お見苦しいところ失礼します。やっとこの手の記事を書くのにも慣れてきたと思いたい頃です。今回はやっと題名にあるPGXを動かしてみようと思います。
※SQLのタグをつけていますがあくまでもSQLライクのクエリ言語です!!
今回やること
- ヒーローのネットワークの解析(デモその①)
「前回の記事」にある参考資料中のデモを行います。
①データを入手する
Exposedata.comにアクセスしてウェブアーカイブの「Hero Social Network Data」からリンクを押してCSV形式のデータを入手します(データが入手できない場合は参考スライドの「Hero Social Network Data」をクリックすれば大丈夫です)。
$ more hero-network.csv
キャラクターがノード、同時に登場しているキャラクターがカンマ区切りで対にして表示されていると思います。
②グラフのロード
手順1で入手したデータは、そのままでは使うことが出来ません、、なのでPGXに、ちゃんと解析できるファイルだ!と認識してもらうようにそのデータをいろいろと定義づける必要があります。これが今回はJSONに当たります。JSONが分からない人はここを見てみてください(難しいですね!)
$ vim hero-network.csv.json
{
"uri": "hero-network.csv" #リソースを提供するためにURIを提示(ルールを決める?)
, "format": "edge-list" #以下は順に形式、ノード番号、区切り方をデータ型で指定
, "node_id_type": "string"
, "separator": ","
}
分かっているとは思いますが、念のため。記述コマンドで書き終えたら、Esc + :wqできちんと記録しましょう。
上のファイルをサーバー内に記述できたらPGXシェルを起動して、このファイルを指定し、PGXシェル内にグラフをロードします。
pgx> G = session.readGraphWithProperties("入れたディレクトリまでのパス/hero-network.csv.json").undirect()

入れたらグラフ名(name)、ノード数(N)、エッジ数(E)、つながりの数(created)が表示されると思います。
あとは前回の記事に載せた参考スライドのとおりに入力すれば同様の結果が得られると思います!(ver2.4.1ではエッジ数がうまく表示されないエラーがあるため注意)
このスライド中では演算的な処理として、次数中心性、ページランク、媒介中心性のアルゴリズムを実行してみています。また、これらと組み合わせて参照型の処理を併用したものも行っています。ここが便利なところみたいです!Network Biology分野でも使えそう⋯?![]()
- 路線ネットワーク(デモその②)
①データを入手する
参考のとおりに駅データ.jpへアクセスし、簡単な会員登録をして、駅データ、接続駅データ、路線csvデータを入手します。これを路線データとして~/rail/csvなどといった分かりやすいディレクトリに入れておきましょう。(入れ方はSFTP転送などご自由に!)
駅データはノード、ノードプロパティを示しています(ノードid, 駅名, 住所etc...)
接続駅データはエッジを示しています。(エッジid, 接続駅①, 接続駅②)
路線データはエッジプロパティを示しています。(エッジid, 事業者データid, 路線名etc...)
②データの加工
さて、私はこれでいよいよ分析できる!と思っていました。しかし、データがあるだけじゃ分析しようにも出来ないことを知りました⋯。そこで、データを分析しやすいよう加工する必要があることを知りました。たしかに、先ほど書いたエッジのプロパティを見ても、例えば事業者idは今回の分析に必要ありません。それではやってみます。
まずデータを必要なものに絞り込むよう加工するのですが、**ここでシェルスクリプトを使います。**シェルスクリプトは貝殻から名前が由来しているそうですね。。
$ vim create_edgelist.sh
# !/bin/bash
sort -t ',' -k 1 csv/station20170403free.csv > station.csv
sort -t ',' -k 1 csv/line20170403free.csv > line.csv
sort -t ',' -k 2 csv/join20170403.csv > join01.csv
join -t ',' join01.csv station.csv -1 2 -2 1 -o 1.1,2.2,1.3 > join02.csv
sort -t ',' -k 3 join02.csv > join03.csv
join -t ',' join03.csv station.csv -1 3 -2 1 -o 1.1,1.2,2.2 > join04.csv
