでもフルマネージドに近い可用性を持っていたため、Aurora を採用しました。
移行作業
ここからは今回のサーバーレス移行にあたって実施したことです。
CMS の統合
正直この作業が必要なのは特殊なケースだと思いますが、もっとも手を焼いた部分でもあります。
まず MovableType のデータを CSV エクスポートして、WordPress に移行します。じつは WordPress 自体もカスタムフィールドやマルチサイトが乱立していてカオスな状態でした。そのため旧 WordPress から新 WordPress への移行も行うことになりました。
新しい WordPress は管理画面専用となるので、表示に関わる一切のカスタムフィールドを廃止しました。
管理画面専用となることが分かっているとほぼ初期状態の WordPress で要件を満たしてしまいます。もちろんテーマの開発も不要です。追加したのはニュースアプリ向けの RSS テンプレートだけで、他はプラグインです。また、どう分類していいか分からないカテゴリの代わりにタグを利用しました。
手を焼いたというのはデータの整形です。
とくに MovableType と WordPress の記事形式の差異や、旧 WordPress のマルチサイトごとの差異を吸収して、なおかつ本来の WordPress 標準に沿った形式に整形するのは骨の折れる作業でした。とはいえ、ほとんど汎用性のない特殊な内容なのが残念です。
API の開発
フロントエンドが JavaScript アプリケーションになるということは、WordPress のデータは API 経由で取得することになります。
WordPress はプラグインの導入や wordpress.com との接続を行えばそれだけで API 化することが可能です。
しかし、今回の目的はサーバーレスでした。EC2 で動作している WordPress から API をレスポンスさせることはできません。 wordpress.com による API は詳しい仕組みが分からなかったのですが、どこかで EC2 との疎通を行っていることは明白ですし、そもそもレスポンスが遅かったため断念しました。
そこで、今回は Lambda から WordPress のデータベースへ接続するという方法をとりました。
npm のライブラリのなかにはいくつか WordPress 用のものがありましたが、いずれも WordPress API のラッパーのようです。それではせっかくのサーバーレスが台無しなので、squel を使って SQL を組み立てて直接発行することにしました。
WordPress API のラッパーではなく WordPress の組み込み関数と同じ SQL を投げるライブラリがあれば、WordPress のサーバーレス化が前進する気もしますね。( つくる...? )
ユーザー認証
サーバーレスは ステートレス でもあるため、ユーザー認証の仕組みにセッションや Cookie が使えません。Lambda はリクエストがなくなると自動的に消滅するからです。
認証済みのユーザーかどうかの判定は、API リクエストにトークンを付与する形で行いました。トークンは JSON Web Token で暗号化された JSON を利用します。
JSON Web Token を使うことで、トークンのなかに必要なユーザー情報を含めることができ、認証の際のデータベースアクセスを最小化できるという効果もあります。
SPA の開発
フロントエンドはすべてを JavaScript で表現する SPA 形式になります。
SPA にすることで、フロントエンドの構成は非常にシンプルになります。リクエストがなんだろうと S3 に置いた index.html を返却するだけで動きます。
今回はその実装に Riot.js を採用しました。Riot.js は他の仮想 DOM ライブラリにはないいくつかの特徴をもっています。詳しくは こちらの記事「Riot.jsでフロントエンドの複雑さに反乱するときがやってきた」 に書きました。
Riot.js ではコンポーネントのことをカスタムタグと呼びますが、そのカスタムタグの数は合計で 161 個になりました。これが多いか少ないかは分からないのですが、カスタムタグの分類を Atomic Design に似た独自ルールを作ったので、見通しはよくなりました。
その分類は以下のようにしています。
- Screen ( 画面自体を担う。URL によってマウントされるタグが決まる )
- Area ( レイアウト上の区画を担う )
- Widget ( ひとまとまりの機能の集合を担う )
- Component ( 単機能を担う )
- Module ( 文字列やデータの出力だけを担う )
これは Atomic Design を知る前に考えたのですが、結果として Atomic Design に近いものになりました。個人的にはこっちのほうが直感的な呼称だなと思って使い続けています。
Flux 実装
SPA を開発しているとコンポーネント毎のデータの受け渡しが複雑になってきます。
そこに秩序をもたらしたのが Flux や Redux などのライブラリですが、Obseriot というオブザーバーパターンライブラリを作り、それを全面的に利用しています。
Obseriot は Riot.js とともに開発されている riot-obserbable をラップしたライブラリです。
テスト
テストは karma + mocha + expect.js で書いています。
残念なことに、スケジュールの都合でテストが中途半端な状態がしばらく続いていました。
しかし追加の機能開発の前にテストがないとあっという間に開発効率が悪くなっていくので、今は全コンポーネントのユニットテストを書いているところです。ユニットテストができたあとは、結合テストとシナリオテストも書くつもりです。
構成
フロントエンドのディレクトリ( リポジトリ )構成は、以下のようになりました。
src/-
tag/- 分類されたコンポーネント -
js/- Action や Store のほかコンポーネントの Mixin -
scss/- アプリケーションのグローバルで使う SCSS -
assets/- フォントや画像 test/-
tag/- ユニットテスト index.html
favicon.ico など細かいファイルももちろんありますが、基本的には上記のような構成です。
すべての JavaScript は Rollup でバンドルして、Git 管理外にある dist ディレクトリに置いておきます。同じく SCSS もビルドして dist に置きます。アセットはビルド不要ですが、他のファイルに準じて dist に複製しています。