sort -t ',' -k 1 join04.csv > join05.csv
join -t ',' join05.csv line.csv -1 1 -2 1 -o 2.3,1.2,1.3 > join06.csv
cat station.csv | awk -v FS=',' -v OFS=',' '{if (NR != 1) print $2, "*"}' | sort |
uniq > station_uniq.csv
join -t ',' station_uniq.csv station.csv -1 1 -2 1 -o 1.1,1.2,2.3 > rail.csv
cat join06.csv | awk -v FS=',' -v OFS=',' '{print $2, $3, $1, "1"}' >> rail.csv
rm station*.csv
rm line.csv
rm join*.csv
分からないコマンドについては各自調べてもらえば良いと思います!(ちなみに私は全て調べましたが完全に理解しきれていません⋯)必要な部分を抜き出した(sort)ファイル同士を結合(join)し、処理(awk)するといった感じです。
このシェルスクリプトを実行するとrail.csvというファイルが出来ると思います。
$ sh create_edgelist.sh
これにより出来たrail.csvを
$ more rail.csv
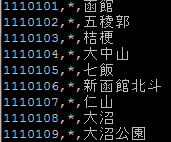
で見てみます。データがカラム表示となっていますね。まずノードのデータがあって、
node ID, *(ノードを認識させるための記号), 駅名
という並びになっています。
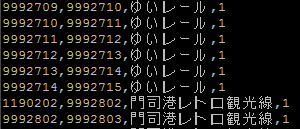
また、このファイルの後半はエッジのデータにあたり、
source node ID, destination node ID, 路線名, score
という並びになっています。(scoreは最短経路の探索に必要です。今回は全部1としているそうです!)
③グラフのロード
グラフをロードするための情報をJSONで記述します。
$ vim rail.csv.json
{
"uri": "rail.csv" #以下はグラフの型を示すもの("プロパティ名":"データ型")
, "format": "edge_list"
, "node_id_type": "integer"
, "vertex_props":[ #ノード
{"name":"name", "type":"string"}
]
, "edge_props":[ #エッジ
{"name":"name", "type":"string"}
, {"name":"score", "type":"double"}
]
, "separator": ","
}
JSONファイルやシェルを書いたファイルは、データを入れてあるディレクトリとは別の場所に保存しておきましょう。
pgxシェルを起動して、グラフをロードします。
pgx> G = session.readGraphWithProperties("rail/rail.csv.json")
このグラフは現在、有向な(向きがある)状態なので、参照型の処理を行うとそれぞれの向きの路線が表示されます。
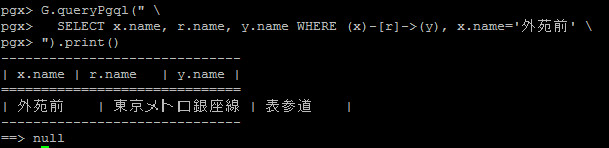
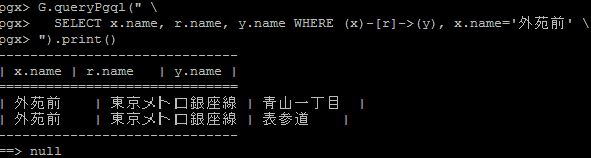
pgx> G.queryPgql(" \
pgx> SELECT x.name, r.name, y.name WHERE (x)-[r]->(y), x.name='外苑前' \
pgx> ").print()
結果
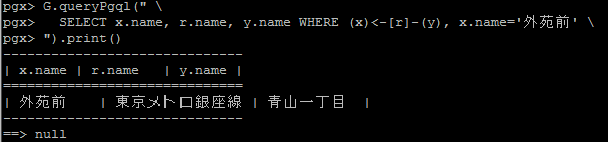
pgx> G.queryPgql(" \
pgx> SELECT x.name, r.name, y.name WHERE (x)<-[r]-(y), x.name='外苑前' \
pgx> ").print()
結果
なお路線には上下線があるので、このデモでは無向のグラフにしています。
pgx> G = G.undirect()
この状態だと、さっきと同様のクエリを入力すると上下線の駅が出力されます。
結果
参考資料ではこのあと経路探索の参照型処理を行い、その後はヒーローのネットワークでも用いた演算型処理である「次数中心性」、「ページランク」、「媒介中心性」、また連結成分(WCC)、最短経路を求めています。是非やってみてください!
感想
参照型のクエリについて、(x)--()-->(y)のように、矢印の方向などを示すなどかなり直感的に入力できるんだなと感じました。また、私はこの元となっているであろうSQLを全然触ったことがないため、これから触っていこうと思います…!
最後までご覧下さってありがとうございました!