サーバーサイドレンダリング
SPA はすべてが JavaScript で動的に描画されるので、Google クローラーなどのボットが HTML を解釈することができません。
そこでサーバーサイドレンダリング( SSR )を行う必要があるのですが、一時的な技術背景のためだけの対応をなるべく避けたいという個人的ポリシーから、SSR はボット向けだけという限定的な対応をしています。
ニュースメディアという性質上、未知のスクレイピング依存なサービスによって第 3 者からの評価を受けることがあり、すべてのリクエストに対して SSR しています。
Lambda で PhantomJS を実行し、PhantomJS のサンドボックス内で MutationObserver による DOM 監視を行なうことで HTML の完成を確認するという手法を用いています。
そのため、SSR を意識した開発をすることはありません。
デプロイ
GitLab CI によって、master ブランチが更新されたら自動的にプロダクション用の S3 にデプロイされるようにしました。SPA だと S3 を更新するだけなのでデプロイも楽です。
また、stage ブランチが更新されたらステージングバケットへ、develop ブランチが更新されたら開発バケットにデプロイされます。
サーバーレスの罠
AWS におけるサーバーレス化でつまづいた点がいくつかあります。
API Gateway のキャッシュを使ってはいけない
API Gateway は同じリクエストをキャッシュして、キャッシュヒットした場合はより高速にレスポンスできる機能があります。
API Gateway 自体は こちらの料金表 の「データ転送費用」にあるように従量課金ですが、キャッシュする場合はキャッシュの最大サイズに応じた 時間課金 になります。
たとえばキャッシュを最大 237GB まで設定すると、実際のキャッシュが 0 でも 237GB 分の時間単価 3.800 USD で請求されるということです。
このことは料金表の「キャッシュ」の項目に書いてあるのですが、まさか時間課金だなんて EC2 みたいな計算の仕方をしないだろうとばかり思っていました。しっかり読んでいなかった私がいけないのですが、API Gateway のバックにあるのは CloudFront だと聞いていたので、ならば転送した分だけの従量課金だと考えてしまいます。
とはいえ、キャッシュをせず毎回データベースにクエリを投げるのはあまりに非効率です。ですから、API Gateway ではキャッシュを無効して、API Gateway をオリジンにした CloudFront を API のエンドポイントとして使うことにしました。キャッシュは CloudFront 側で生成されます。
VPC 内の Lambda は初回だけ遅い
Lambda は負荷に耐えられるあいだはひとつのコンテナを再利用して、負荷が上がってくると自動的に新たなコンテナを作成します。
Lambda が呼び出されていない時間が続くとコンテナが削除されて、次の 1 回目の呼び出しでコンテナが再作成されます。このとき、Lambda が VPC 内にあると、通常のコンテナ作成の遅延よりもだいぶ大きな遅延が発生します。私が知る限りでは 10 秒前後かかりました。
理由としては ENI の確立のために遅延が大きくなるようです。
しかし同じ VPC 内にある Lambda がいずれかひとつ呼び出されていれば、この遅延は起きません。そこで、なにもしない VPC Lambda 関数を 1 分毎にスケジューリング実行してホットスタンバイする ことで問題を解決できました。
CloudFront ではボット/非ボットの振り分けができない
エンドユーザー向けには S3 上の CloudFront ではユーザーエージェントによるオリジンの振り分けができません。index.html 、ボット向けにはサーバーサイドレンダリング( SSR )した結果を返していると先述しましたが、
今回のサービスではボット/非ボットの振り分けはしていませんが、CloudFront で振り分けができないことは事実です。
振り分けをするためには API Gateway のプロキシ統合 が便利です。
プロキシ統合によってリクエストに関する全ての情報( e.g, パスやヘッダなど )を Lambda に転送できます。あとは Lambda のなかで適宜処理してください。
これから
ここまでほとんどの構成を AWS で構築してきました。
サーバーレスとは端的に言えばフルマネージドサービスを使うということですが、これを突き詰めるとベンダーロックインを強いられることになる、ということです。
フロントエンドにおいては S3 の静的ファイルなのでベンダーロックインはありませんが、たとえば Lambda です。Lambda で動くように書いたモジュールは、 Lambda でないと動かない モジュールにもなります。
ベンダーロックインされたソースコードは、テストもしづらくなります。そのままだとローカルでは動かないからです。ローカルにベンダーの環境を再現する必要があり、ハイコンテクストな開発をすることになります。
私はいま Now という新しい PaaS に関心があります。
Now は Node.js で作られたアプリケーションを単純に npm start してホストするだけのサービスです。開発者はローカルで npm start するときと同じように開発すれば、それがそのままリモートでも動きます。
また、now コマンドひとつでデプロイができるという、アプリケーションの開発に集中できるシンプルさが特徴です。その now パッケージすらアプリケーションには必要ありません。now は開発環境にグローバルインストールしておけばいいだけで、自分の package.json を汚すことはありません。つまり、ただのデプロイ支援ツールとしてのみ振る舞うのです。
Now については こちらの記事「Now でクラウドの複雑さから解放されよう、今すぐに」 に詳しく書きました。
このようにアプリケーションにコンテクストを要求しない、シンプルなサーバーレスへのニーズが今後高まるのではないでしょうか。
ただしデータベースは持っていないので、データベースだけ AWS などに置いておく必要がありそうです。
開発メンバー
このプロジェクトの開発は、API の開発や CMS のデータ整形など主にバックエンドの開発をしてくれた開発者が 1 名と、SPA の開発などフロントエンドの開発を私が担当したので、計 2 名のメンバーです。
今も絶賛募集中ですので、ご興味お持ちの方は私までメール( hiroyuki.aggre@gmail.com )をいただけたら嬉しいです!